Bivariate plots provide visualization of two variables. If we consider categorical and numeric as two different variable types, we have three different types of bivariate plots depending on the combination of variable types: categorical-categorical, numeric-categorical, and numeric-numeric.
If both variables are categorical, we generally are not plotting them, but instead may construct a contingency table. If one variable is numeric and the other is categorical, we can utilize the univariate plots discussed previously, but create one of those plots for each value of the categorical variable. If both variables are numeric, then we typically construct scatterplots.
library("tidyverse")
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
theme_set(theme_bw()) # sets the default theme
15.1 Categorical-categorical
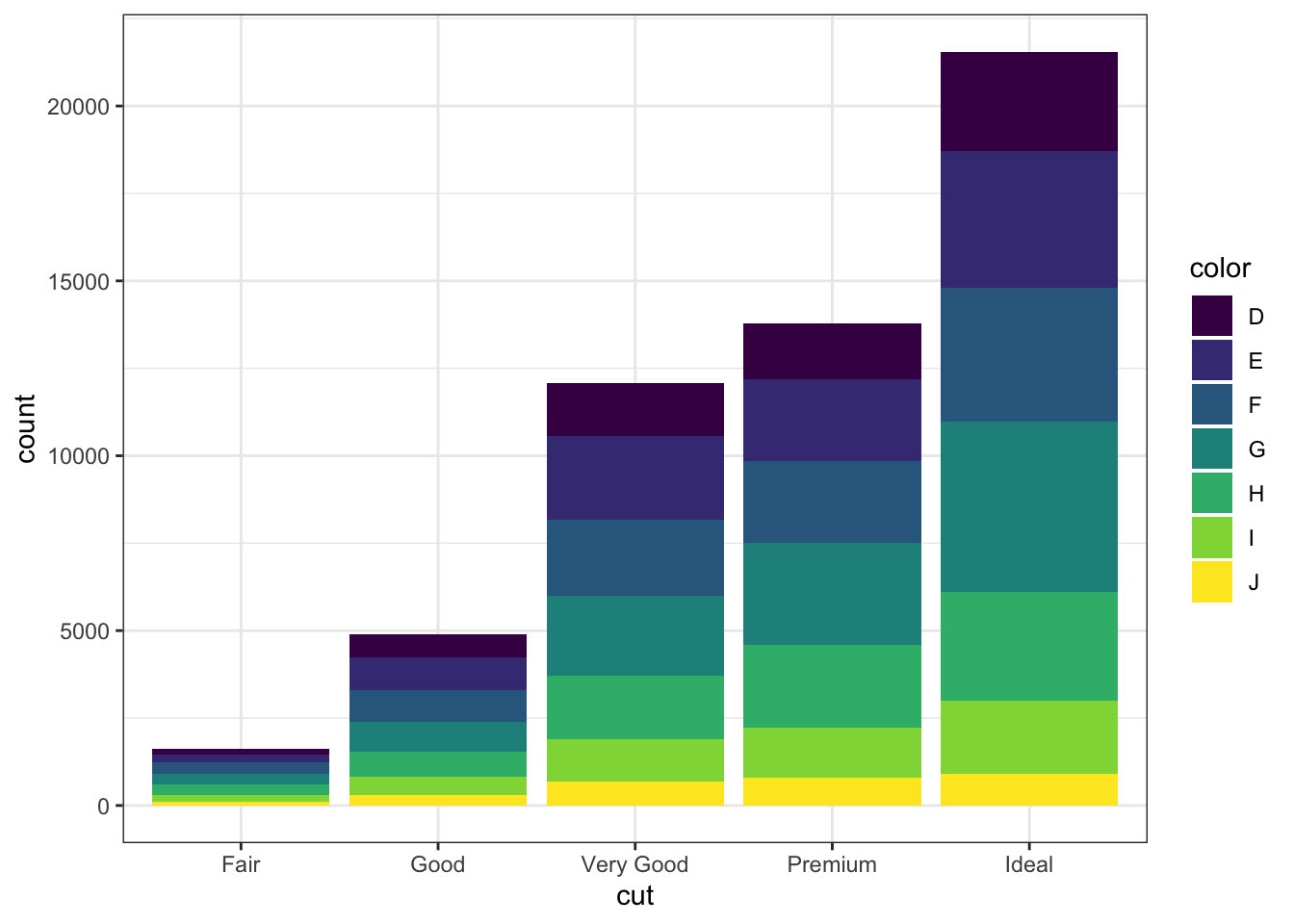
We can utilize multiple bar charts to visualize two categorical variables. By default, the bar charts will be stacked on top of on another.
# Bar chartggplot(data = diamonds) +geom_bar(mapping =aes(x = cut, fill = color))
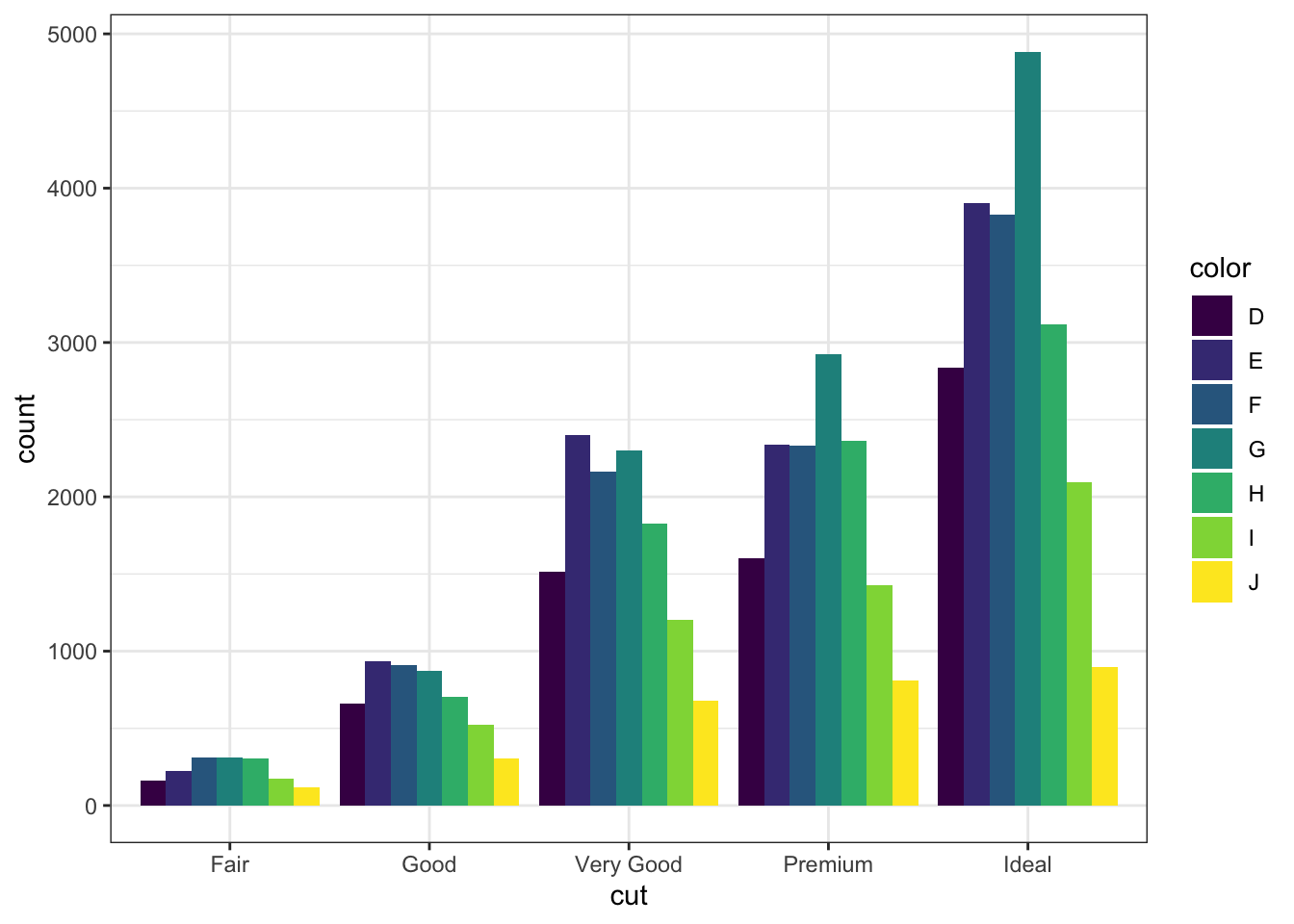
Alternatively, we can unstack them using dodge.
# Bar chart with dodgeggplot(data = diamonds) +geom_bar(mapping =aes(x = cut, fill = color),position ="dodge")
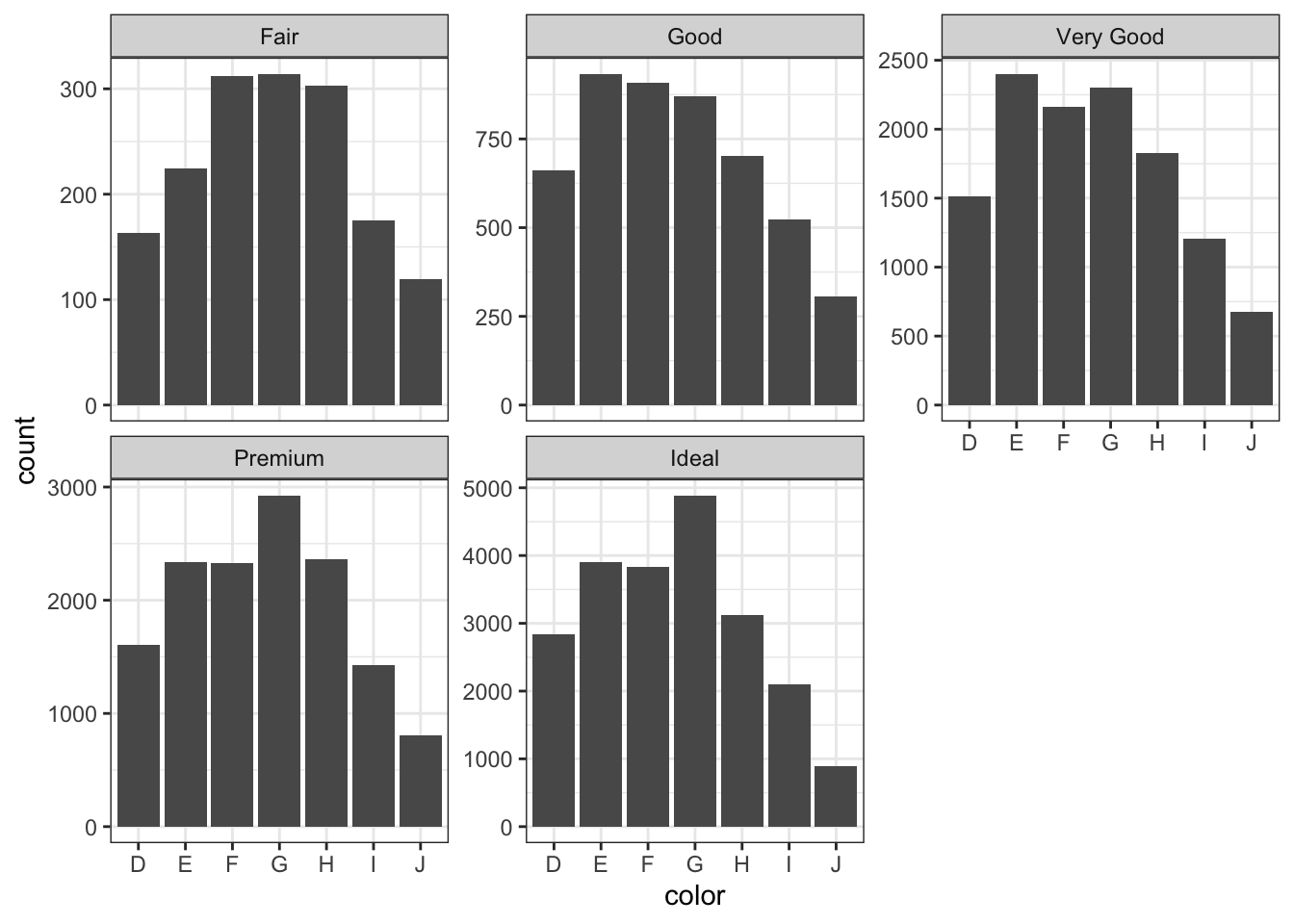
Or we can use facets
# Barchart with facetsggplot(data = diamonds) +geom_bar(mapping =aes(x = color)) +facet_wrap(~cut,scales ="free_y") # so you can see 'Fair'
15.2 Categorical-numeric
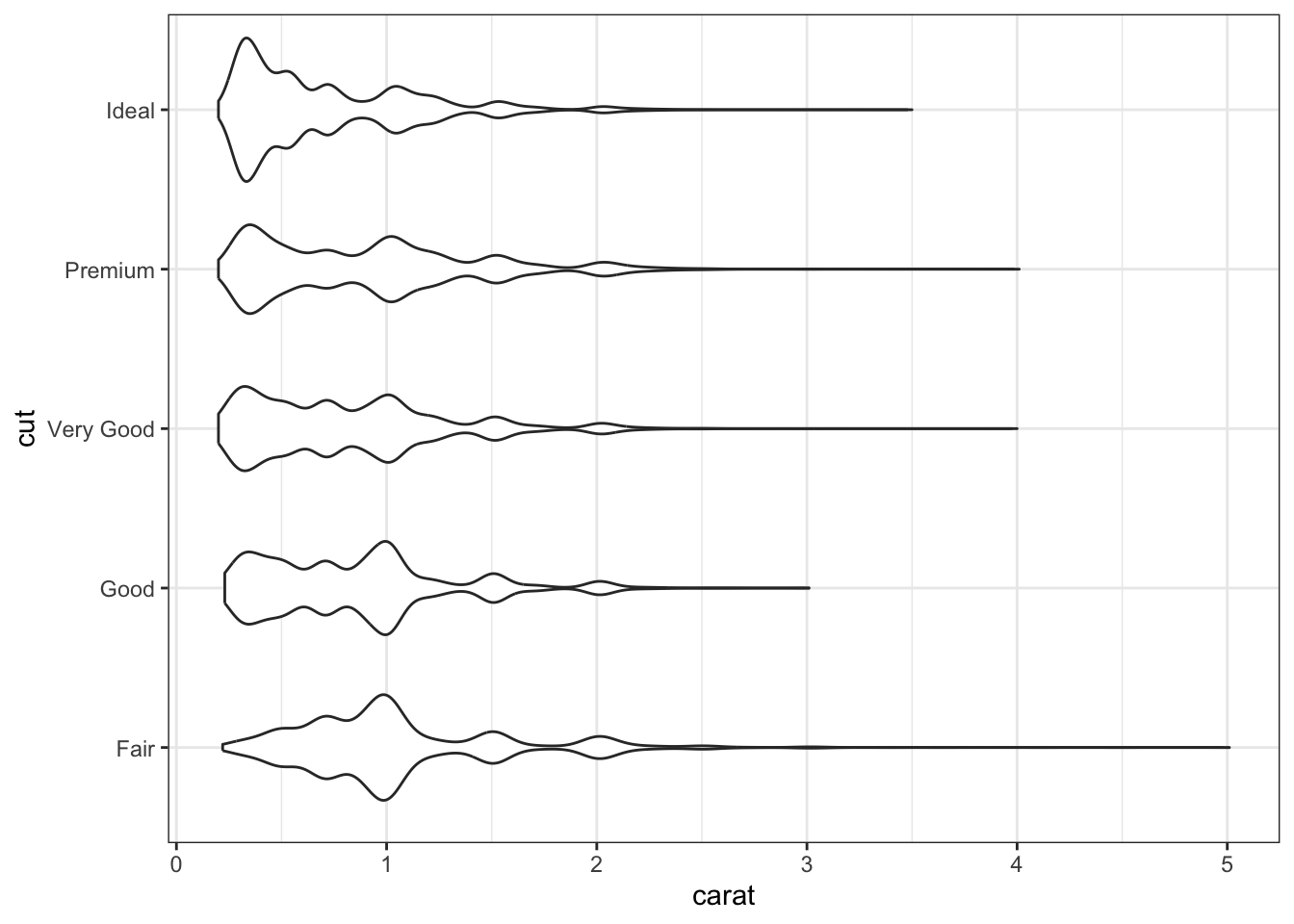
When one variable is continuous and the other is categorical, we can utilize the univariate plots previously discussed including boxplots, histograms, density plots, violin plots, and scatterplots.
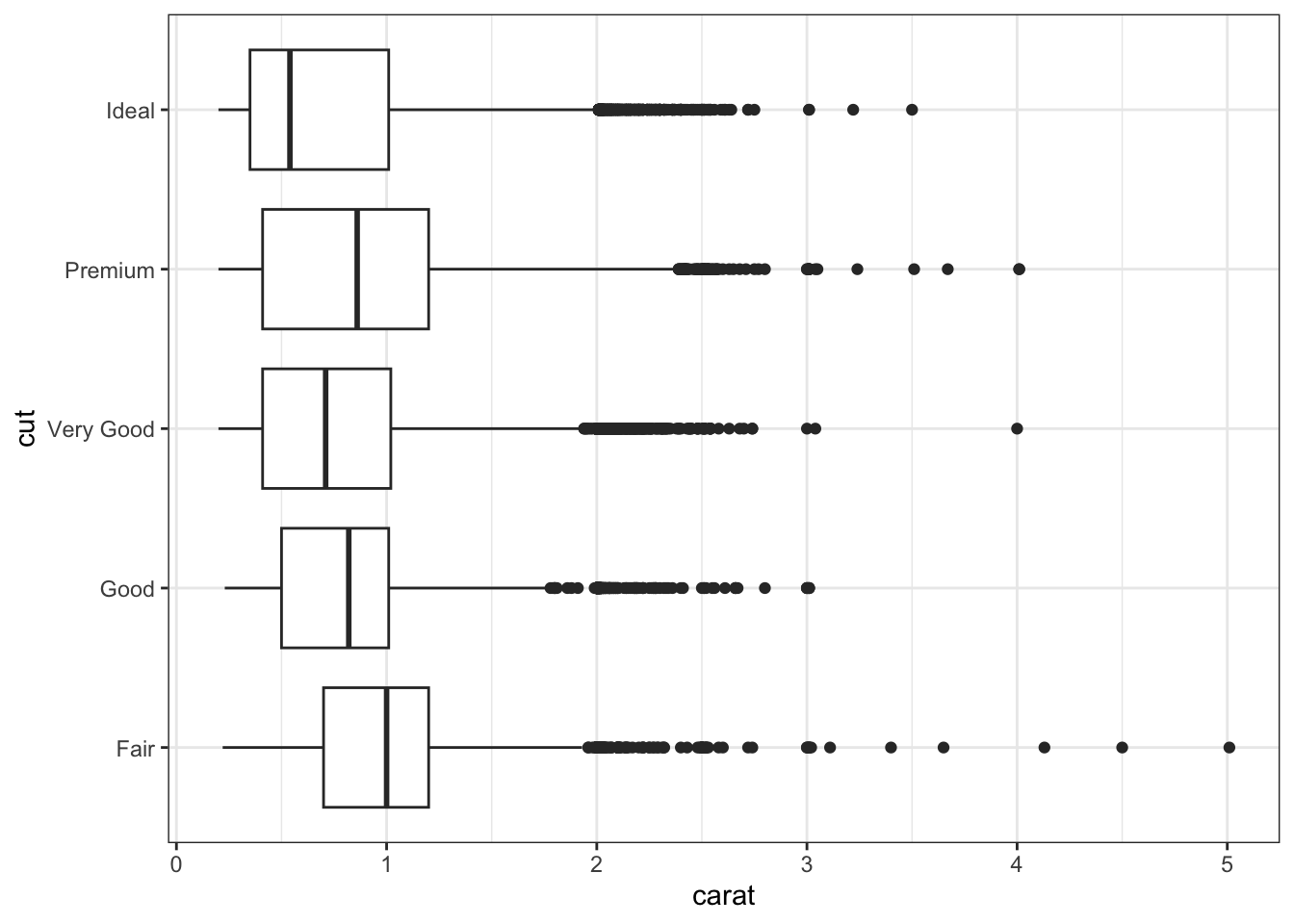
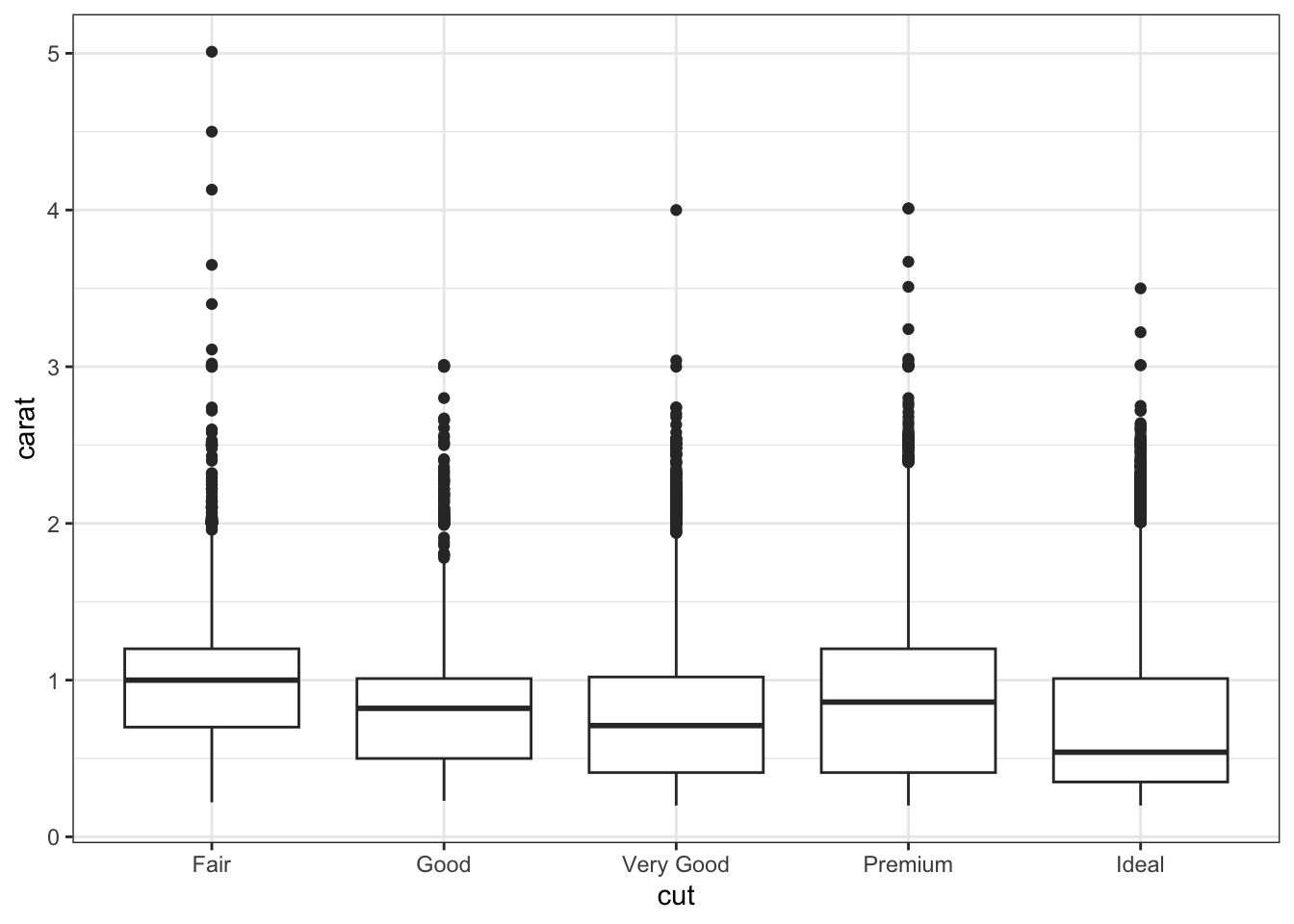
15.2.1 Boxplot
Here is an example of utilizing a boxplot with a categorical variable.
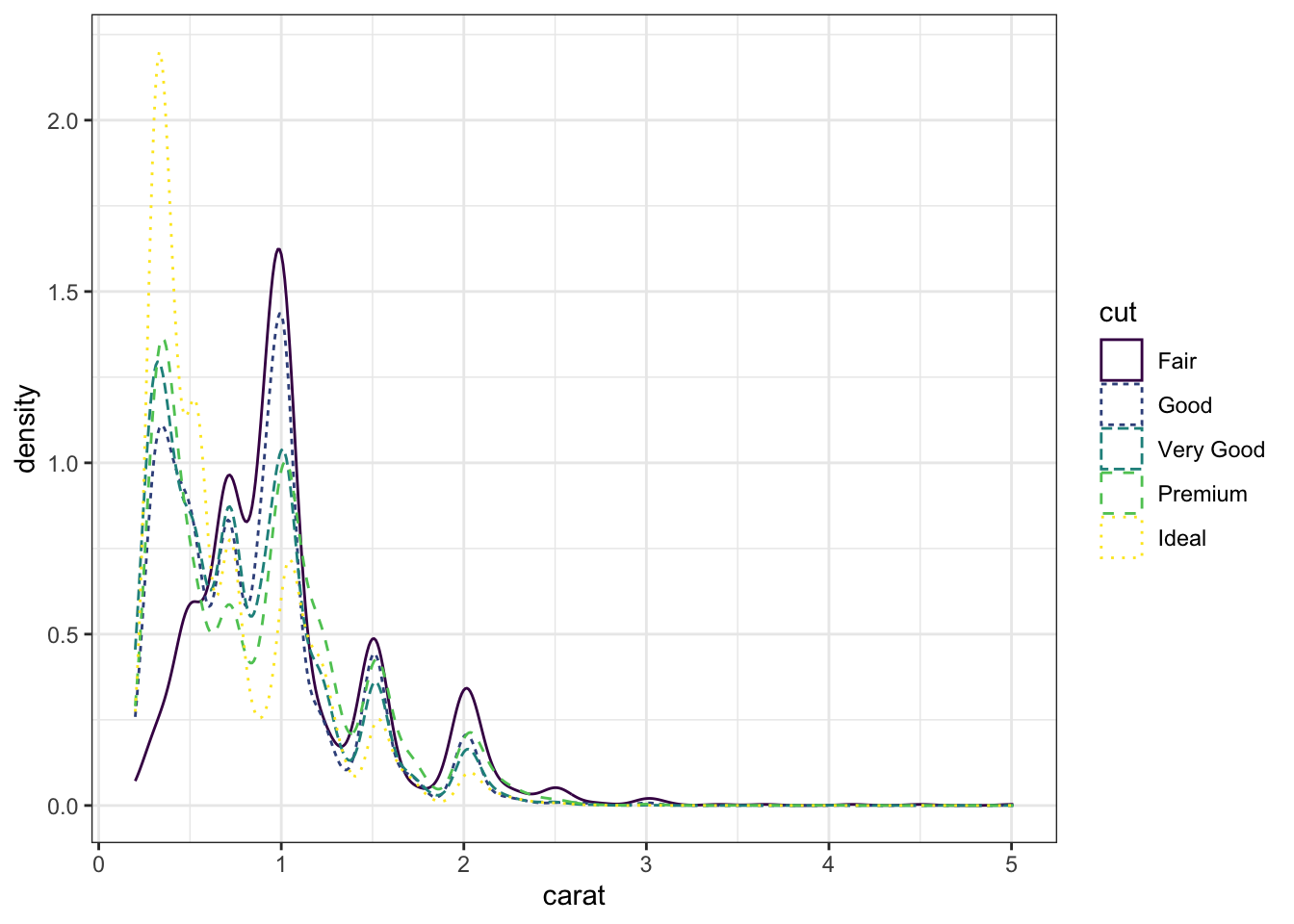
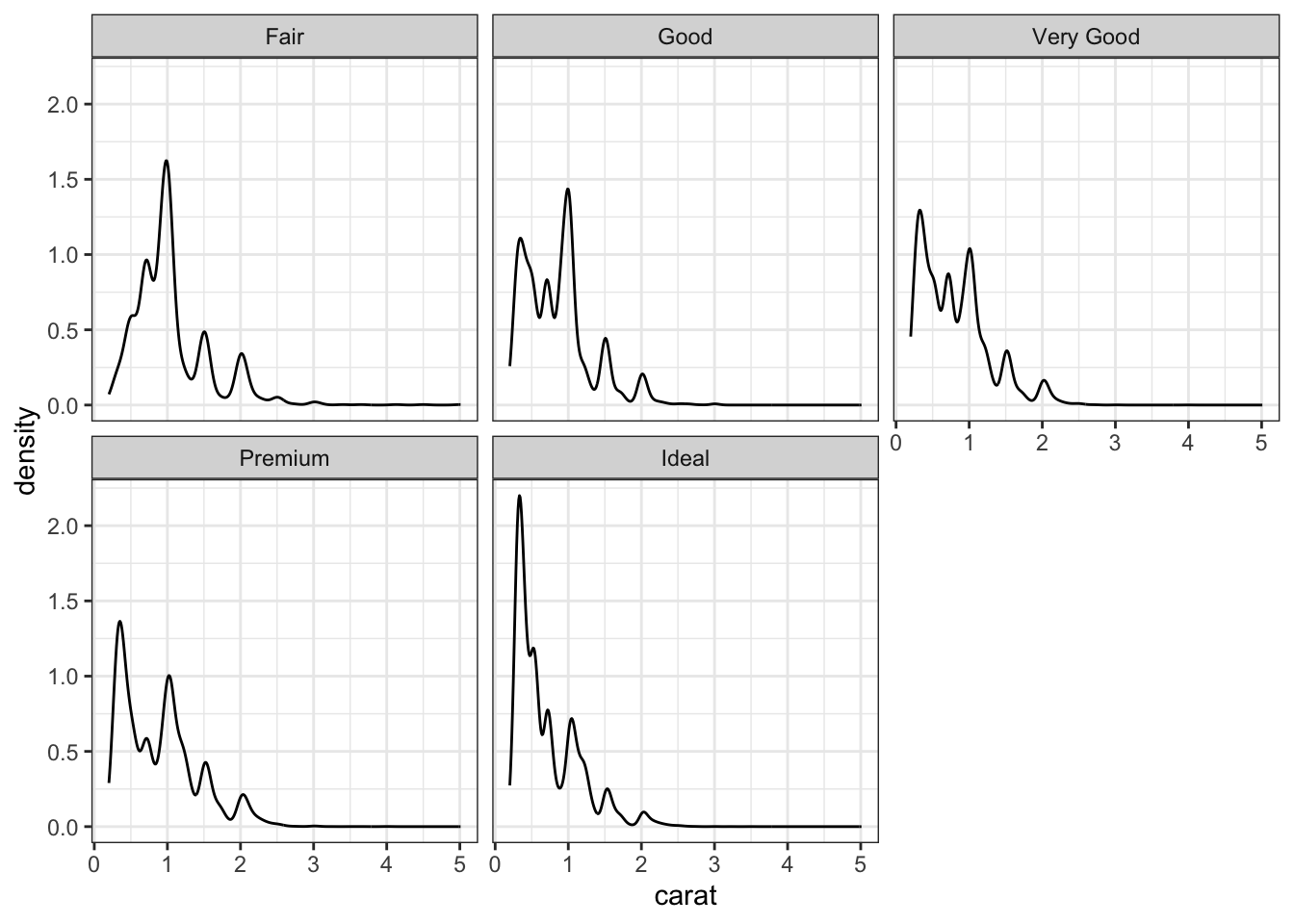
# Density plotsggplot(data = diamonds) +geom_density(mapping =aes(x = carat, color = cut,linetype = cut))
or we could use facets
# Density plots with facetsggplot(data = diamonds) +geom_density(mapping =aes(x = carat)) +facet_wrap(~cut)
15.2.4 Histogram
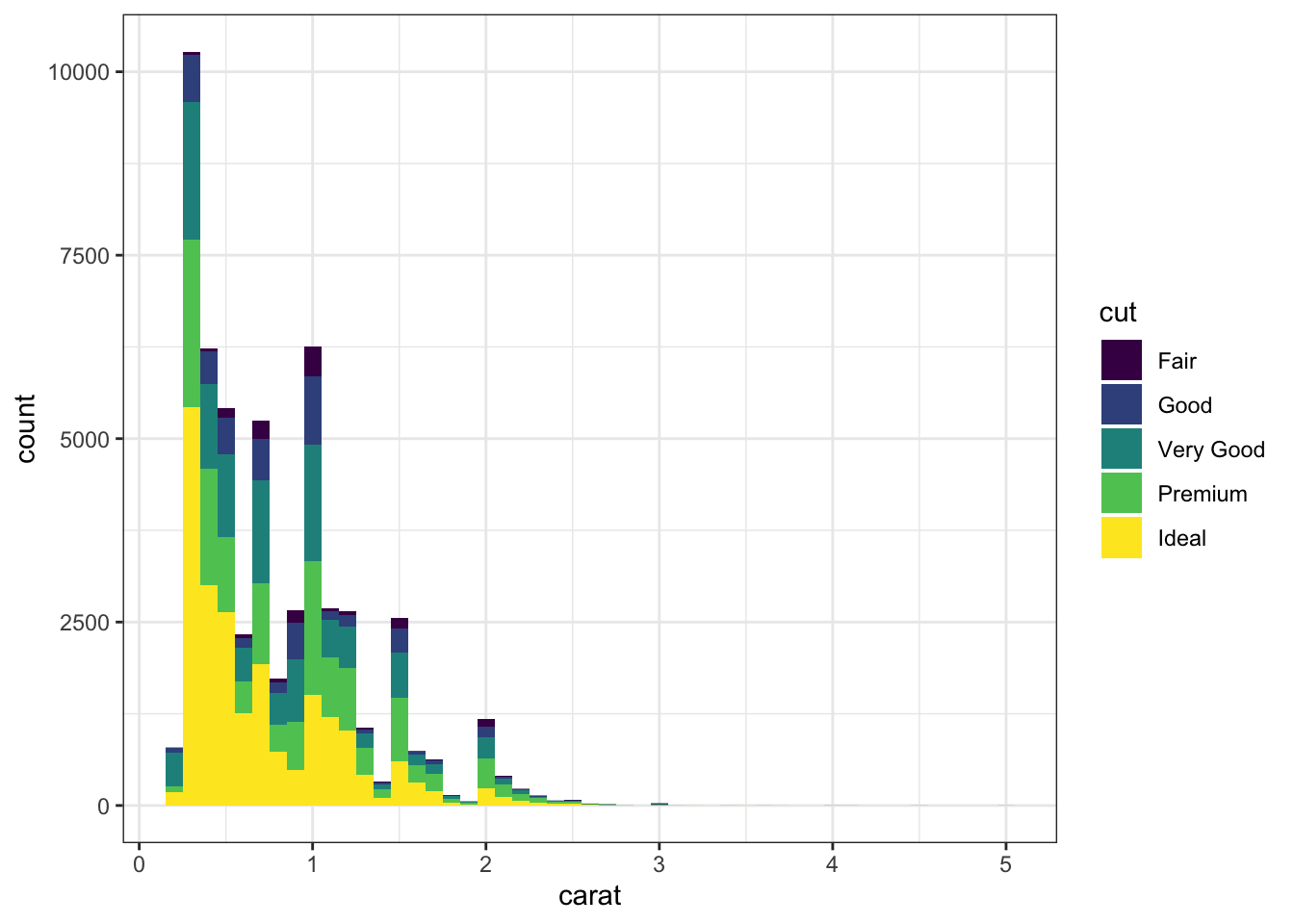
For histograms, the default is to create a stacked histogram (similar to the stack bar chart) we saw previously. This provides the univariate histogram but colored according to the number of observations in a second categorical variable.
# Stacked histogramsggplot(data = diamonds) +geom_histogram(mapping =aes( x = carat, fill = cut),binwidth =0.1)
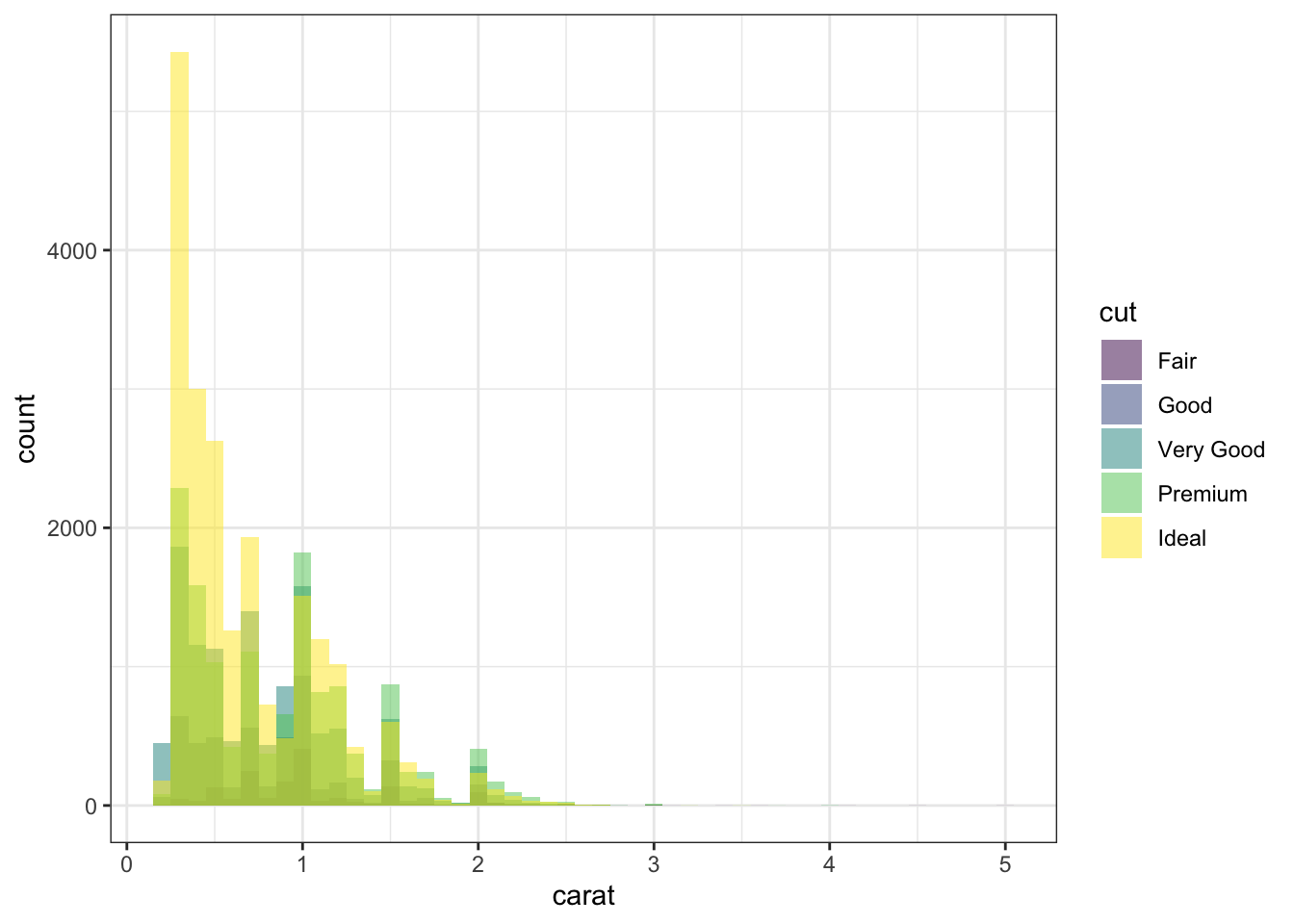
If we instead want overlapping histograms, we can use stat='identity'. Since the histograms will be overlapping, we may want to provide transparency to the histograms using alpha.
# Overlapped histogramsggplot(data = diamonds) +geom_histogram(mapping =aes( x = carat, fill = cut),binwidth =0.1,position ='identity', # overlap the histogramscolor =NA, # remove histogram border coloralpha =0.5) # make histograms semi-transparent
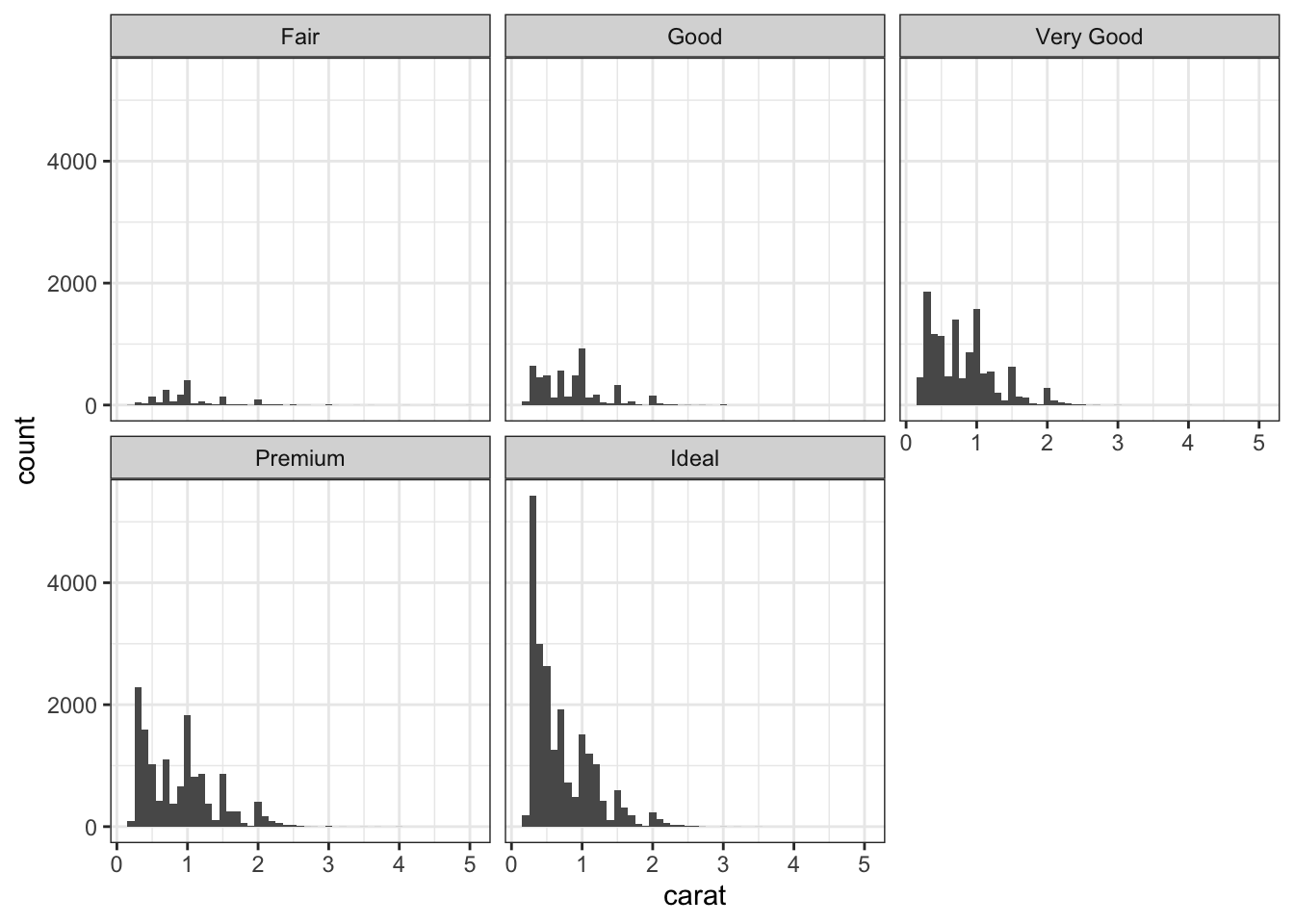
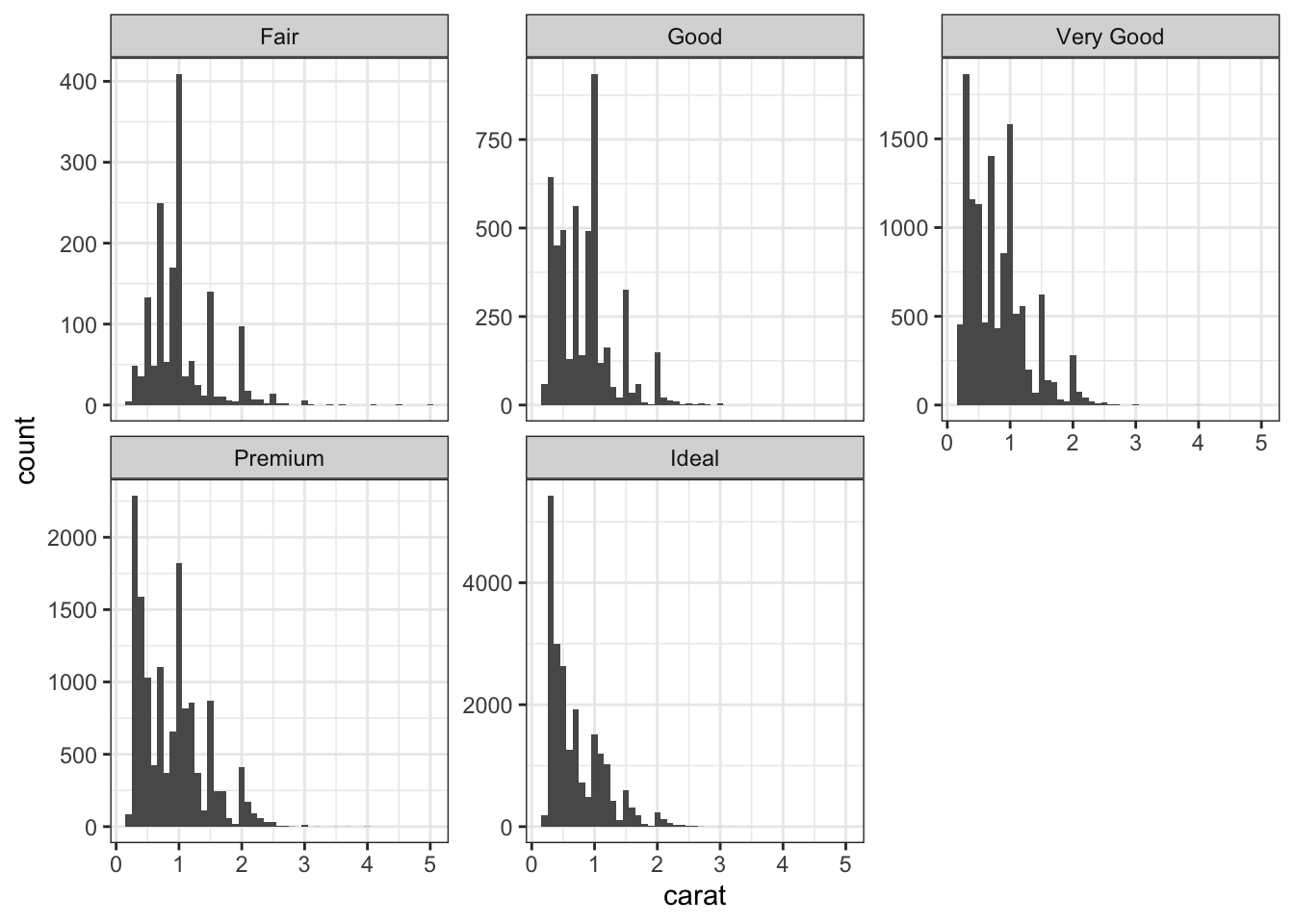
# Faceted histogram with free y-axesggplot(data = diamonds) +geom_histogram(mapping =aes(x = carat),binwidth =0.1) +facet_wrap(~cut, scales ="free_y") # separate y-axes for each facet
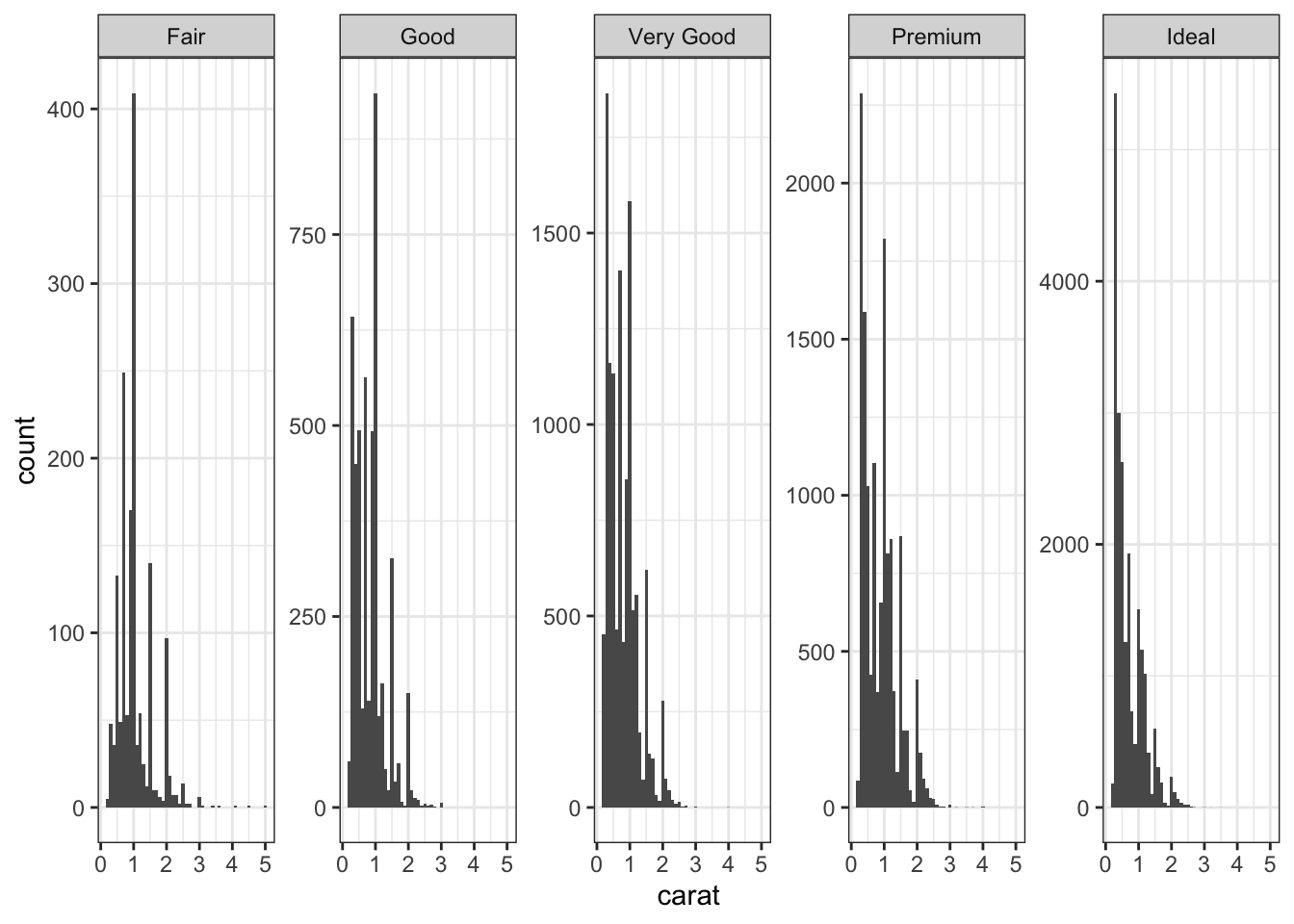
If you want more control, you can determine how many columns to use.
# Faceted histogram with 5 columnsggplot(data = diamonds) +geom_histogram(mapping =aes(x = carat),binwidth =0.1) +facet_wrap(~cut, ncol =5, # 5 columns so all histograms on the same rowscales ="free_y")
15.2.5 Scatterplots
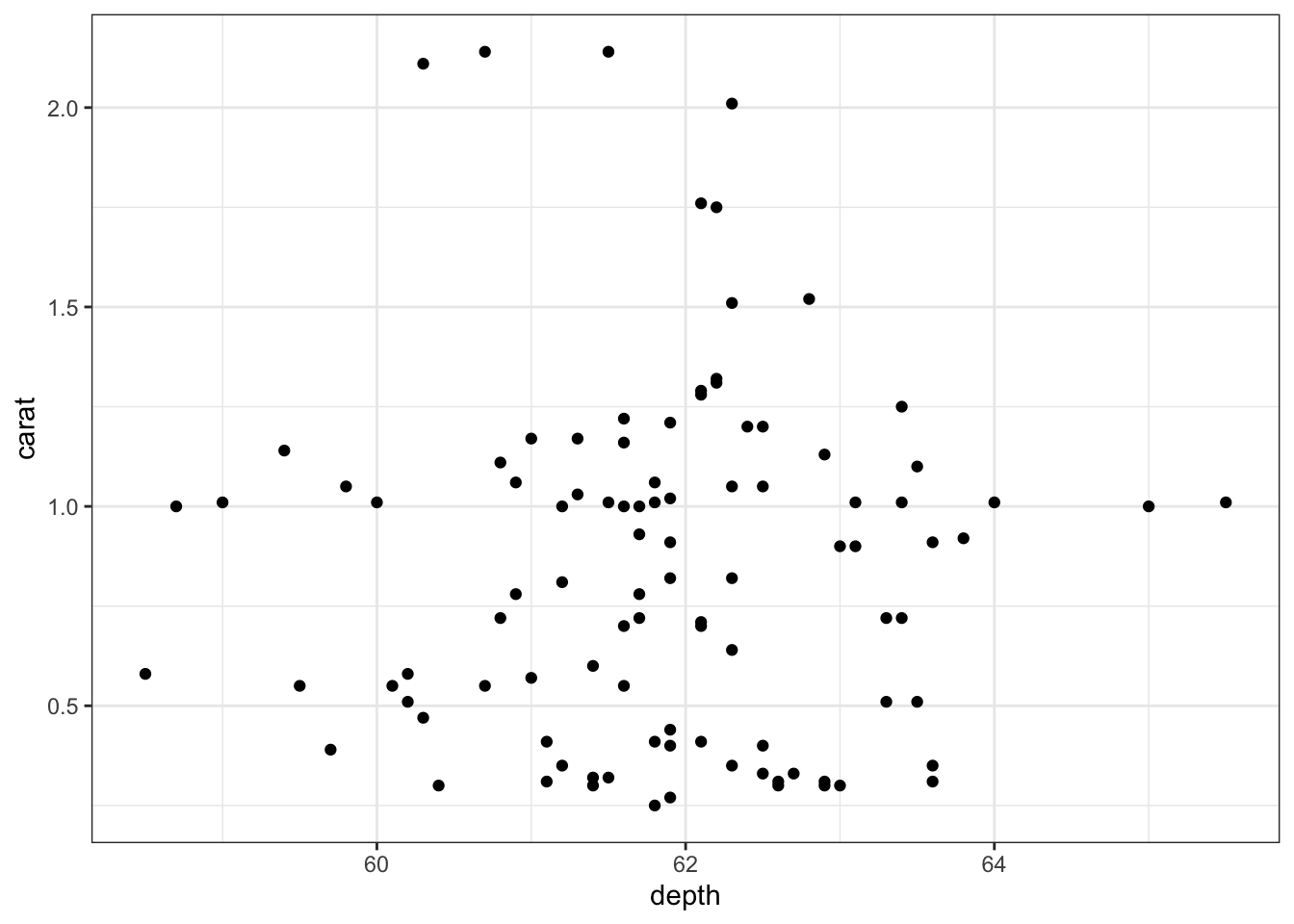
We can also use scatterplots, especially when there is not a lot of data
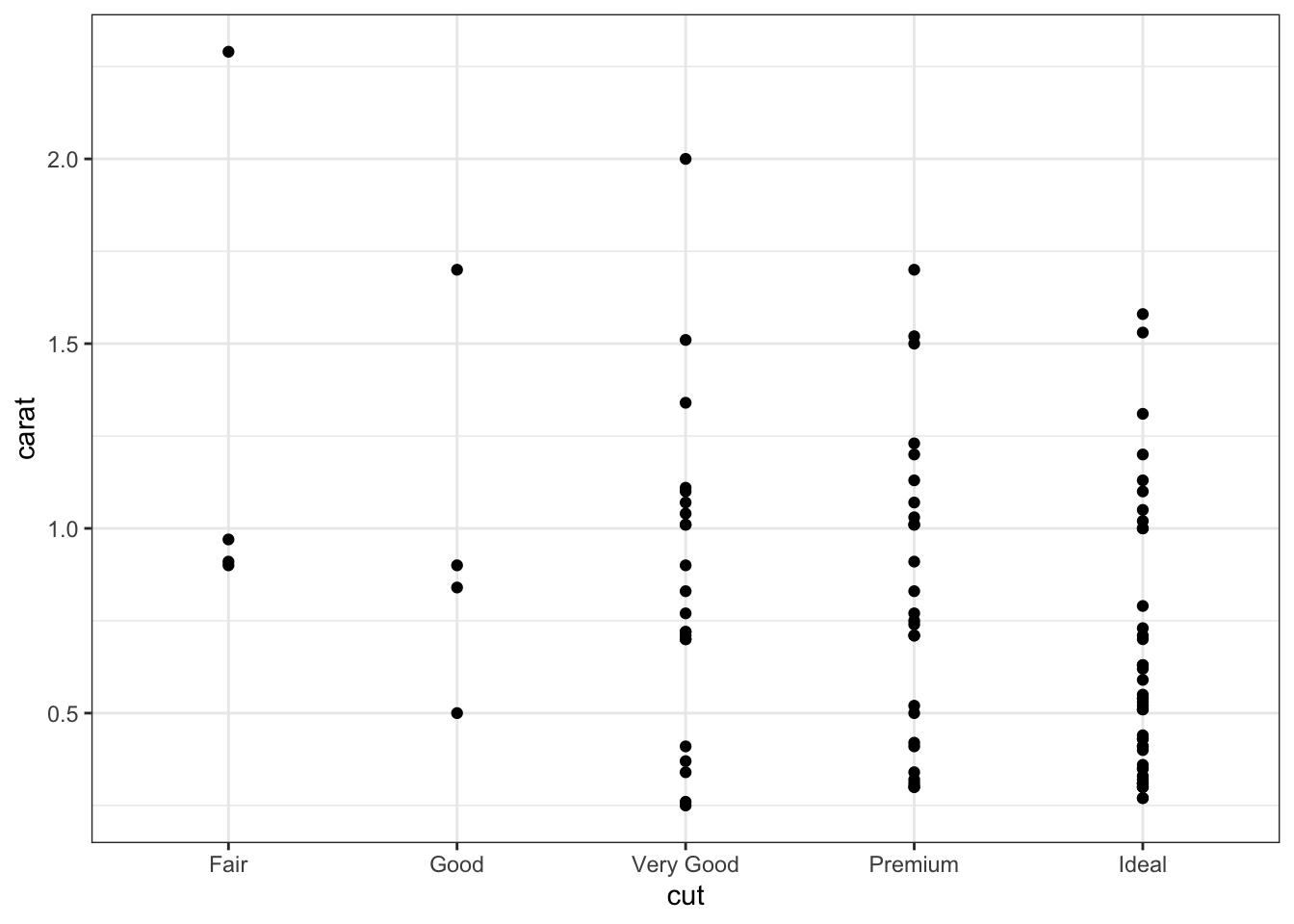
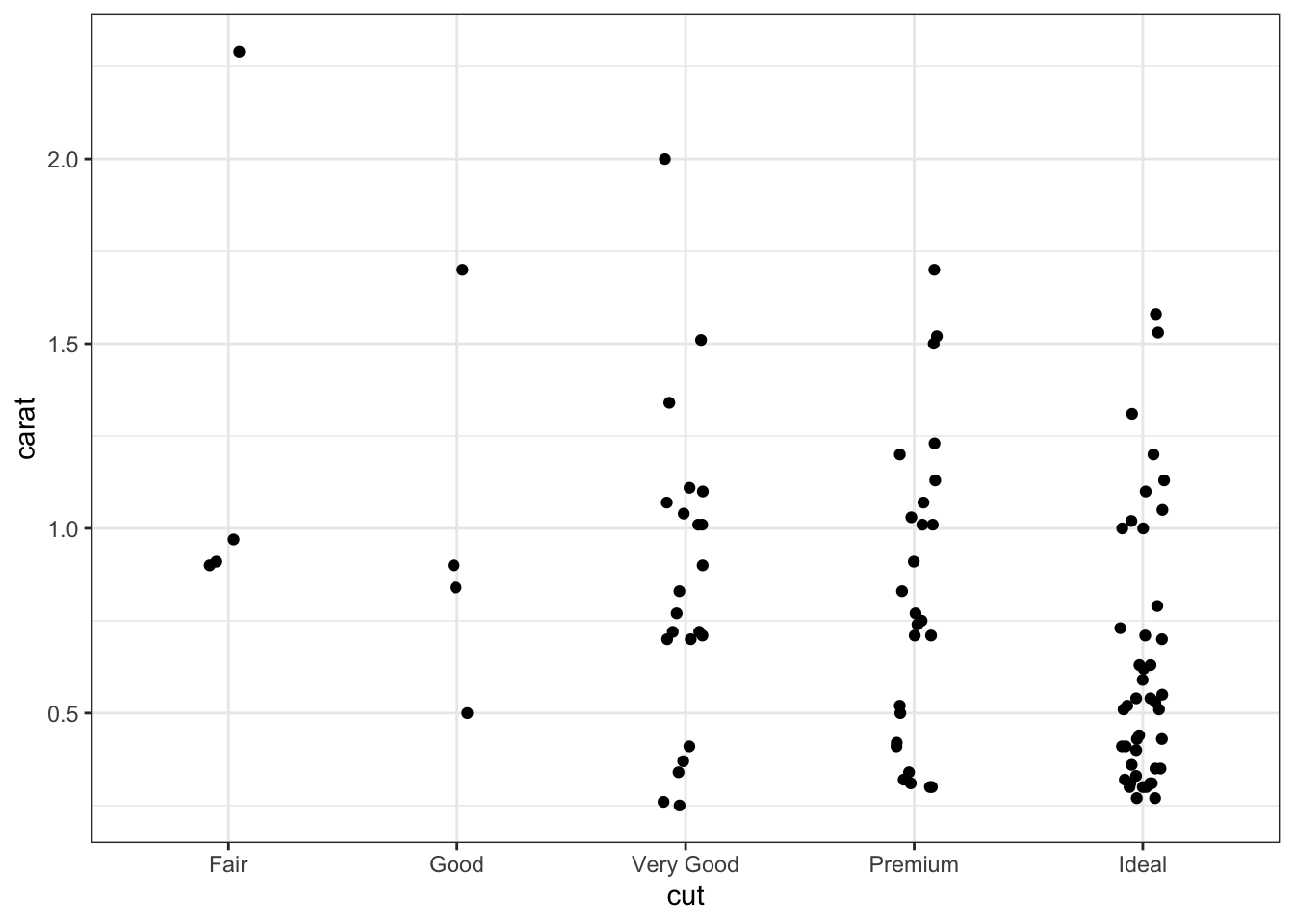
# Scatterplotsd <- diamonds |>sample_n(100) # Sample 100 random data pointsggplot(data = d) +geom_point(mapping =aes(x = cut, y = carat))
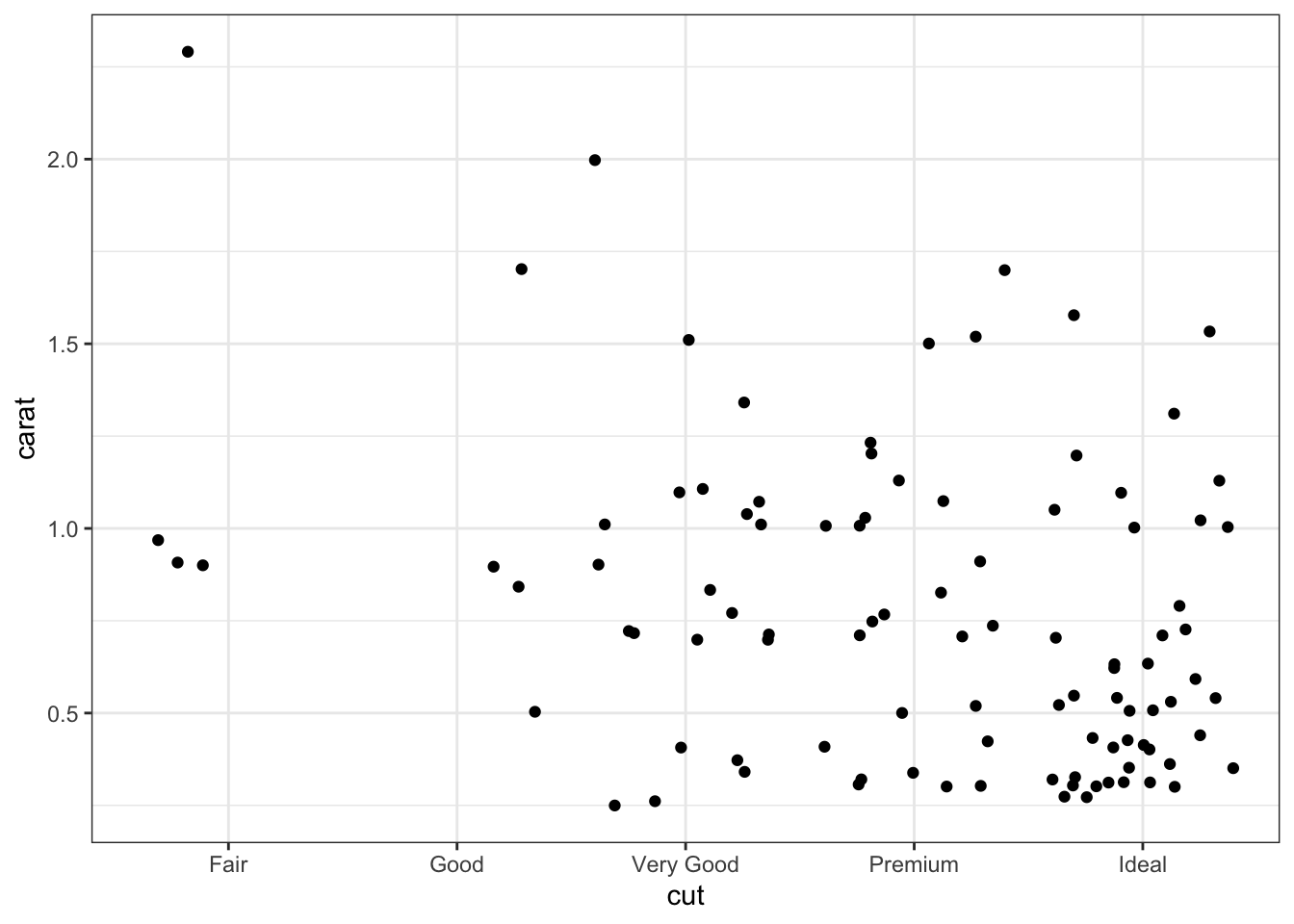
Since the points line up directly above the categorical variable, it is helpful to utilize jitter to enable the viewer to see individual points.
# Scatterplots with jitterggplot(data = d) +geom_jitter(mapping =aes(x = cut, y = carat))
You can adjust the amount of jitter using width and height arguments.
# Scatterplots with less than default jitterggplot(data = d) +geom_jitter(mapping =aes(x = cut, y = carat),width =0.1,height =0) # eliminate jitter on the y-axis variable
15.2.6 Pointrange plots
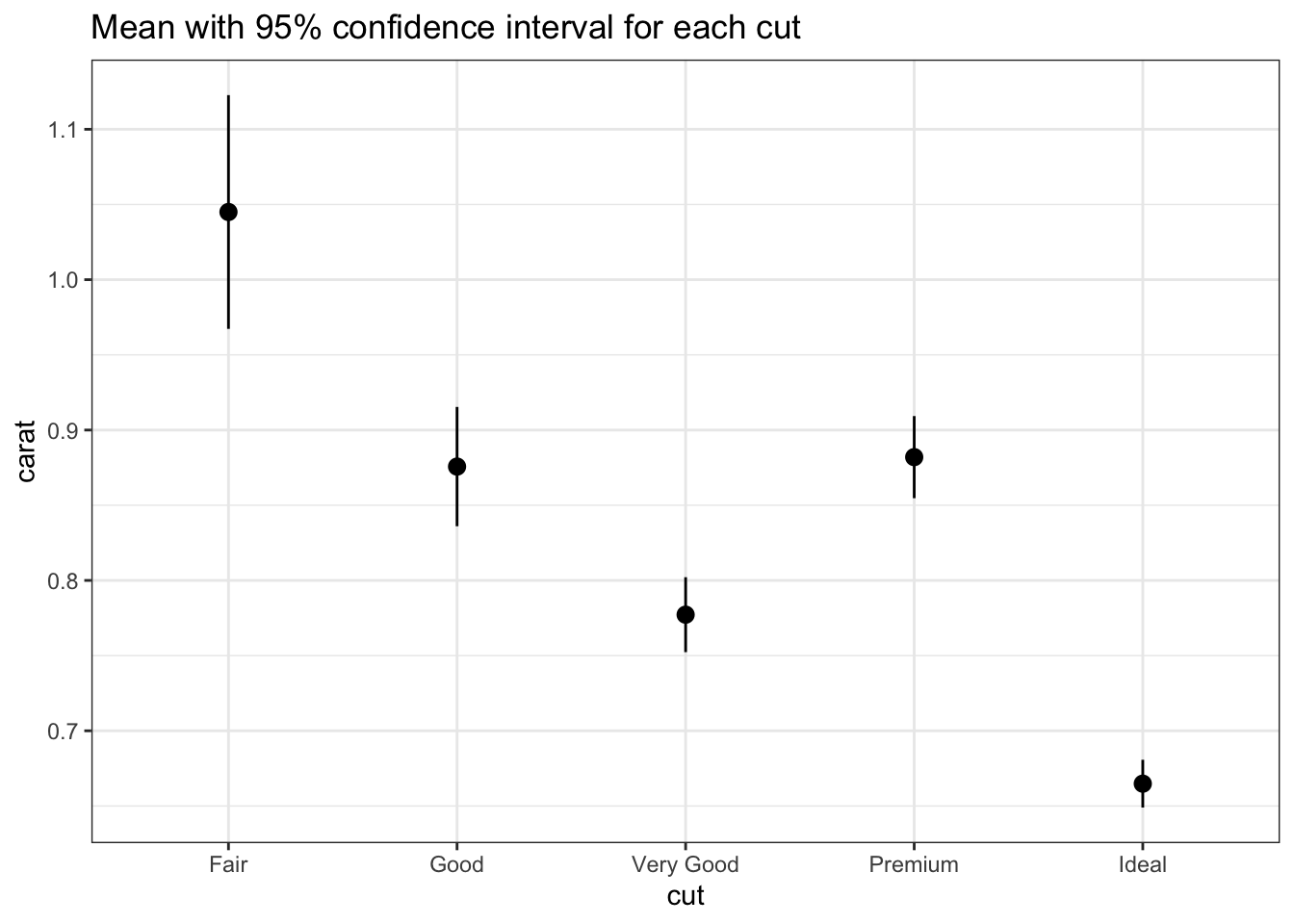
If you only need to visualizing mean and a measure of uncertainty, you can utilize a pointrange plot. In order to utilize the pointrange plot, you need to summarize your data, i.e. transform it.
# Transform (summarize) data for pointrange plotdiamond_summaries <- diamonds |>sample_n(1000) |># randomly sample 1,000 observations so we can see the error barsgroup_by(cut) |>summarize(n =n(), # n() counts the number of observations in that groupmean =mean(carat),sd =sd(carat),# Construct endpoints of a 95% confidence intervallb = mean -pt(.975, n-1) * sd /sqrt(n),ub = mean +pt(.975, n-1) * sd /sqrt(n), )
Now we are ready to construct the plot
# Pointrange plotggplot(data = diamond_summaries) +geom_pointrange(mapping =aes(x = cut,y = mean,ymin = lb,ymax = ub)) +labs(title ="Mean with 95% confidence interval for each cut",y ="carat")
15.2.7 Bar charts
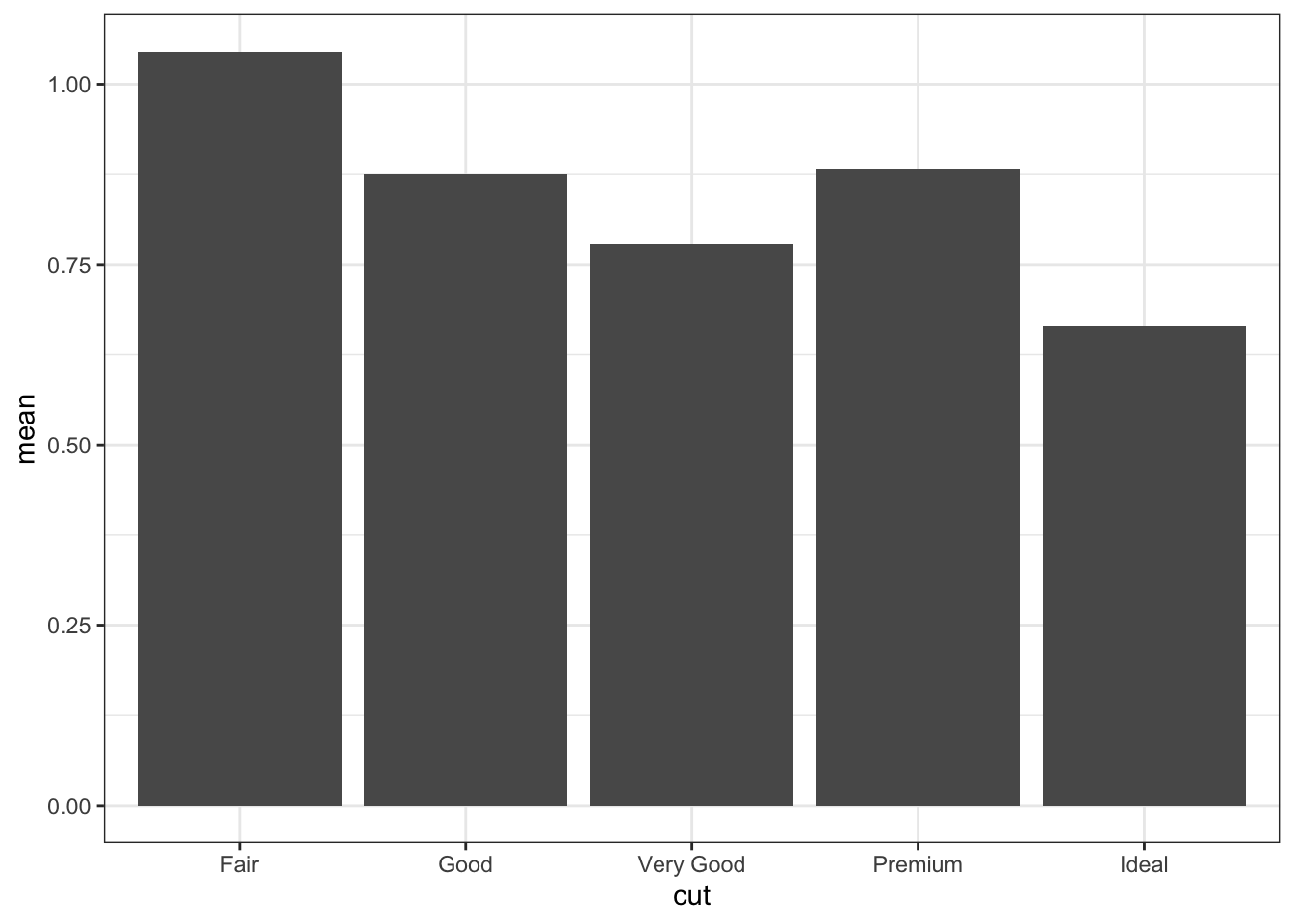
Many fields utilize bar charts to visualize mean effects.
# Bar chart for meansggplot(diamond_summaries) +geom_col(mapping =aes( # notice geom_col rather than geom_barx = cut,y = mean ))
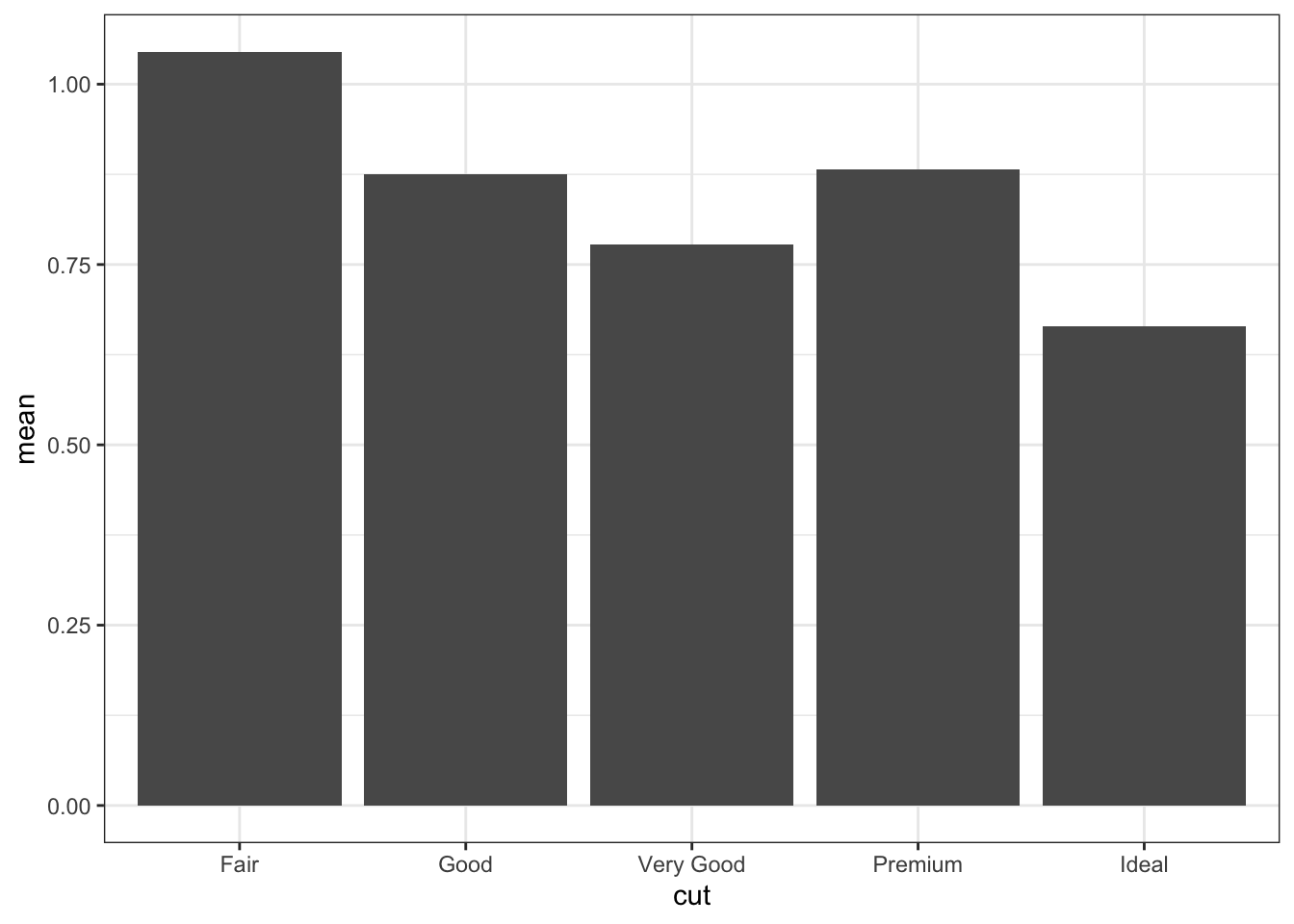
An equivalent alternative is to use geom_bar() with stat = "identity".
# Equivalent bar chart, but using geom_barggplot(diamond_summaries) +geom_bar(mapping =aes( x = cut,y = mean),stat ="identity") # avoid the default counting by geom_bar
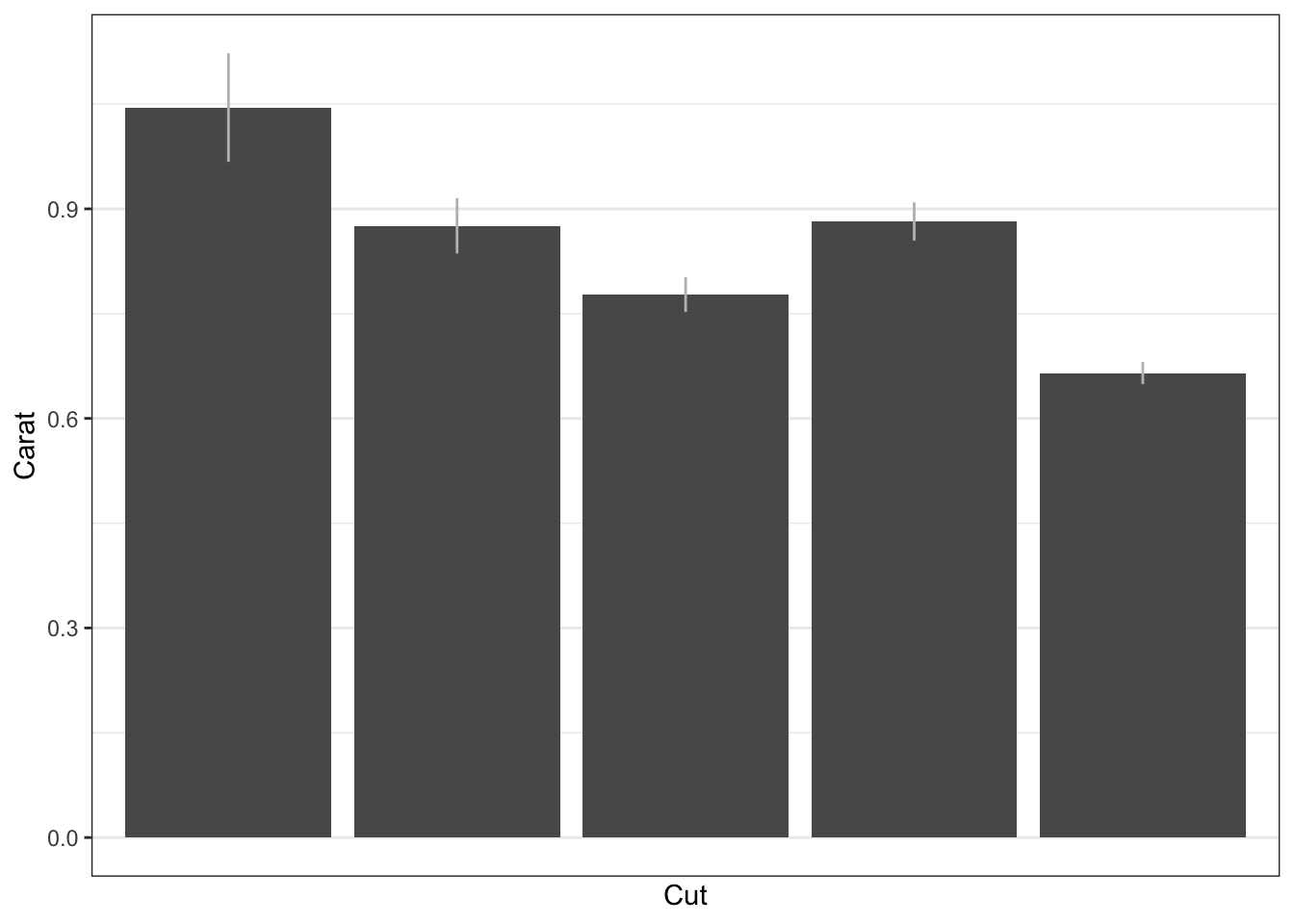
In these fields, it is common to include some measure of uncertainty. We can add standard errors using geom_linerange().
# Linerange plotggplot(diamond_summaries,# Put mapping in ggplot since both geoms will use itmapping =aes(x = cut,y = mean,ymin = lb,ymax = ub )) +geom_col() +geom_linerange(color ="gray") +labs(x ="Cut",y ="Carat" ) +# remove vertical grid so we can see errorbarsscale_x_discrete(breaks =NULL)
15.3 Numeric-numeric
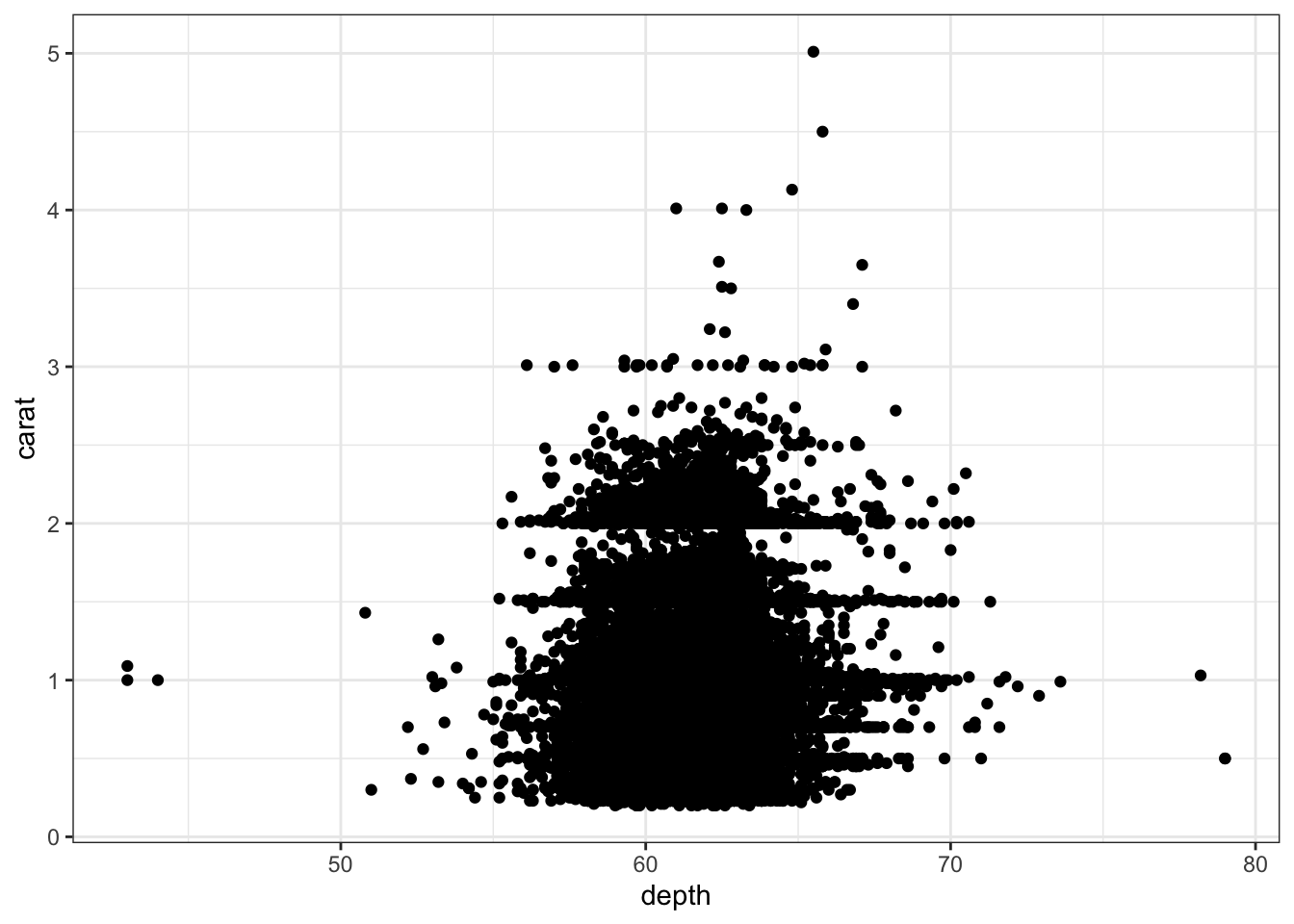
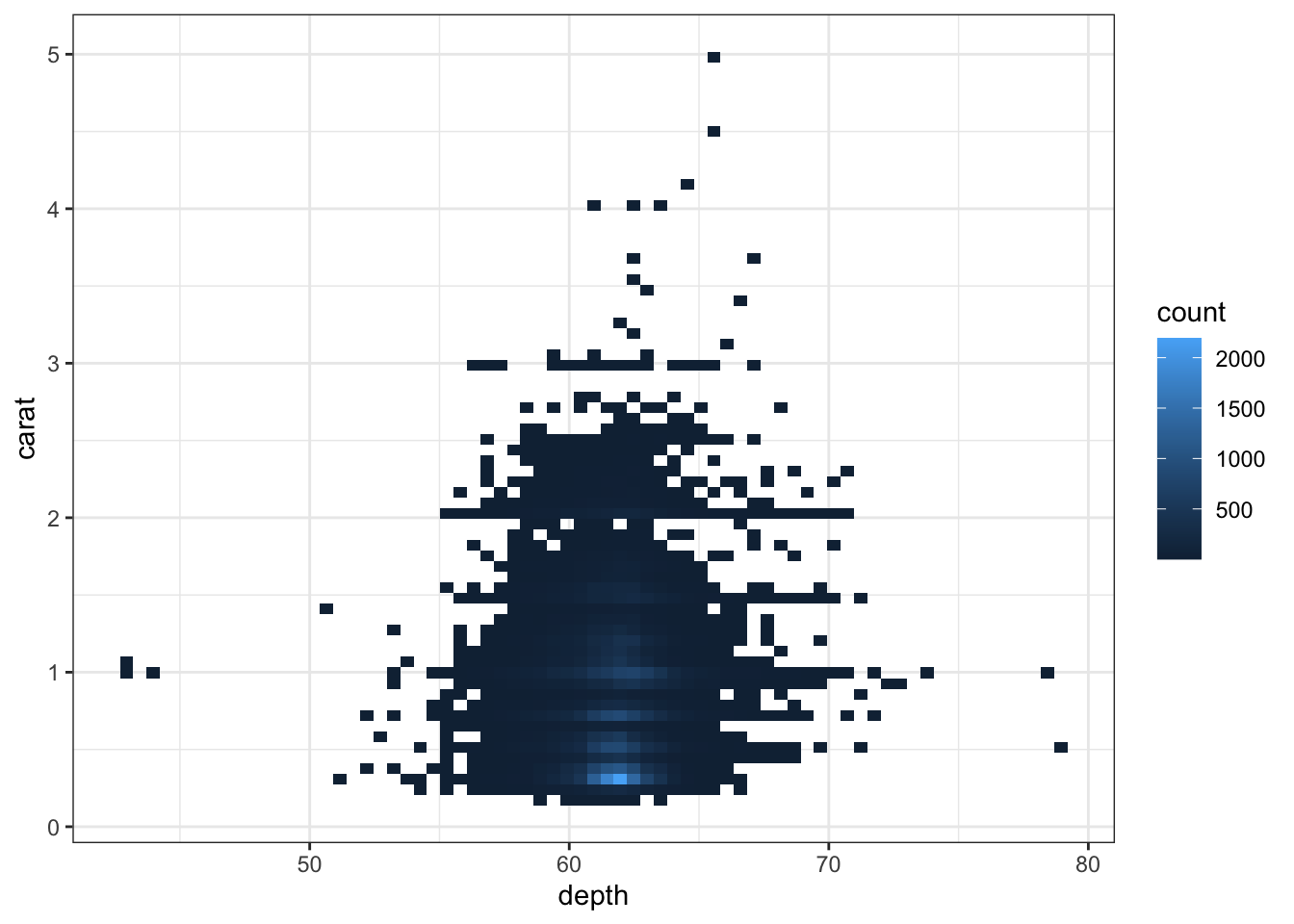
When both variables are continuous, there are a variety of plots that can be used to visualize the data. When there are not too many points, we can utilize scatterplots
Warning: Computation failed in `stat_binhex()`.
Caused by error in `compute_group()`:
! The package "hexbin" is required for `stat_bin_hex()`.
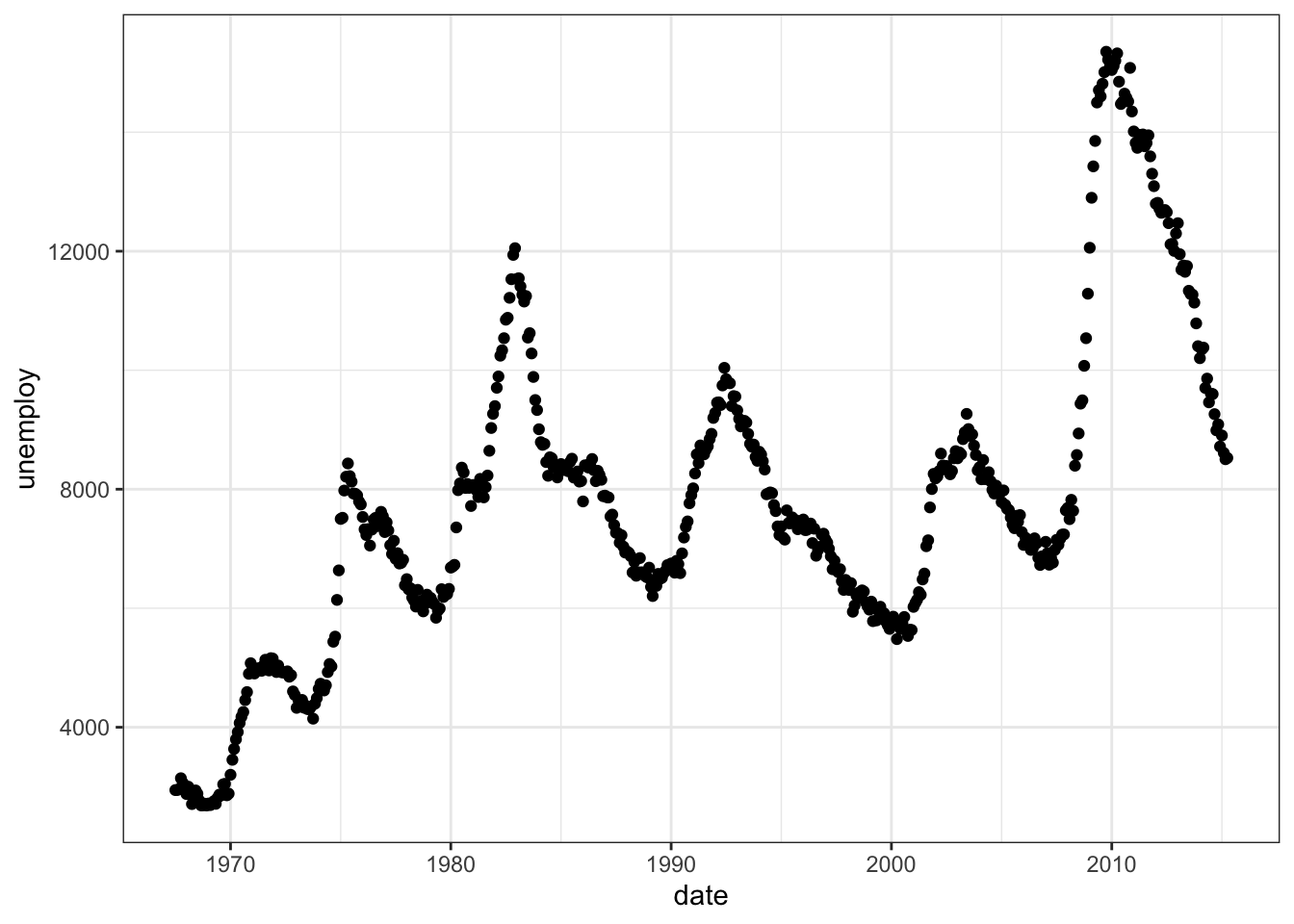
15.3.3 Time series plot
A time series plot is a plot with two continuous variables where one of the variables is time. Time is always put on the x-axis.
We can use a scatterplot for a time series plot
# Time series scatterplotggplot(economics) +geom_point(mapping =aes(x = date,y = unemploy ))
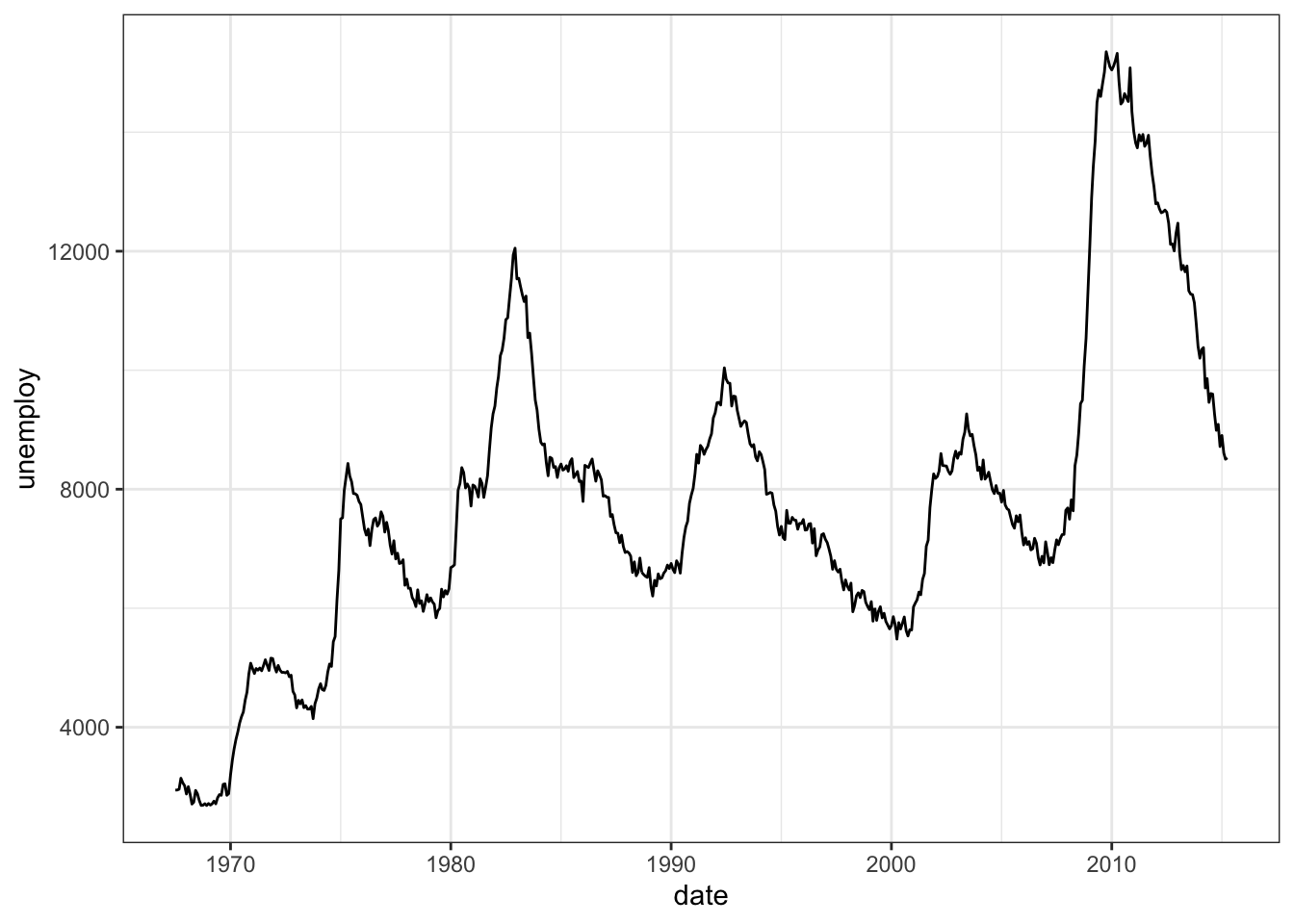
or we can use a lineplot
# Time series lineplotggplot(economics) +geom_line(mapping =aes(x = date,y = unemploy ))
15.4 Summary
We discussed a variety of plots for two variables including bar charts when there are two categorical variables, multiple types of plots when you have a mix of a categorical and a numeric variable, and scatterplots and 2-dimensional histograms when you have two numeric variables.
There many more types of plots available and I encourage you to take a look at the R Graph Gallery.