Binomial analyses are relevant for binary data. Often these data have been aggregated so that you have some count of the number of successes out of a total number of attempts.
library("tidyverse"); theme_set(theme_bw())
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library("Sleuth3")
Recall that if \(X_i \stackrel{ind}{\sim} Ber(p)\), then \[
Y = X_1 + X_2 + \cdots + X_n \sim Bin(n,p)$.
\] Thus \(Y\) is the number of successes out of \(n\) attempts when the attempts are independent and they have a common probability of success \(p\) (which may be unknown).
33.1 One group
If there is a single binomial population, then we basically estimate \(p\) and conduct hypotheses tests for \(H_0: p = p_0\).
33.1.1 binom.test()
Modified from :
## Conover (1971), p. 97f.## Under (the assumption of) simple Mendelian inheritance, a cross## between plants of two particular genotypes produces progeny 1/4 of## which are "dwarf" and 3/4 of which are "giant", respectively.## In an experiment to determine if this assumption is reasonable, a## cross results in progeny having 243 dwarf and 682 giant plants.## If "giant" is taken as success, the null hypothesis is that p =## 3/4 and the alternative that p != 3/4.successes <-682failures <-243# Exact approachbinom.test(c(successes, failures), # construct a vector using c()p =3/4)
Exact binomial test
data: c(successes, failures)
number of successes = 682, number of trials = 925, p-value = 0.3825
alternative hypothesis: true probability of success is not equal to 0.75
95 percent confidence interval:
0.7076683 0.7654066
sample estimates:
probability of success
0.7372973
Alternatively, you can use
# Alternativey <- successesn <- successes + failuresbinom.test(y, n, p =3/4)
Exact binomial test
data: y and n
number of successes = 682, number of trials = 925, p-value = 0.3825
alternative hypothesis: true probability of success is not equal to 0.75
95 percent confidence interval:
0.7076683 0.7654066
sample estimates:
probability of success
0.7372973
33.1.2 prop.test()
Asymptotic approach when the sample size is large and the true probability is not too close to 0 or 1.
# Asymptoticprop.test(matrix(c(successes, # construct matrix failures), ncol =2), p =3/4)
1-sample proportions test with continuity correction
data: matrix(c(successes, failures), ncol = 2), null probability 3/4
X-squared = 0.72973, df = 1, p-value = 0.393
alternative hypothesis: true p is not equal to 0.75
95 percent confidence interval:
0.7074391 0.7651554
sample estimates:
p
0.7372973
or, more commonly,
# Alternative approachprop.test(y, n, p =3/4)
1-sample proportions test with continuity correction
data: y out of n, null probability 3/4
X-squared = 0.72973, df = 1, p-value = 0.393
alternative hypothesis: true p is not equal to 0.75
95 percent confidence interval:
0.7074391 0.7651554
sample estimates:
p
0.7372973
33.1.3 Additional arguments
# Argumentsargs(prop.test)
function (x, n, p = NULL, alternative = c("two.sided", "less",
"greater"), conf.level = 0.95, correct = TRUE)
NULL
prop.test(y, n, p =3/4, alternative ="greater", conf.level =0.9, correct =FALSE)
1-sample proportions test without continuity correction
data: y out of n, null probability 3/4
X-squared = 0.79604, df = 1, p-value = 0.8139
alternative hypothesis: true p is greater than 0.75
90 percent confidence interval:
0.7183437 1.0000000
sample estimates:
p
0.7372973
Note: I would ALWAYS use .
Similarly for .
args(binom.test)
function (x, n, p = 0.5, alternative = c("two.sided", "less",
"greater"), conf.level = 0.95)
NULL
binom.test(y, n, p =3/4, alternative ="greater", conf.level =0.9)
Exact binomial test
data: y and n
number of successes = 682, number of trials = 925, p-value = 0.8241
alternative hypothesis: true probability of success is greater than 0.75
90 percent confidence interval:
0.7178455 1.0000000
sample estimates:
probability of success
0.7372973
33.2 Two groups
With two groups, we have two independent binomials.
\[
Y_1 \sim Bin(n_1, p_1)
\qquad \mbox{and} \qquad
Y_2 \sim Bin(n_2, p_2)
\] with \(Y_1\) and \(Y_2\) being independent.
Independent here means that, if you know \(p_1\) and \(p_2\), knowing \(Y_1\) gives you no (additional) information about \(Y_2\) (and vice versa). Also remember that underlying a binomial assumption is a set of independent Bernoulli random variables.
The most common situation for independence to be violated is when the data are or and we will talk about this in the contingency table section below.
When there are two populations, we are often interested in understanding a causal relationship between observed differences in the probability of success and the two populations.
33.2.1 Experimental data
With experimental data, we can determine causal relationships. In these data, we randomly assign participants to receive 1,000 mg of Vitamin C per day through the cold season or placebo.
# Two group experiment datacase1802 |>mutate(p = NoCold / (Cold+NoCold))
Comparing the probability of getting a cold in the two groups.
# Construct matrix using cbindprop.test(cbind(case1802$Cold, case1802$NoCold))
2-sample test for equality of proportions with continuity correction
data: cbind(case1802$Cold, case1802$NoCold)
X-squared = 5.9196, df = 1, p-value = 0.01497
alternative hypothesis: two.sided
95 percent confidence interval:
0.01391972 0.13222111
sample estimates:
prop 1 prop 2
0.8150852 0.7420147
Alternatively, we can create a matrix from the data.frame.
# Construct matrix using converted data.frameprop.test(case1802[,c("Cold","NoCold")] |>as.matrix())
2-sample test for equality of proportions with continuity correction
data: as.matrix(case1802[, c("Cold", "NoCold")])
X-squared = 5.9196, df = 1, p-value = 0.01497
alternative hypothesis: two.sided
95 percent confidence interval:
0.01391972 0.13222111
sample estimates:
prop 1 prop 2
0.8150852 0.7420147
Remember our independence assumptions. Unfortunately, we don’t have enough information about these data to assess the independence assumption.
33.2.2 Observational data
Remember that with observational data we cannot determine a cause-and-effect relationships. But there is an even more common situation called Simpson’s Paradox that can hamper our understanding of observational data as we will see with this UC-Berkeley Admissions data.
Let’s take a look at the admission rates by gender at UC-Berkeley by calculating the total number of applicants and total number of admits by gender across all departments.
# A tibble: 2 × 6
Gender Admitted Rejected y n p
<fct> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Male 1198 1493 1198 2691 0.445
2 Female 557 1278 557 1835 0.304
Because the number of individuals is large and the probability is not close to 0 or 1, we’ll go ahead and use prop.test(). With two populations, the default null hypothesis is that \[
H_0: p_1 = p_2.
\]
2-sample test for equality of proportions with continuity correction
data: admissions$y out of admissions$n
X-squared = 91.61, df = 1, p-value < 2.2e-16
alternative hypothesis: two.sided
95 percent confidence interval:
0.1129887 0.1703022
sample estimates:
prop 1 prop 2
0.4451877 0.3035422
This p-value suggests that the null model which assumes independence (both across and within binomial samples) and equal probabilities is unlikely to be true. As an analyst, we need to make a decision about whether the independence assumptions are reasonable.
33.3 More than two groups
\[
Y_g \stackrel{ind}{\sim} Bin(n_g, p_g)
\] for \(g=1,\ldots,G\). Thus, we assume that
observations from different groups are independent,
observations within a group are independent, and
observations within a group have the same probability.
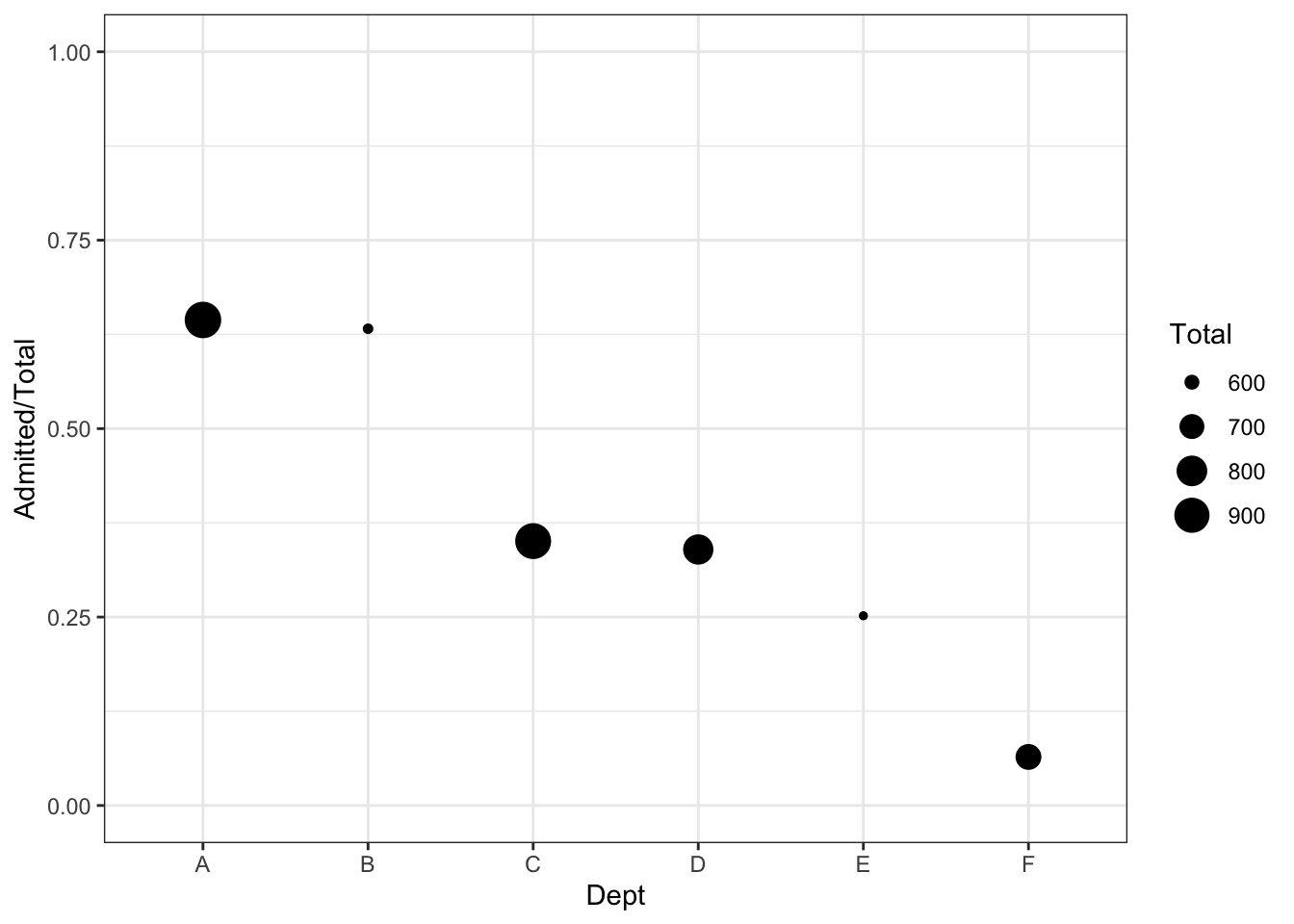
Let’s return to our UC-Berkeley admissions data. Rather than combine across departments, let’s compare the probability of acceptance across departments. First, let’s ignore gender.
When we have multiple groups, we may be interested in a test where the null hypothesis is that all the group means are equal, i.e. \(H_0: p_g = p_0\) for all \(g\).
# Test equality of all proportionsprop.test(admissions_by_department$Admitted, admissions_by_department$Total)
6-sample test for equality of proportions without continuity correction
data: admissions_by_department$Admitted out of admissions_by_department$Total
X-squared = 778.91, df = 5, p-value < 2.2e-16
alternative hypothesis: two.sided
sample estimates:
prop 1 prop 2 prop 3 prop 4 prop 5 prop 6
0.64415863 0.63247863 0.35076253 0.33964646 0.25171233 0.06442577
33.4 Two explanatory variables
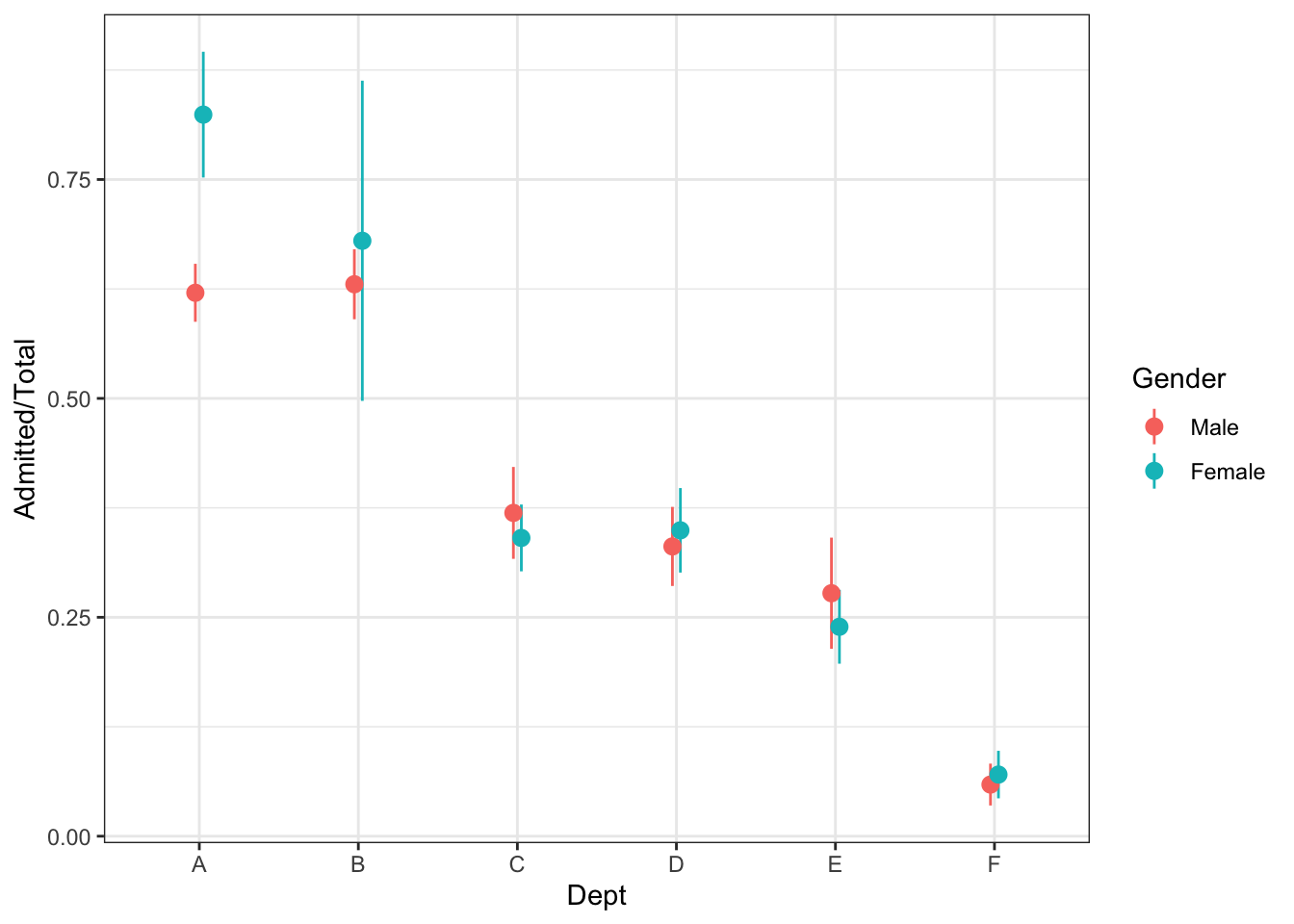
This isn’t really the question we are interested in. We are interested in the probability of admission by gender controlling (or adjusting) for department.
# UC-Berkeley Admission Data by Department and Genderadmissions_by_dept_and_gender <- UCBAdmissions |>as.data.frame() |>pivot_wider(names_from ="Admit", values_from ="Freq") |># group_by(Dept, Gender) |>mutate(Total = Admitted + Rejected,p_hat = Admitted / Total,# Calculate 95% confidence intervalslcl = p_hat -qnorm(.975)*sqrt(p_hat*(1-p_hat)/Total),ucl = p_hat +qnorm(.975)*sqrt(p_hat*(1-p_hat)/Total) )
# Admission data tableadmissions_by_dept_and_gender
# A tibble: 12 × 8
Gender Dept Admitted Rejected Total p_hat lcl ucl
<fct> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Male A 512 313 825 0.621 0.587 0.654
2 Female A 89 19 108 0.824 0.752 0.896
3 Male B 353 207 560 0.630 0.590 0.670
4 Female B 17 8 25 0.68 0.497 0.863
5 Male C 120 205 325 0.369 0.317 0.422
6 Female C 202 391 593 0.341 0.302 0.379
7 Male D 138 279 417 0.331 0.286 0.376
8 Female D 131 244 375 0.349 0.301 0.398
9 Male E 53 138 191 0.277 0.214 0.341
10 Female E 94 299 393 0.239 0.197 0.281
11 Male F 22 351 373 0.0590 0.0351 0.0829
12 Female F 24 317 341 0.0704 0.0432 0.0975