── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library("Sleuth3")library("ggResidpanel")
A linear regression model is commonly used when you have a continuous response variable and explanatory variables that are continuous or categorical. The goal of this slide is to introduce the use of the predict() function and then use this function to understand 1) different regression models and 2) what geom_smooth(method = "lm") is doing.
35.1 Model
The general structure of a regression model is \[
Y_i \stackrel{ind}{\sim} N(\beta_0 + \beta_1X_{i,1} + \cdots + \beta_{p} X_{i,p}, \sigma^2)
\] for \(i=1,\ldots,n\) or, equivalently, \[
Y_i = \beta_0 + \beta_1X_{i,1} + \cdots + \beta_{p} X_{i,p} + \epsilon_i,
\qquad \epsilon_i \stackrel{ind}{\sim} N(0, \sigma^2).
\]
where, for observation \(i\),
\(Y_i\) is the value of the response variable,
\(X_{i,j}\) is the value of the \(j\)th explanatory variable, and
\(\epsilon_i\) is the error.
The assumptions in every regression model are
errors are independent,
errors are normally distributed,
errors have constant variance,
and
the expected response, \(E[Y_i]\), depends on the explanatory variables according to a linear function (of the parameters).
35.1.1 Estimation
# Fit regression modelm <-lm(Depth ~ Year, data = case0201)summary(m)
Call:
lm(formula = Depth ~ Year, data = case0201)
Residuals:
Min 1Q Median 3Q Max
-3.2697 -0.5382 0.1618 0.6303 2.2303
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -651.04719 144.18752 -4.515 1.15e-05 ***
Year 0.33427 0.07293 4.583 8.65e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.973 on 176 degrees of freedom
Multiple R-squared: 0.1066, Adjusted R-squared: 0.1016
F-statistic: 21.01 on 1 and 176 DF, p-value: 8.65e-06
35.1.2 Predictions
To obtain predicted values, use the predict() function. Often, we will construct a new data.frame that contains specific values of our explanatory variables that we want to create predictions for.
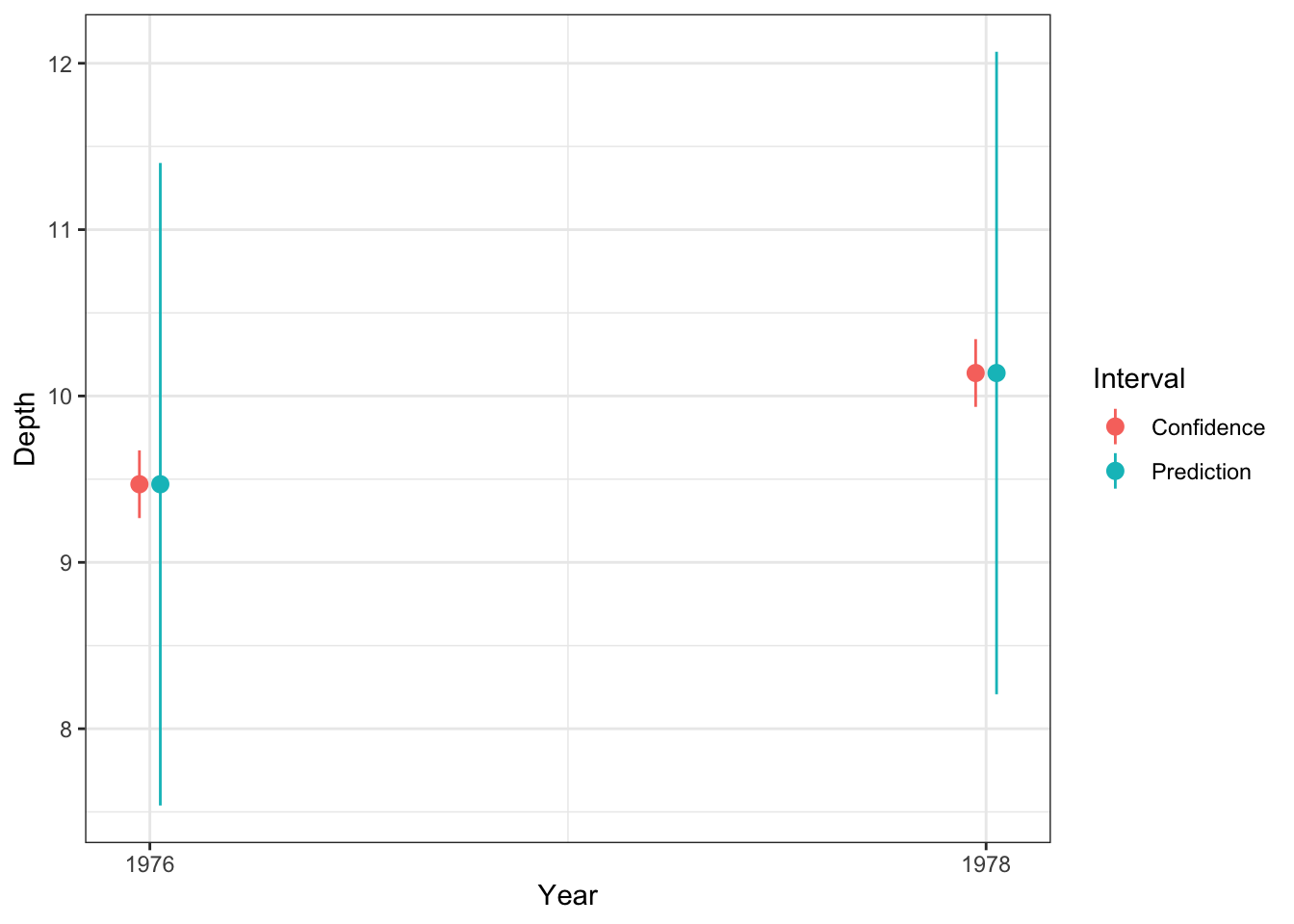
The predict() function can also be used to construct confidence intervals for any values of the explanatory variables. These confidence intervals describe variability in the mean response.
Year fit lwr upr
1 1976 9.469663 7.538576 11.40075
90 1978 10.138202 8.207115 12.06929
Confidence intervals and prediction intervals are often vastly different with the prediction intervals being much wider than confidence intervals. Thus, it is important to understand the difference.
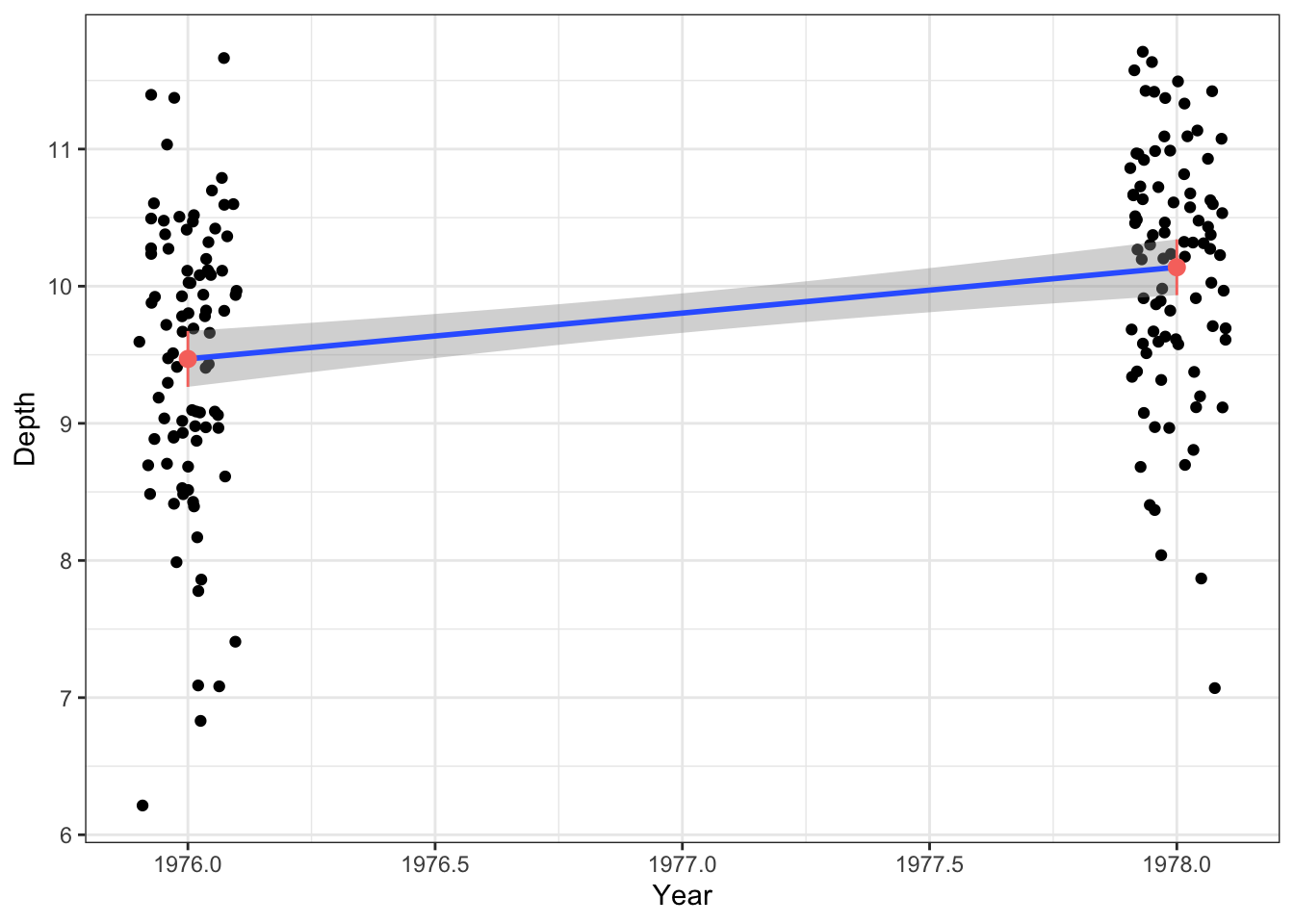
# geom_smooth()ggplot(case0201,aes(x = Year,y = Depth )) +geom_jitter(width=0.1) +geom_smooth(method ="lm") +geom_pointrange(data = ci,aes(y = fit,ymin = lwr,ymax = upr ),color ="#F8766D"# match the color used previously )
`geom_smooth()` using formula = 'y ~ x'
For the remainder of this discussion, we will focus on confidence intervals.
35.1.3 Continuous explanatory variable
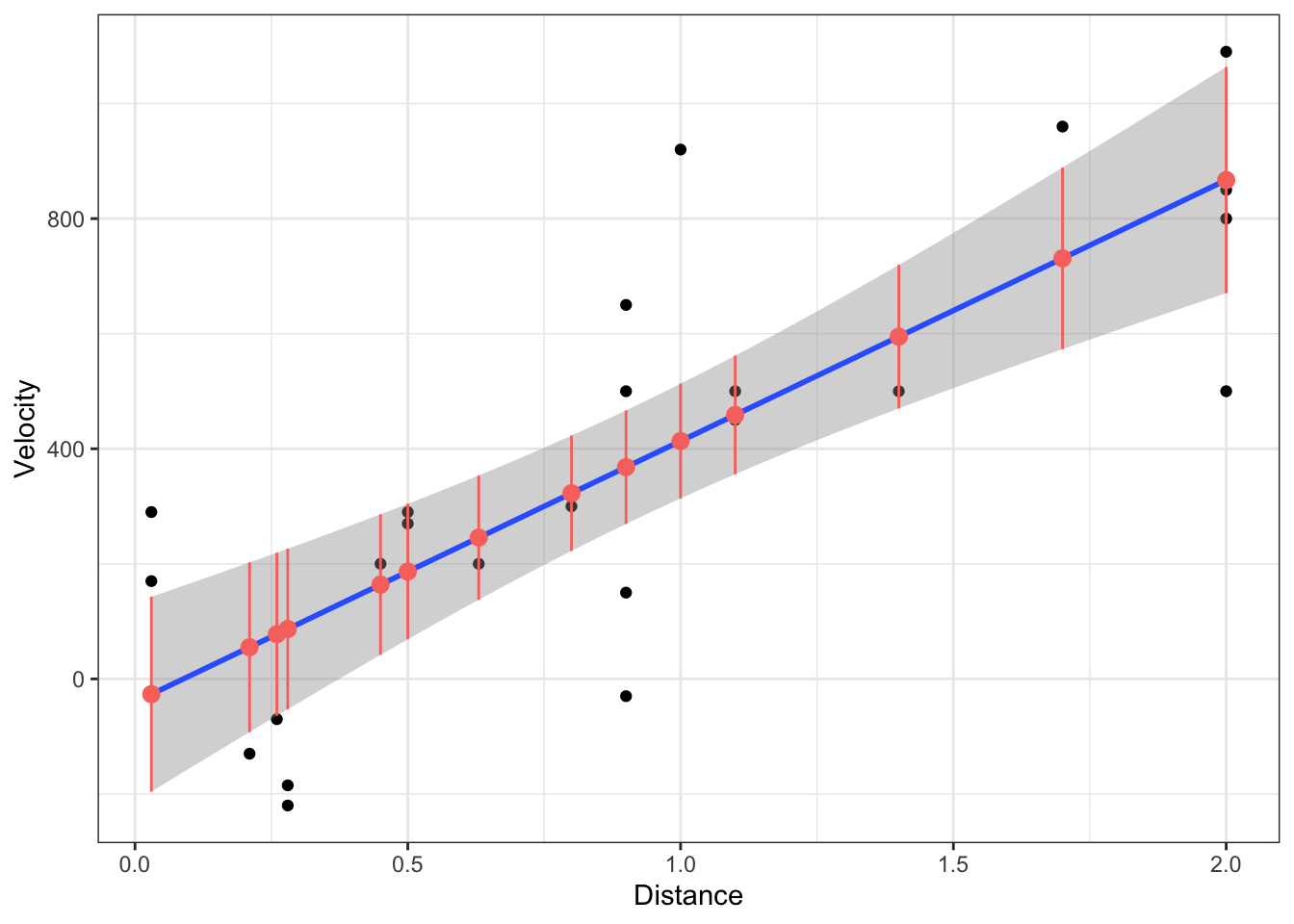
Let’s fit a simple linear regression model using a single continuous explanatory variable. Then, we will predict the response variable using 5 different values of the explanatory variable. At each of these 5 values, we will construct confidence intervals for the mean and compare these intervals to the intervals constructed from geom_smooth(method = "lm").
# Continuous examplem <-lm(Velocity ~ Distance, data = case0701)# Create new data from with 5 prediction pointsnd <-data.frame(Distance =seq(from =min(case0701$Distance),to =max(case0701$Distance),length =5))# Create confidence intervalsnd <- case0701 |>select(Distance) |>unique()p <-bind_cols( nd, predict(m,newdata = nd,interval ="confidence") |>as.data.frame()) |>rename(Velocity = fit)# Plot CIs and geom_smooth()g <-ggplot(case0701,aes(x = Distance,y = Velocity)) +geom_point() g +geom_smooth(method ="lm") +geom_pointrange(data = p,aes(ymin = lwr,ymax = upr ),col ="#F8766D" )
`geom_smooth()` using formula = 'y ~ x'
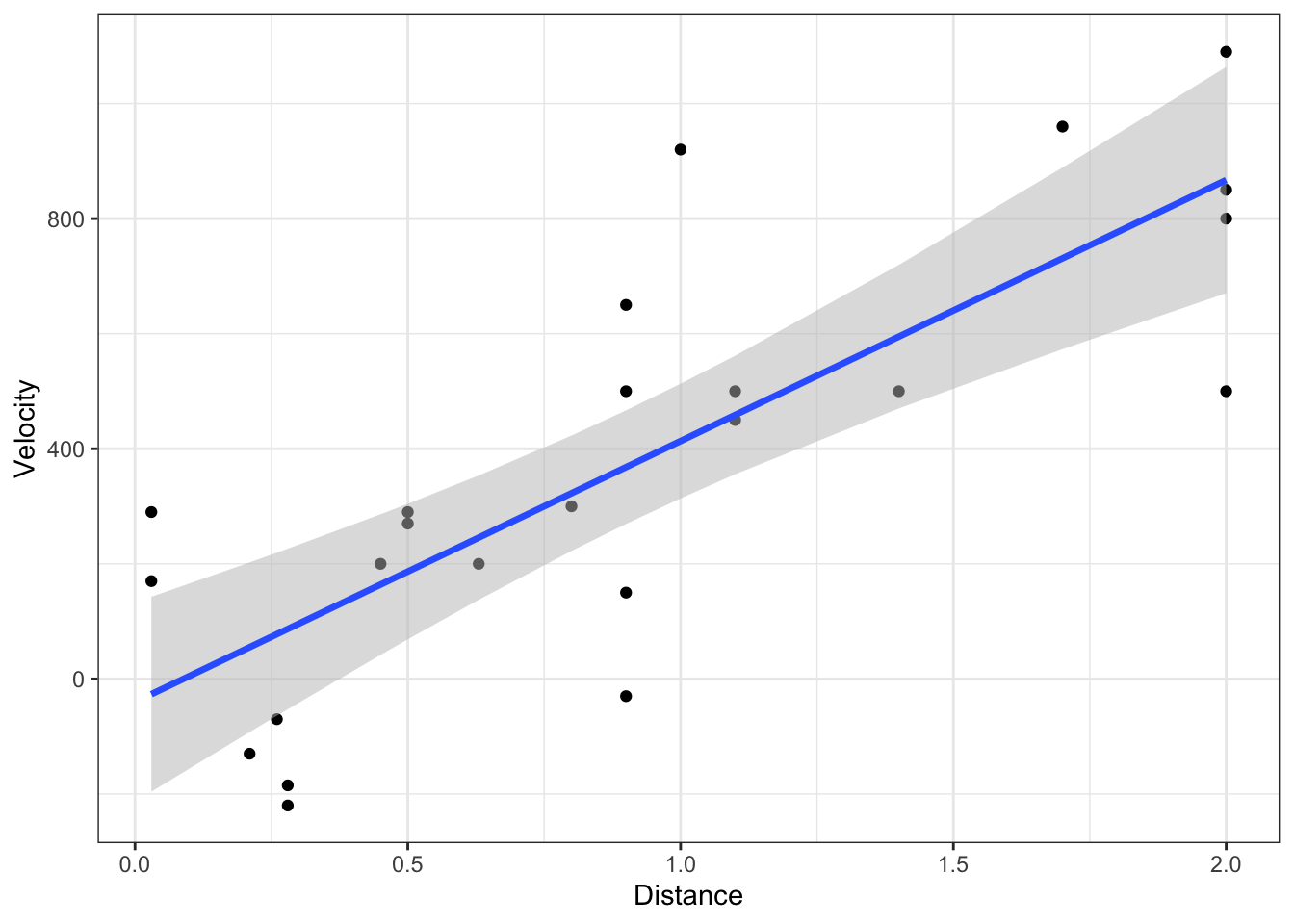
As can be seen above, these confidence intervals match geom_smooth(method = "lm") exactly. Thus, geom_smooth(method = "lm") is producing these confidence intervals.
If we want to reproduce the results of geom_smooth(method = "lm"), we can do so using geom_ribbon() and geom_line().
This was a lot more work than simply using geom_smooth(method = "lm"), but the following example will show why we were interested in constructing these uncertainty intervals ourselves.
35.1.4 Logarithms
Knowing how to construct these ribbon plots can be helpful when we want to plot data on the original scale (with non-logarithmic axes).
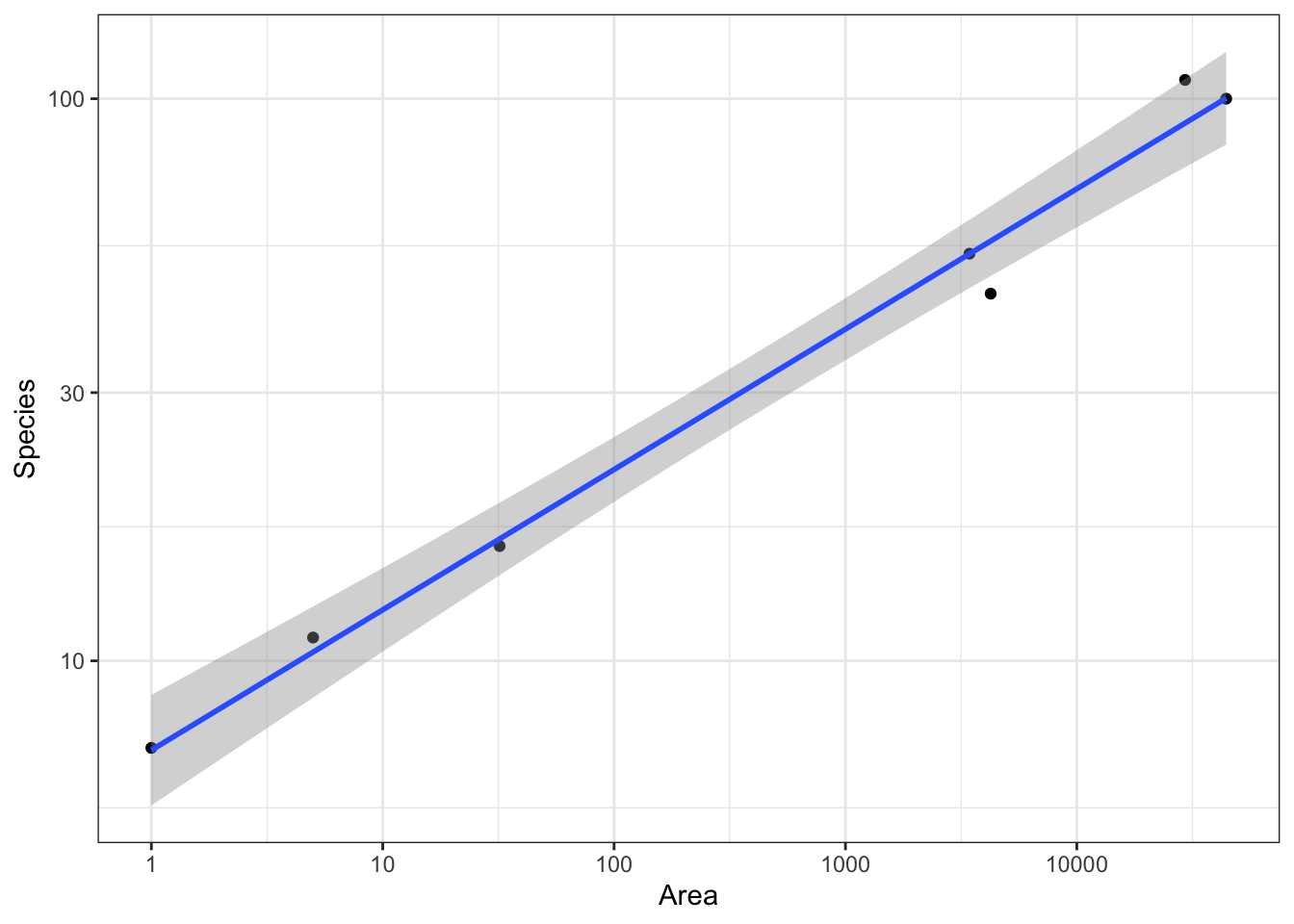
In this example data, the best fit is when both response and explanatory variable have a logarithmic transformation. Using geom_smooth(method = "lm") when both axes are logarithmic will result in a straight line on this log-log scale.
# Log-log axesg <-ggplot(case0801,aes(x = Area,y = Species )) +geom_point() g +geom_smooth(method ="lm") +scale_x_log10() +scale_y_log10()
`geom_smooth()` using formula = 'y ~ x'
It can be hard to understand the relationship between the response and explanatory variable when both axes (or even one axis) is on a logarithmic scale.
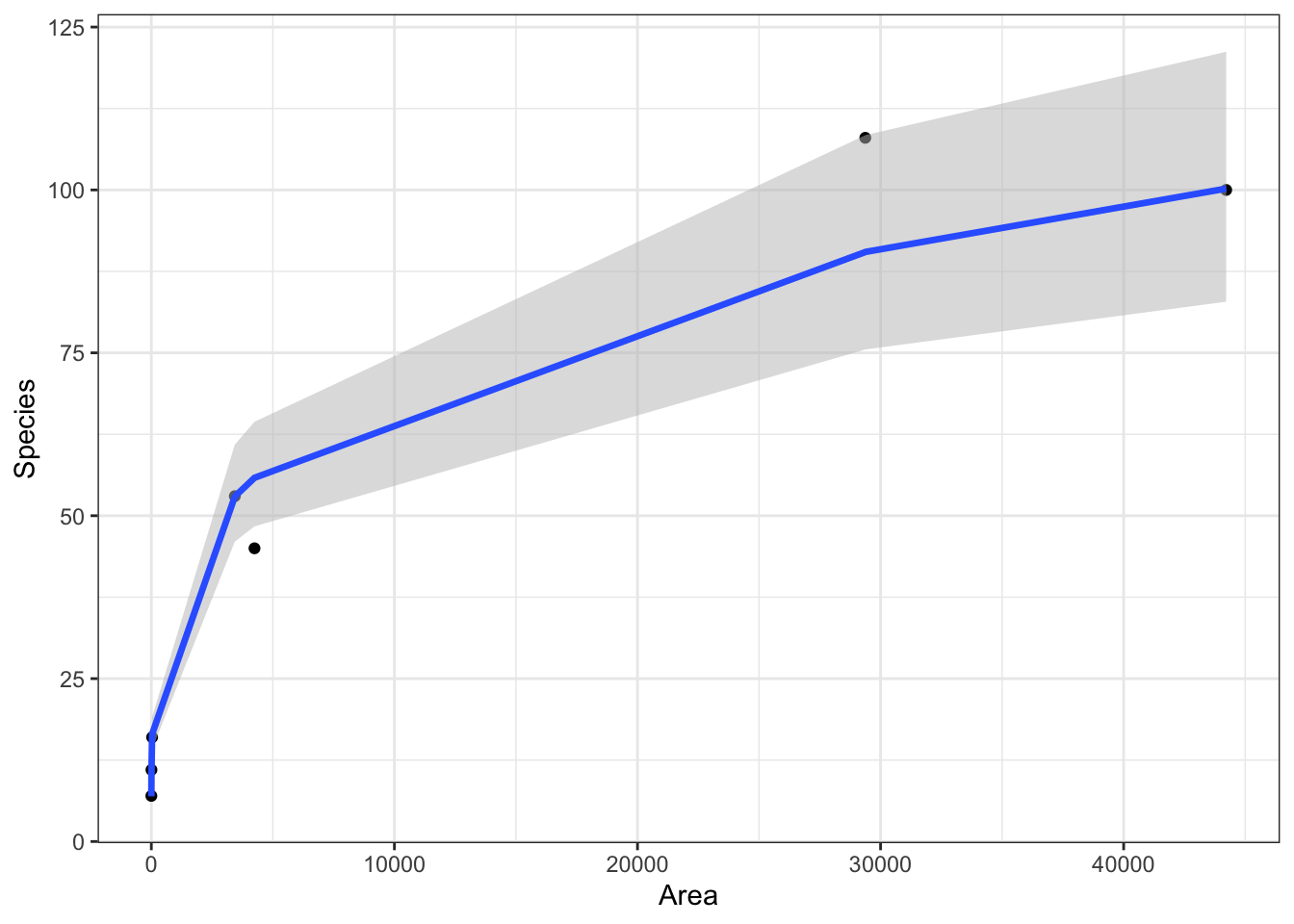
To plot everything on the original scale, we need to construct our own confidence intervals and back transform.
We can see from this plot on the original axes that the model is clearly non-linear with increasing uncertainty as the Area increases.
The piecewise linear nature of the line (and confidence intervals) is due only using 5 values of Area. If we wanted it to look smoother, we could have used more values for Area.
35.2 Categorical variable
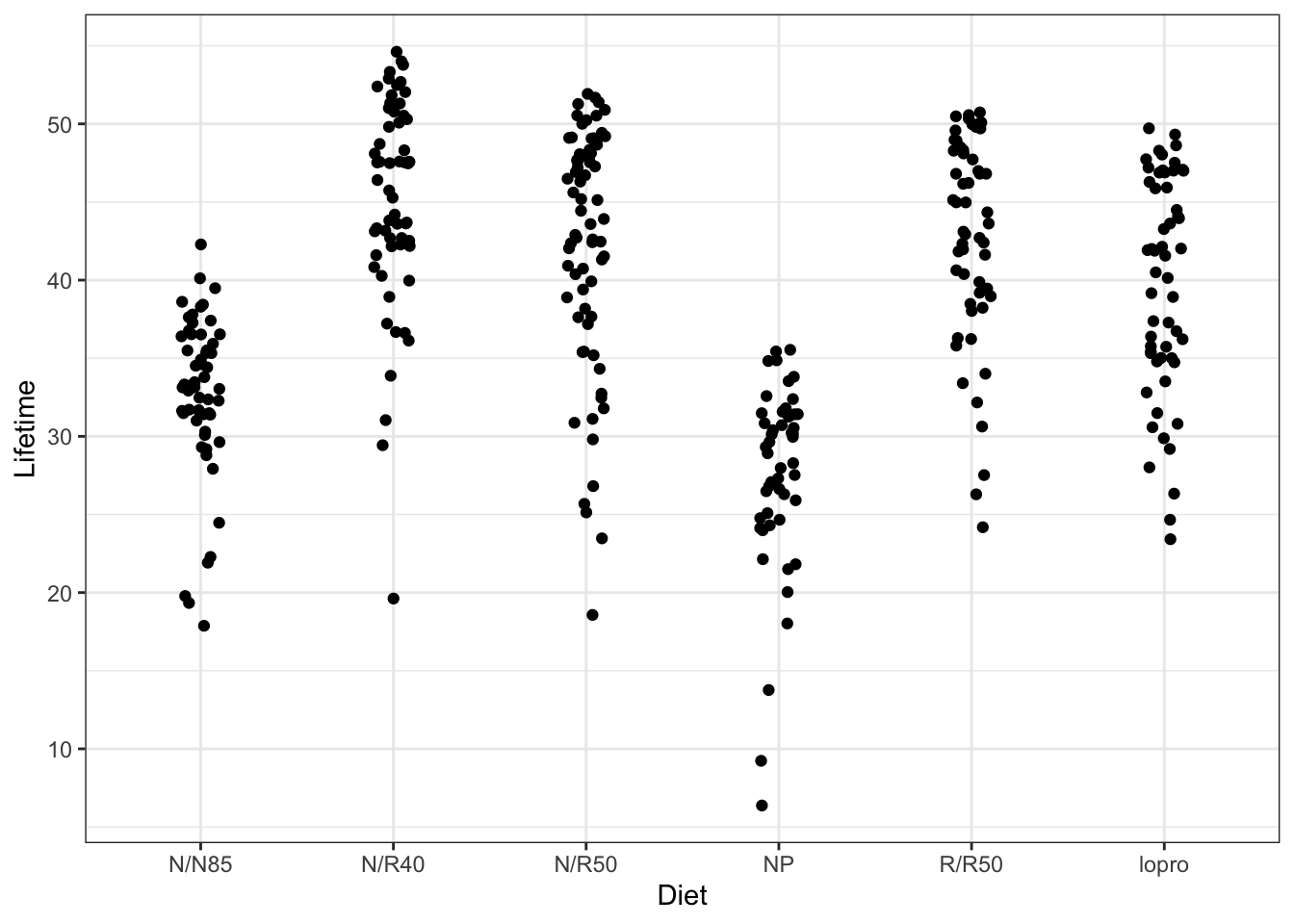
We will now consider a multiple regression model with a single categorical variable that has more than 2 levels.
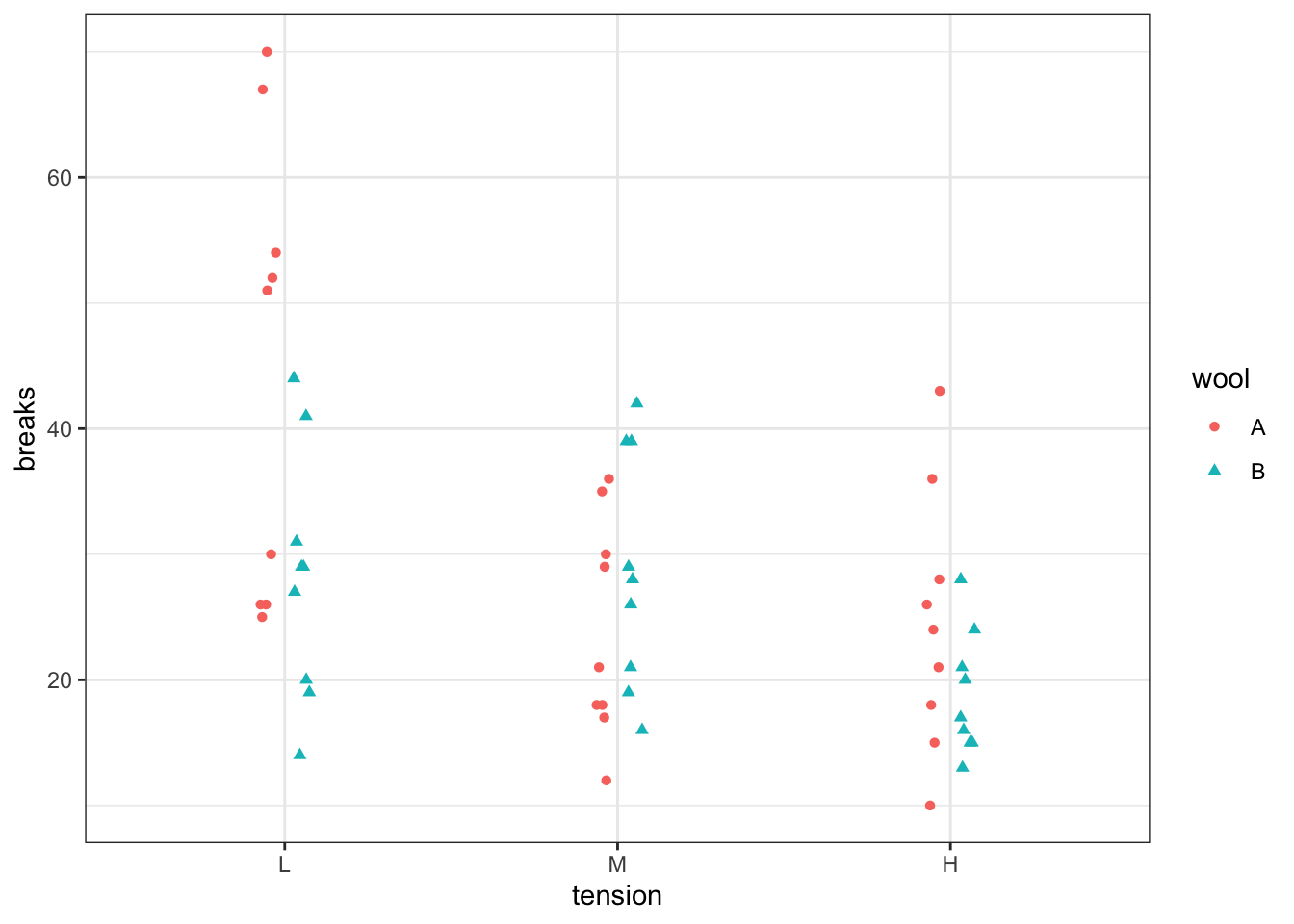
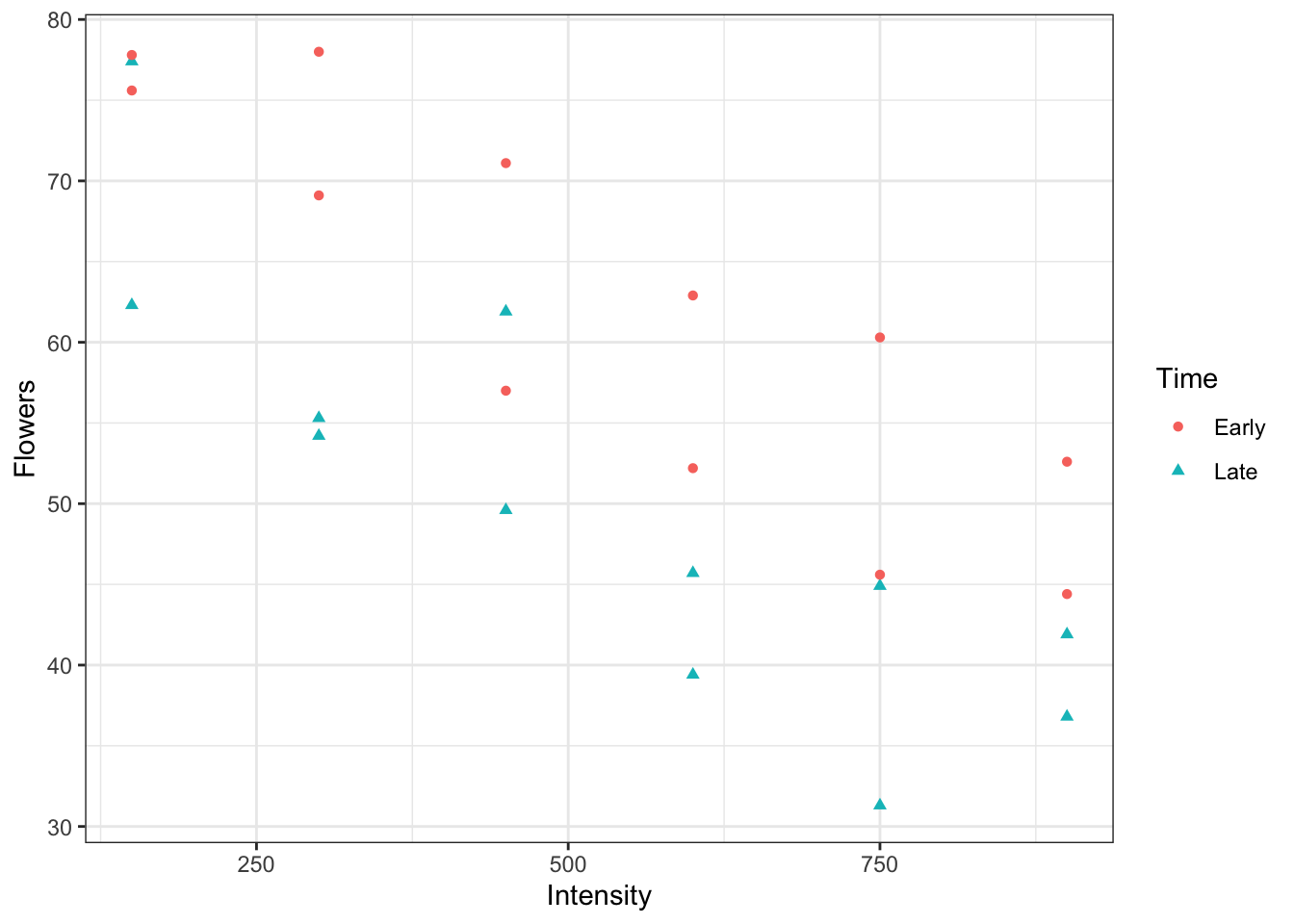
# Lifetime v Diet in miceg <-ggplot(mapping =aes(x = Diet,y = Lifetime )) +geom_jitter(data = case0501,width =0.1 )g
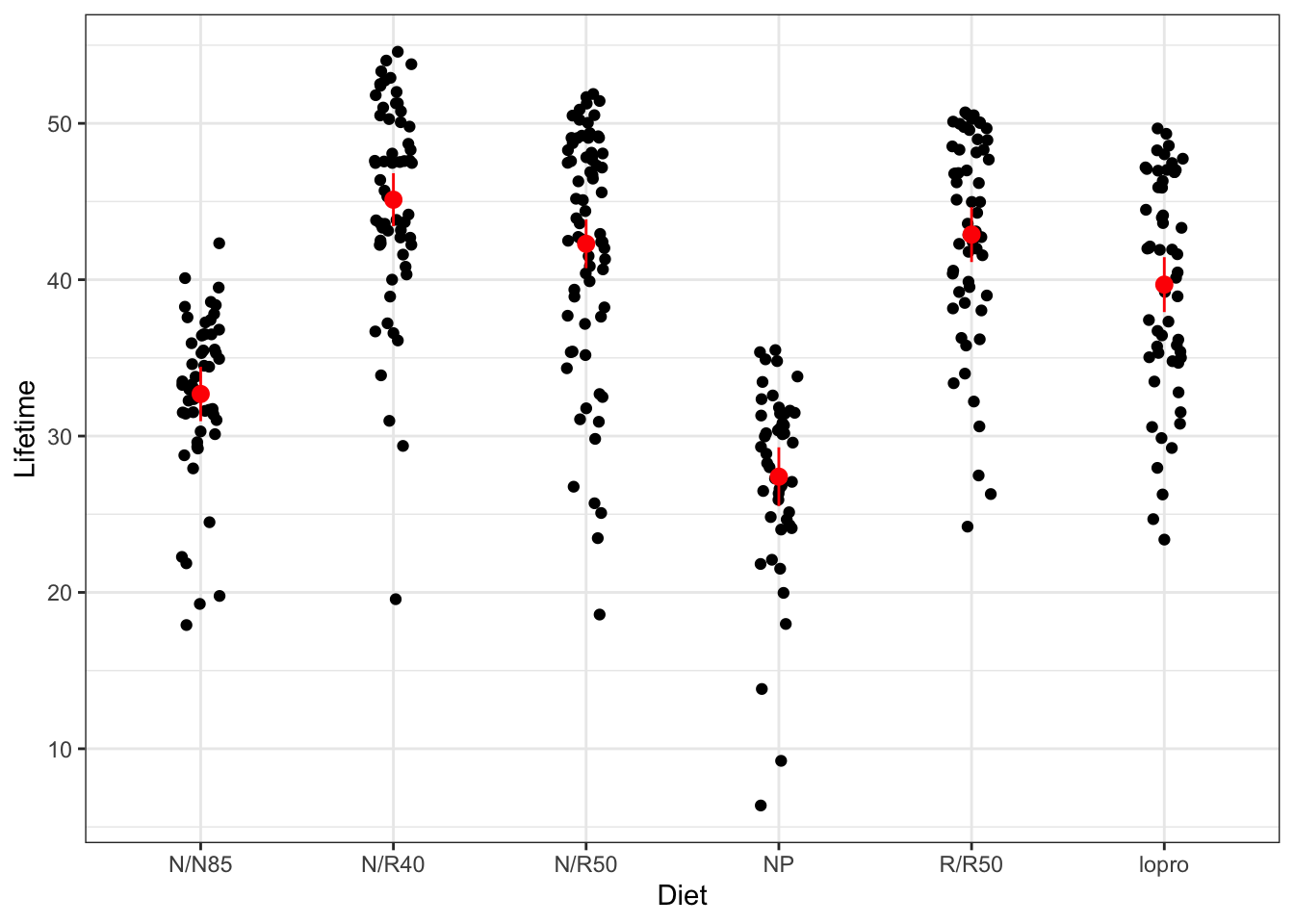
When we are using a single categorical variable, it doesn’t make any sense to use geom_smooth(method = "lm"). Instead, we will use the predict function to estimate means for each group and a confidence interval for the mean.
# Fit regression modelm <-lm(Lifetime ~ Diet, data = case0501)# Obtain unique values of Dietnd <- case0501 |>select(Diet) |>unique()# Construct confidence intervalsci <-bind_cols( nd,predict(m,newdata = nd,interval ="confidence") |>as.data.frame() |>rename(Lifetime = fit))# Add means and CIs to plotg +geom_pointrange(data = ci,aes(ymin = lwr,ymax = upr ),col ="red" )
35.3 Two categorical variables
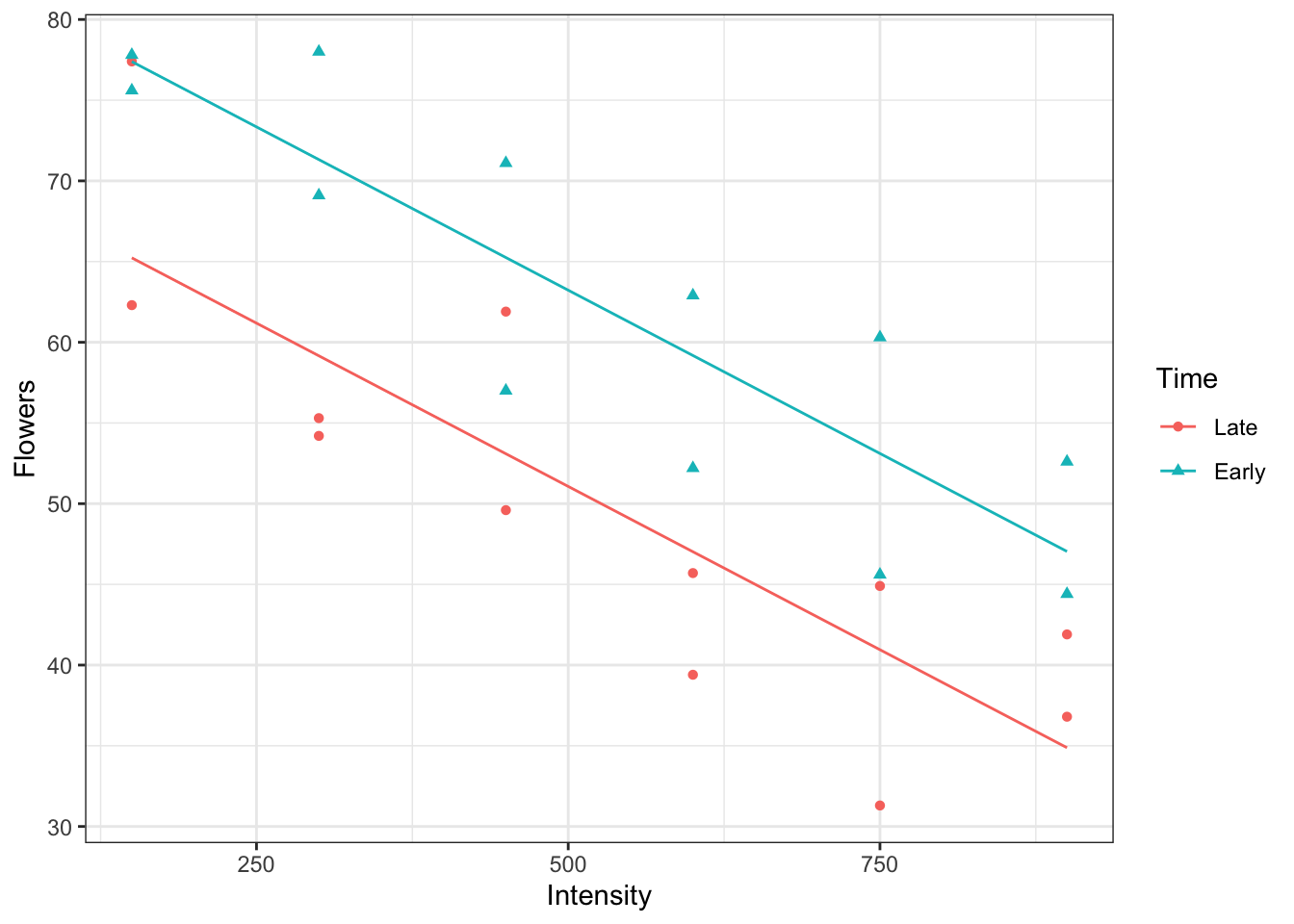
When we have two categorical explanatory variables, we have a choice of a main effects model or a model with an interaction. Briefly, the main effects model indicates that the effect of one explanatory variable on the mean response is the same regardless of the value of the other explanatory variable. In contrast, the model with an interaction indicates that the effect of one explanatory variable on the mean response depends on the value of the other explanatory variable.
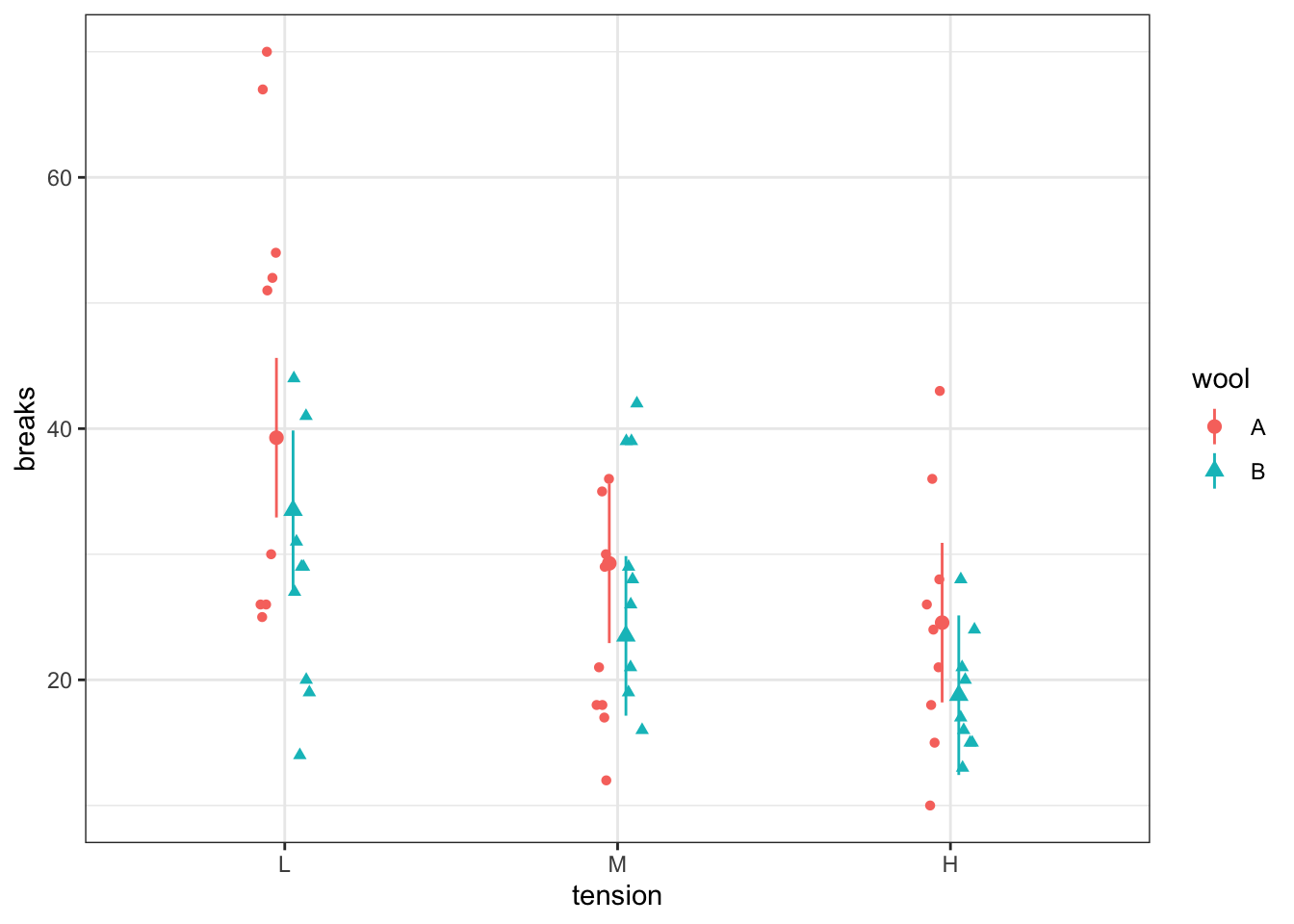
Construct confidence intervals for every combination of explanatory variable values.
# Fit main effects modelm <-lm(breaks ~ wool + tension, data = warpbreaks)# Obtain unique values of Dietnd <- warpbreaks |># Include both explanatory variablesselect(wool, tension) |>unique()# Construct confidence intervalsci <-bind_cols( nd,predict(m,newdata = nd,interval ="confidence") |>as.data.frame() |>rename(breaks = fit))# Plotgm <- g +geom_pointrange(data = ci,aes(ymin = lwr,ymax = upr ),position =position_dodge(width =0.1) )gm
The distance between the two types of wool for every tension value is the same. This is a feature of a main effects model.
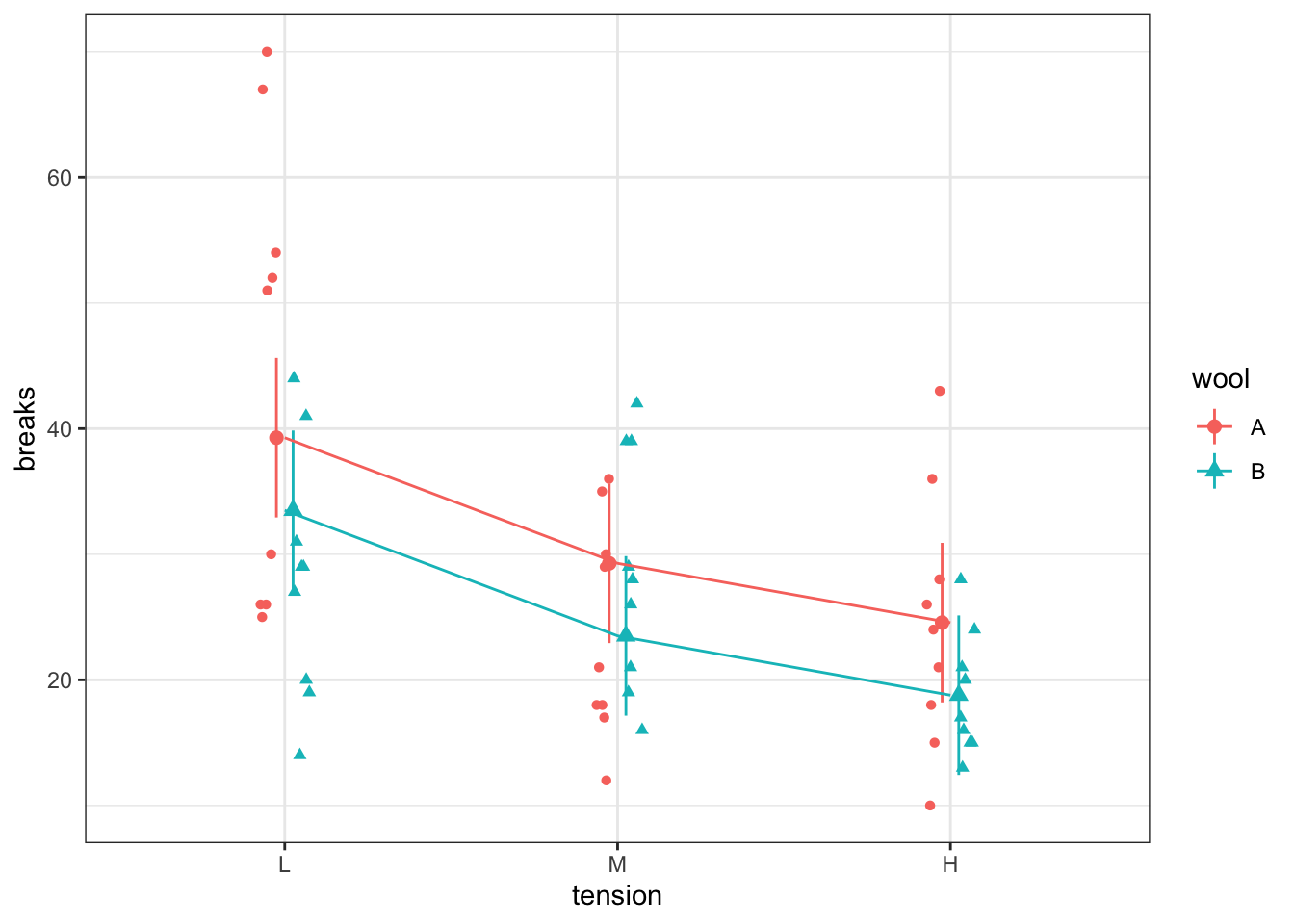
To see this, it can be helpful to add lines to connect the means
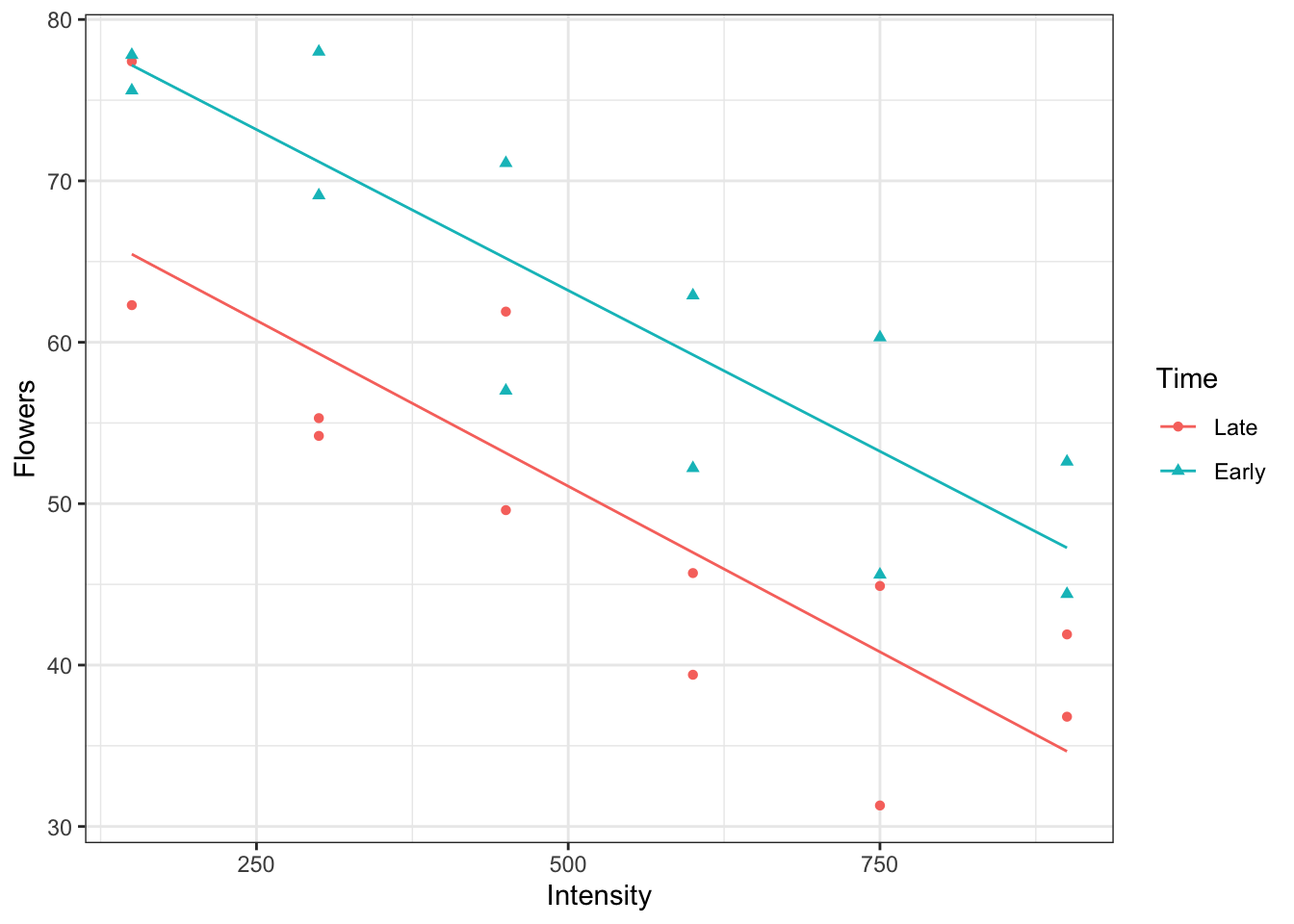
gm +geom_line(data = ci,aes(group = wool ) )
Notice how the line segments are parallel. This is a feature of a main effects model with two categorical variables.
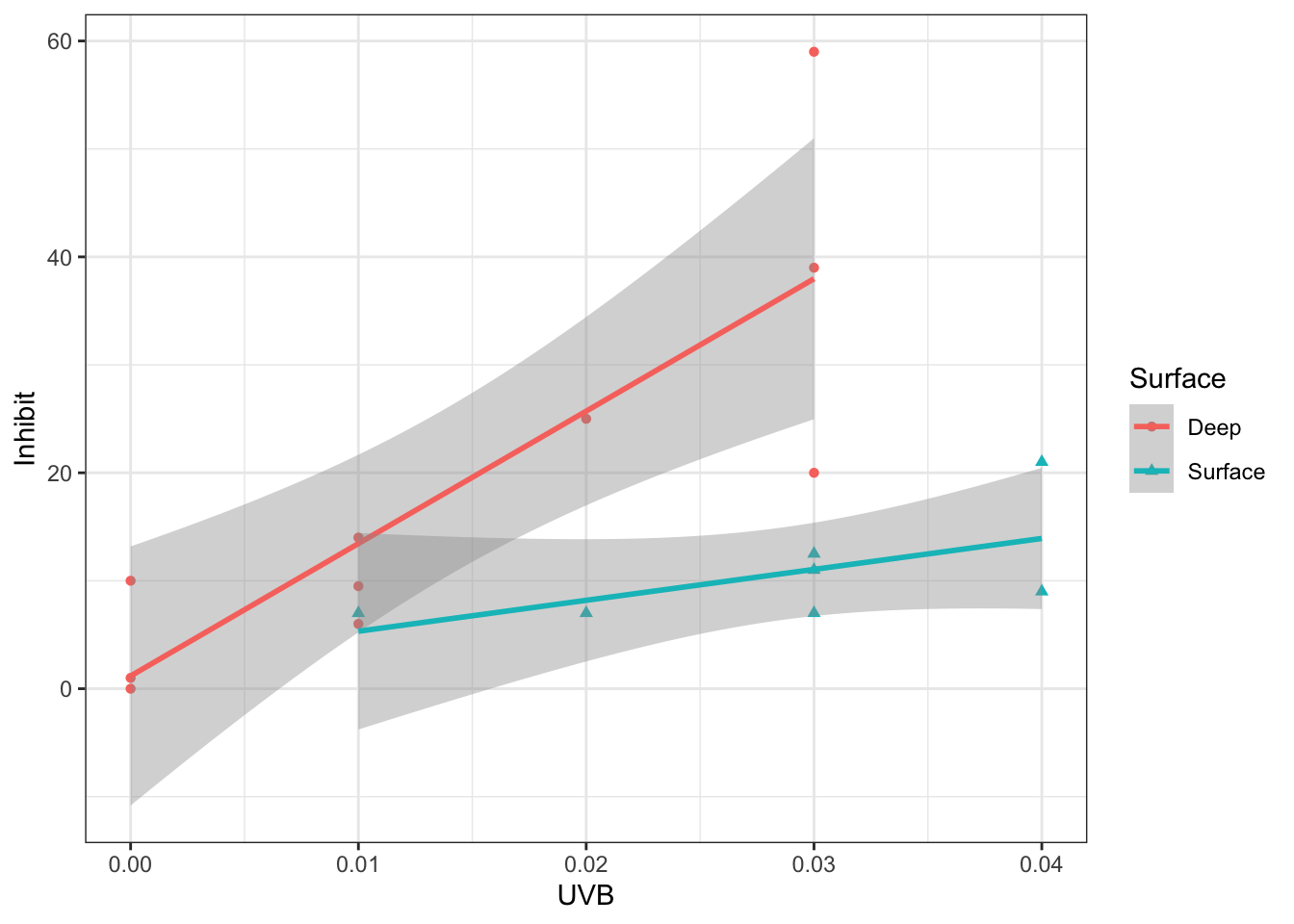
35.3.2 Interactions
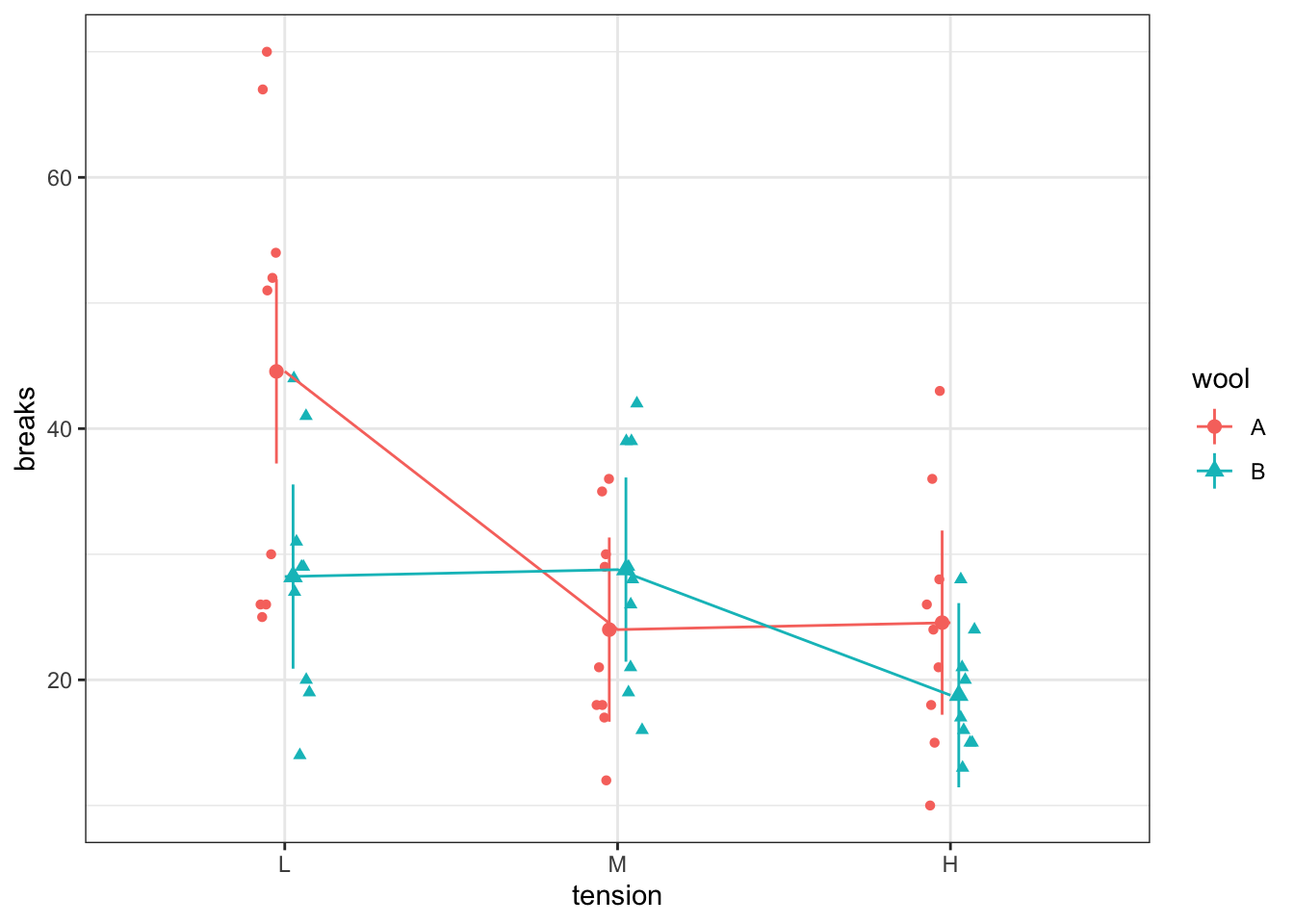
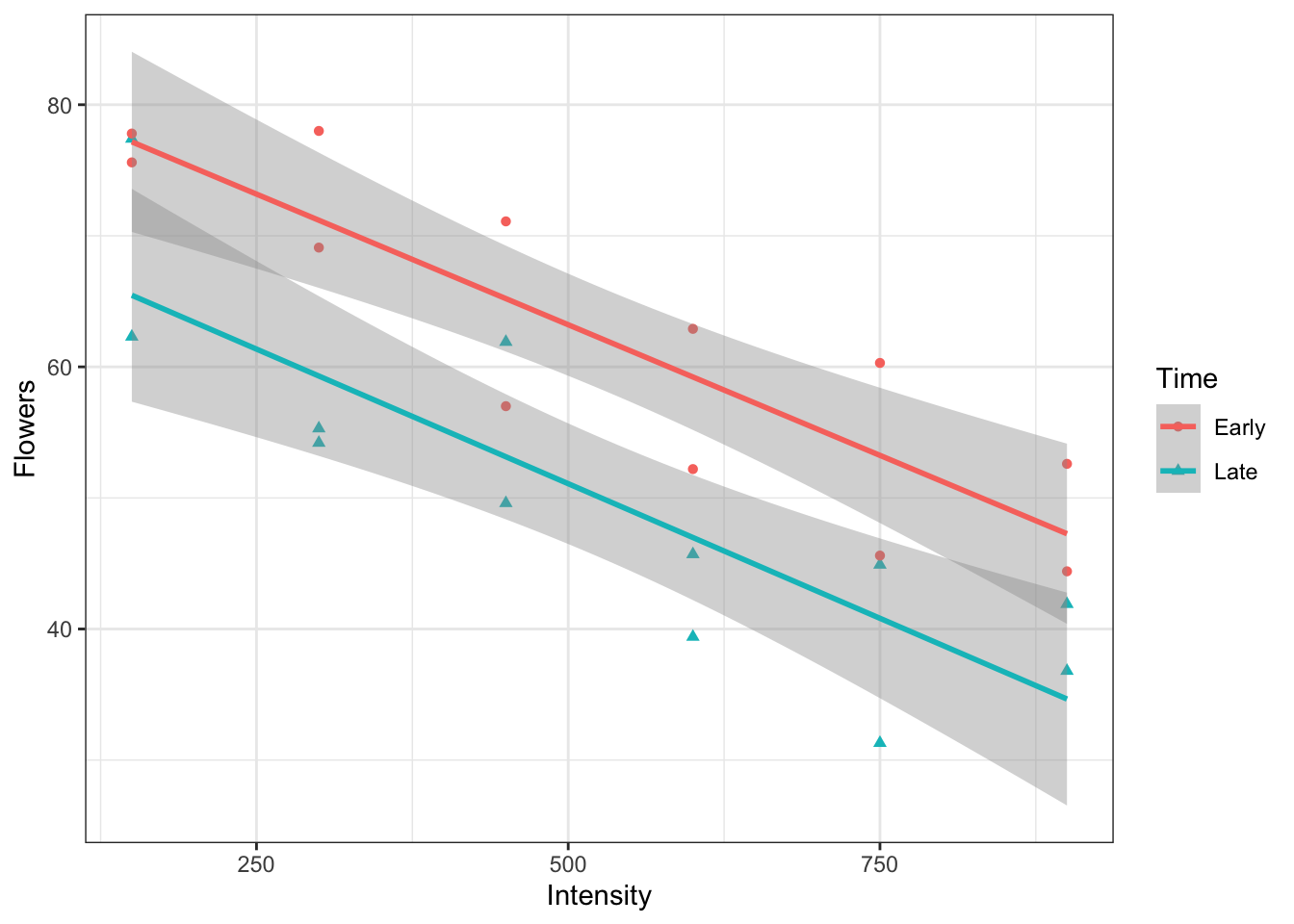
Now let’s consider a model with an interaction. There are two ways to indicate that this is the model you would like to fit. One way is to include the interaction term directly while the other way is a shorthand
In this plot, notice how the line segments are no longer forced to be parallel. Since the data suggest the lines should not be parallel, we would expect a test for the interaction to be significant.
The large p-value for the interaction term suggests that the interaction term is not necessary to describe these data.
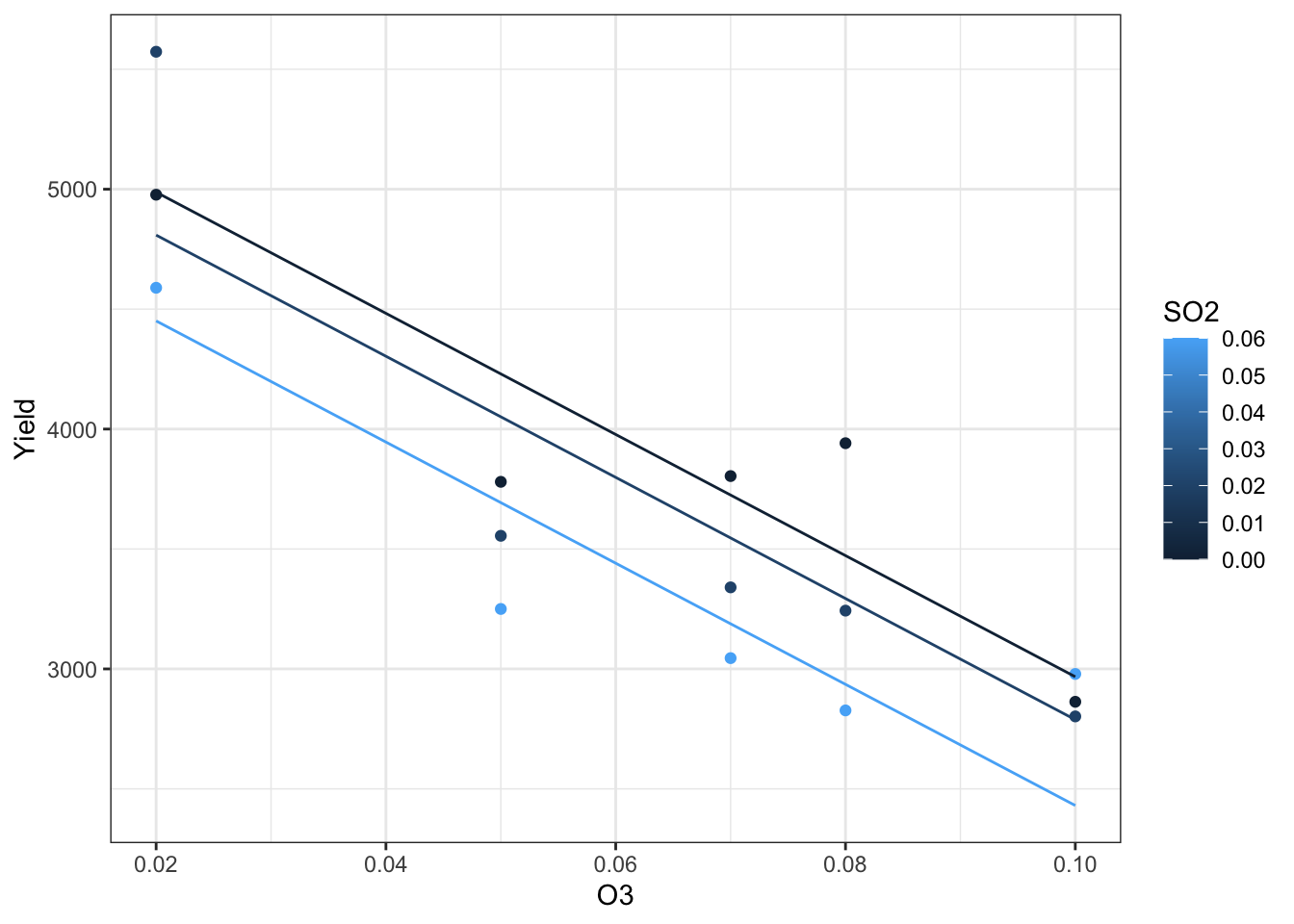
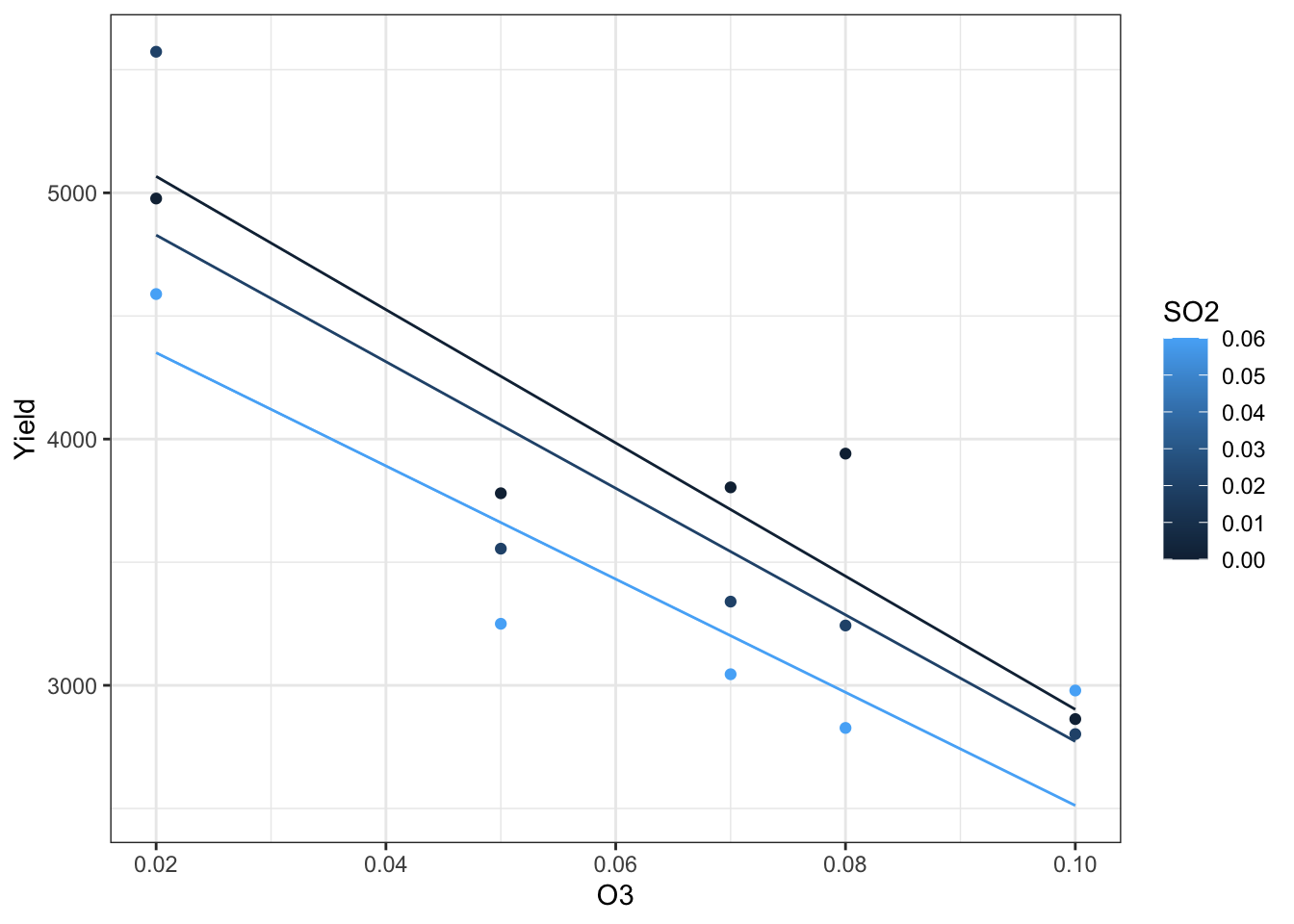
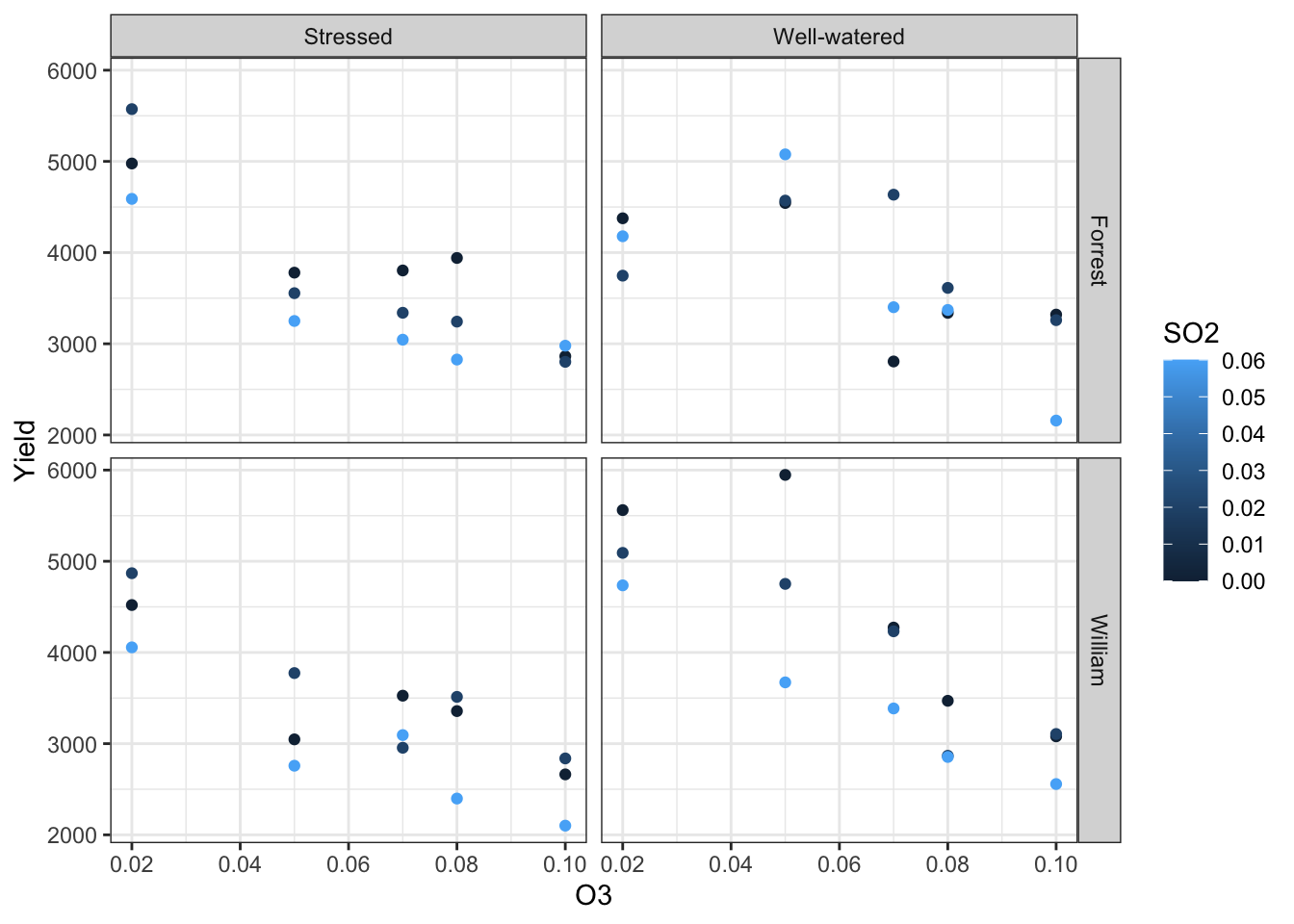
35.6 More than two variables
Regression models can be fit with more than two variables. To visualize what is occurring, you want to utilize a combination of shape/linetype, color, and faceting.
Here is one example with two continuous explanatory variables and two categorical explanatory variables.
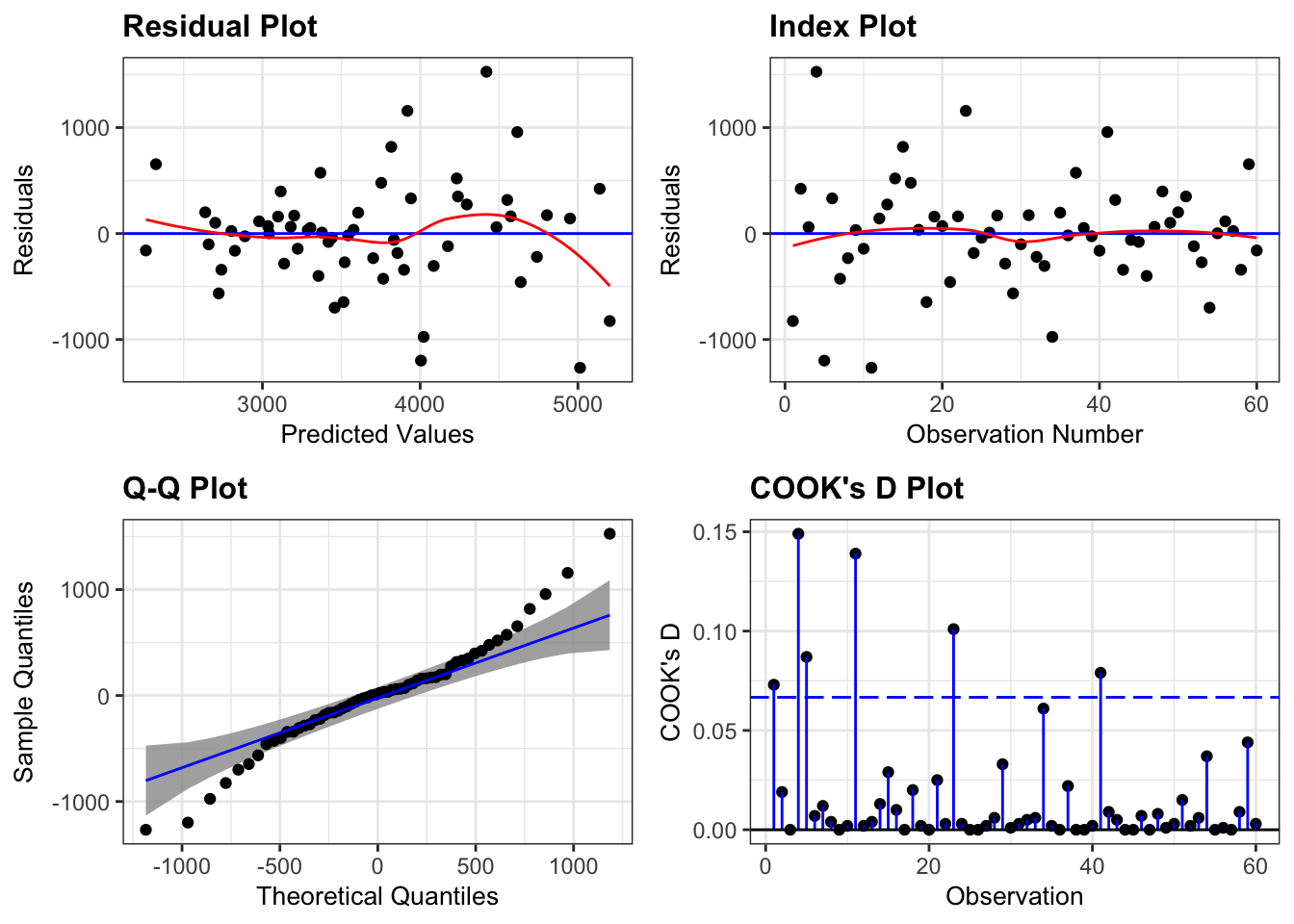
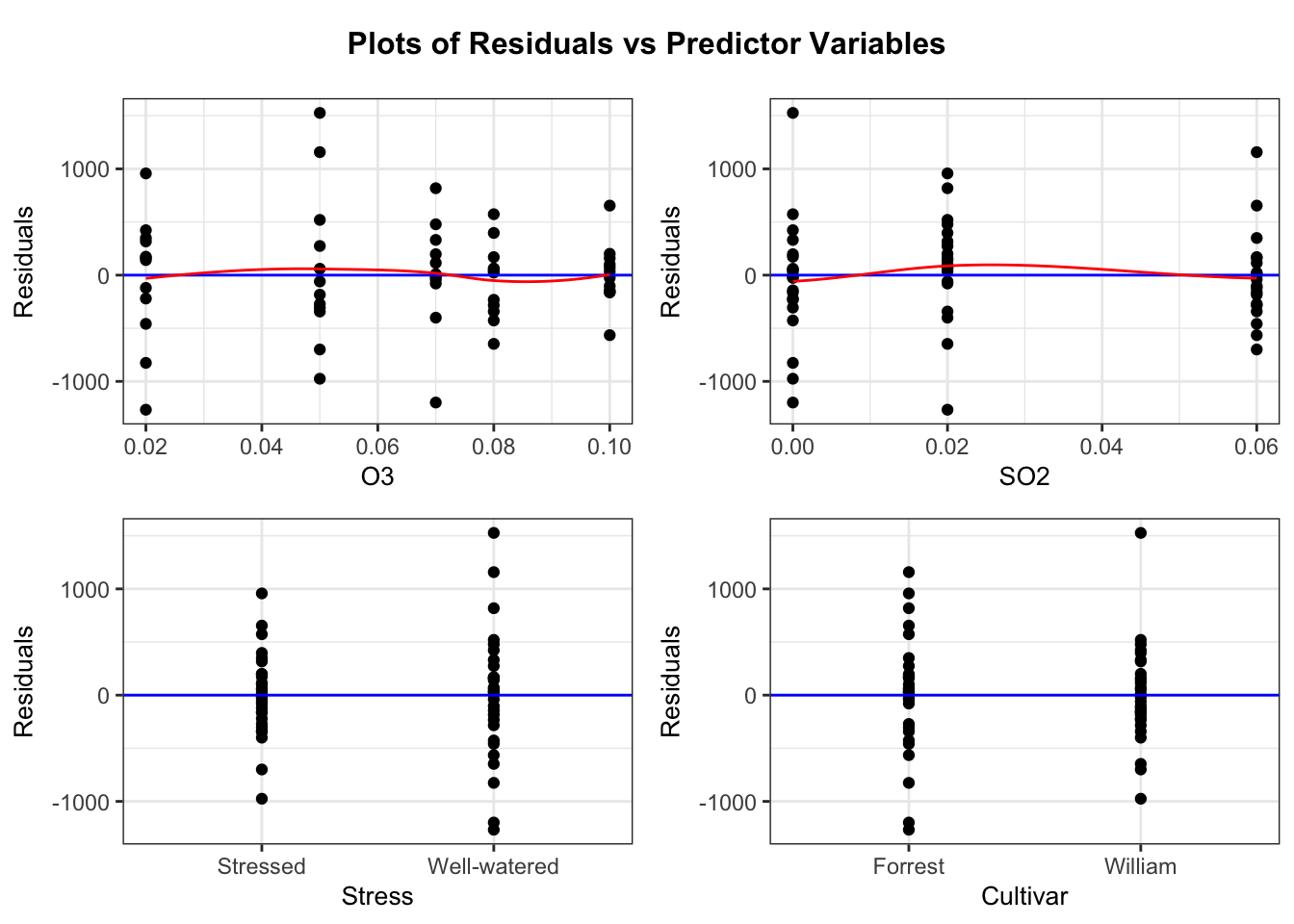
Remember to assess model assumptions using diagnostic plots.
m <-lm(Yield ~ O3 + SO2 + Stress + Cultivar, data = d)resid_panel(m,plots =c("resid", "index", "qq", "cookd"),qqbands =TRUE,smoother =TRUE)
`geom_smooth()` using formula = 'y ~ x'
`geom_smooth()` using formula = 'y ~ x'
resid_xpanel(m,smoother =TRUE)
`geom_smooth()` using formula = 'y ~ x'
`geom_smooth()` using formula = 'y ~ x'
`geom_smooth()` using formula = 'y ~ x'
`geom_smooth()` using formula = 'y ~ x'
These diagnostics plots do not tell you precisely what you need to do, but they may indicate deviations from current model assumptions. You may need to include interaction terms or perform transformations (e.g. logarithms) to obtain a better model fit.
35.7 Summary
In this discussion, we emphasized the use to plotting to understand regression models and utilized geom_smooth(method = "lm") and predict() to understand model assumptions regarding the mean structure. Please remember to also check model diagnostics for error assumptions and influential observations.