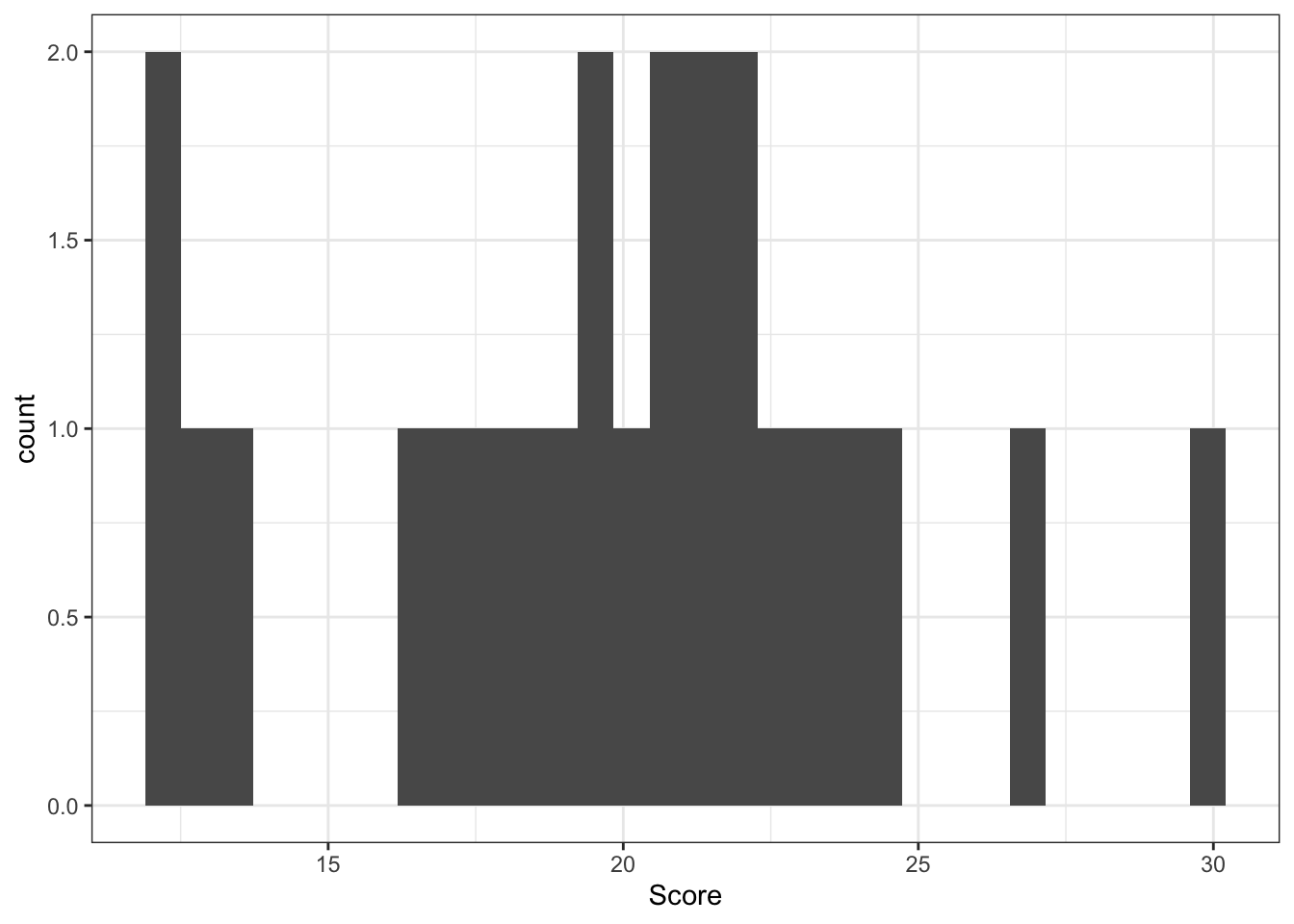
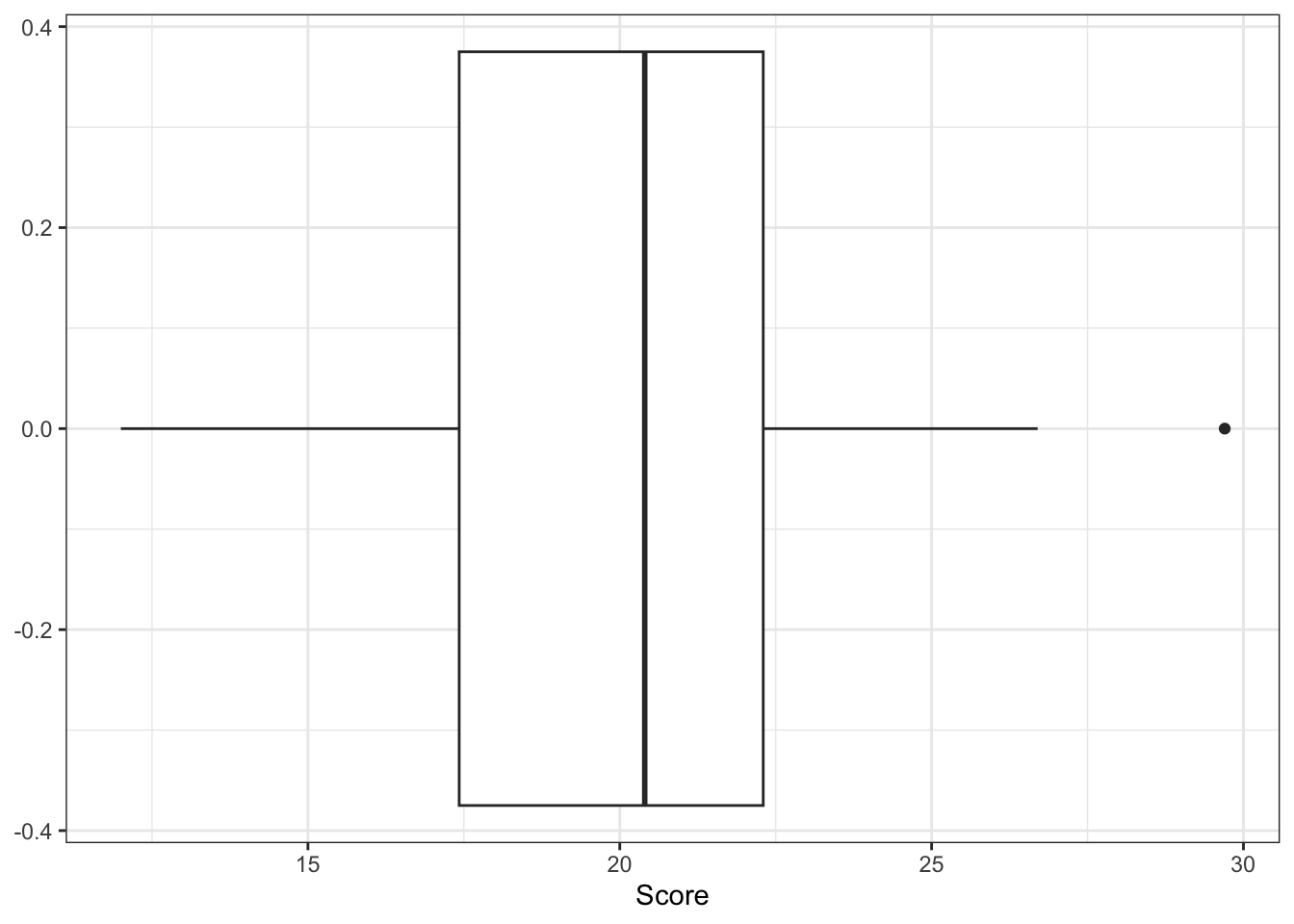
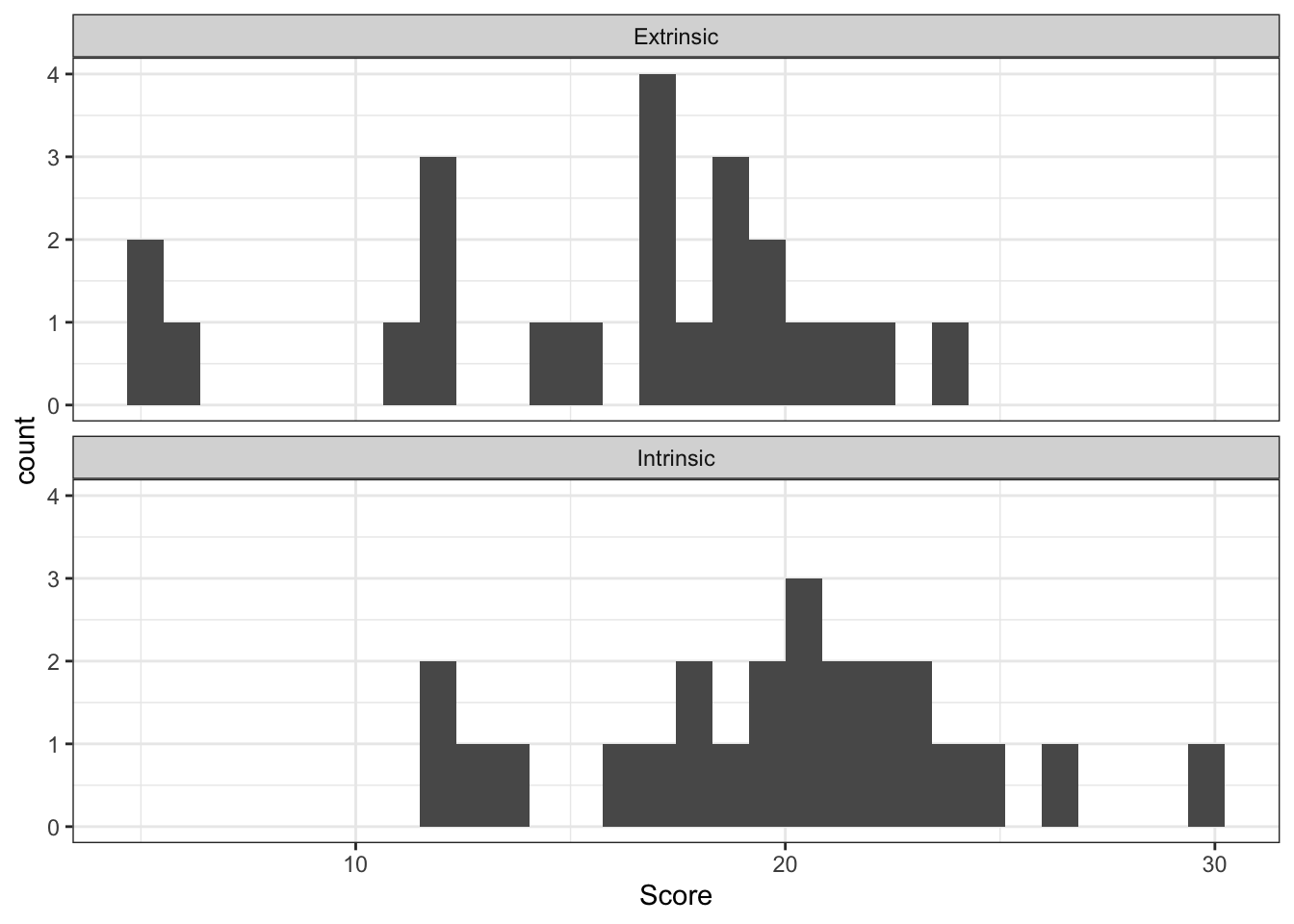
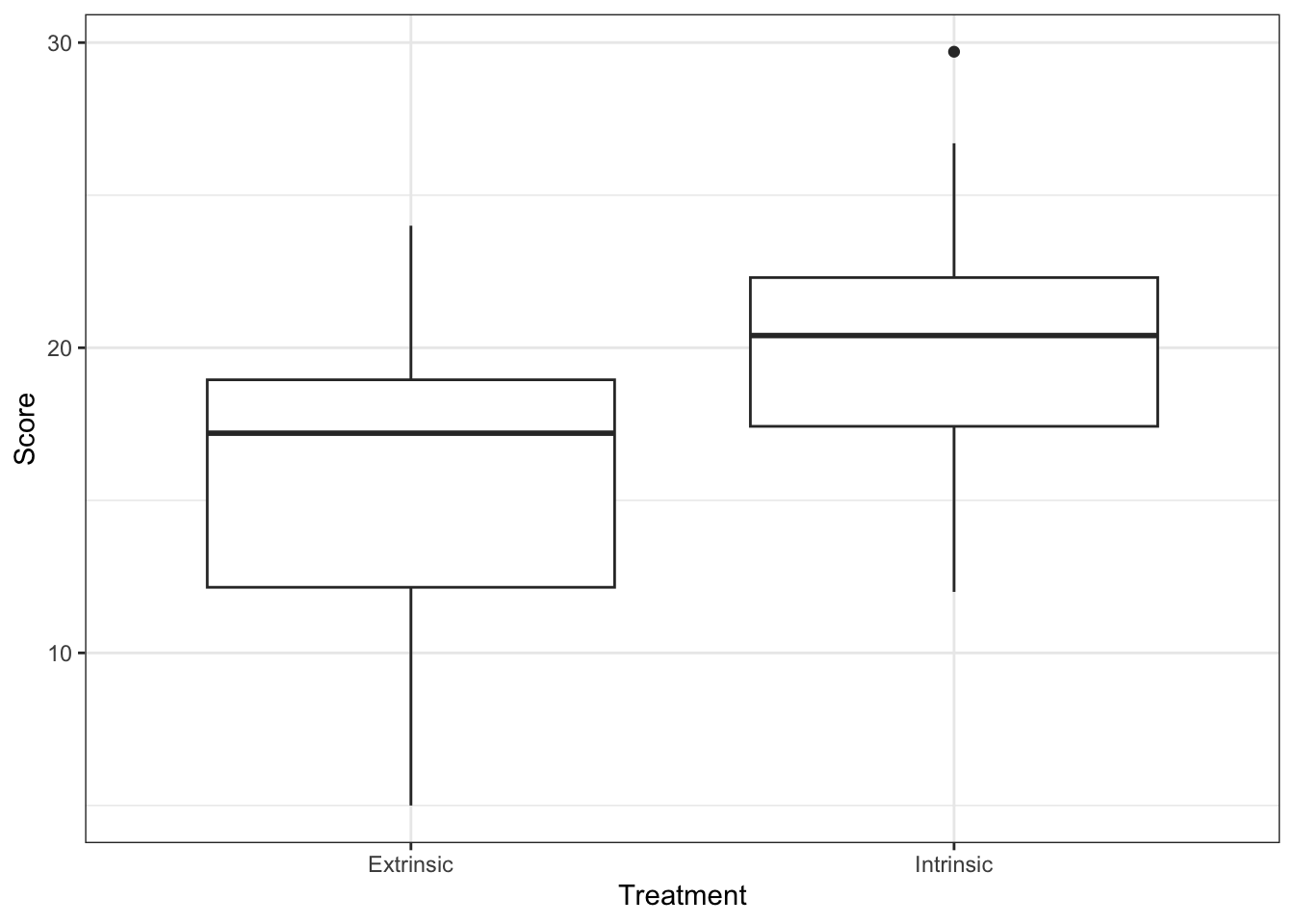
Normal analyses are (typically) relevant for independent, continuous observations. These observations may need to be transformed to satisfy assumptions of normality. Most commonly by taking a logarithmic transformation of our data.
library("tidyverse"); theme_set(theme_bw())
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library("Sleuth3")
32.1 One group
The single group normal analysis begins with the assumptions \[
Y_i \stackrel{ind}{\sim} N(\mu,\sigma^2)
\] for \(i=1,\ldots,n\).
An alternative way to write this model is \[
Y_i = \mu + \epsilon_i, \qquad \epsilon_i \stackrel{ind}{\sim} N(0,\sigma^2)
\]
In a one-sample t-test, we are typically interested in the hypothesis \[
H_0: \mu = \mu_0
\] for some value \(\mu_0\).
# One-sample t-testt.test(Score ~1, data = creativity)
One Sample t-test
data: Score
t = 21.941, df = 23, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
18.00869 21.75798
sample estimates:
mean of x
19.88333
To extract objects from this object, checkout the names() of the object.
# Save output as an R objectt <-t.test(Score ~1, data = creativity)# Check out the names of the objectnames(t)
If you are interested in an alternative value for \(\mu_0\), a different alternative hypothesis, or a different confidence level, there are arguments that can be adjusted.
# t.test argumentst <-t.test(creativity$Score, mu =20, alternative ="greater", conf.level =0.9)t # print
One Sample t-test
data: creativity$Score
t = -0.12874, df = 23, p-value = 0.5507
alternative hypothesis: true mean is greater than 20
90 percent confidence interval:
18.68762 Inf
sample estimates:
mean of x
19.88333
32.2 Two groups
When you have two groups and they are independent, a common assumption is
\[
Y_{gi} \stackrel{ind}{\sim} N(\mu_g, \sigma_g^2)
\] for \(i = 1, \ldots, n_g\) and \(g=1,2\). Alternatively
As you look at these summary statistics, you can start to evaluate model assumptions. From these plots and summary statistics, it appears the two data sets have approximately equal variance while the means are likely different.
32.2.2 Test and confidence intervals
Typically we are interested in the hypothesis \[
H_0: \mu_1 = \mu_2 \qquad \mbox{or, equivalently,} \qquad H_0: \mu_1-\mu_2 = 0
\] and a confidence interval for the difference \(\mu_1-\mu_2\).
32.2.2.1 Unequal variances
To run the test, we again use the t.test() function, By default, this function assumes the variances are unequal.
t.test(Score ~ Treatment, data = case0101)
Welch Two Sample t-test
data: Score by Treatment
t = -2.9153, df = 43.108, p-value = 0.005618
alternative hypothesis: true difference in means between group Extrinsic and group Intrinsic is not equal to 0
95 percent confidence interval:
-7.010803 -1.277603
sample estimates:
mean in group Extrinsic mean in group Intrinsic
15.73913 19.88333
Given our visualization of the data earlier, it is unsurprising that our p-value is small indicating evidence against the model that assumes the means of the two groups are equal.
32.2.2.2 Equal variances
Often, we will make the assumption that the two groups have equal variances.
# Assume variances are equalt <-t.test(Score ~ Treatment, data = case0101, var.equal =TRUE)t
Two Sample t-test
data: Score by Treatment
t = -2.9259, df = 45, p-value = 0.005366
alternative hypothesis: true difference in means between group Extrinsic and group Intrinsic is not equal to 0
95 percent confidence interval:
-6.996973 -1.291432
sample estimates:
mean in group Extrinsic mean in group Intrinsic
15.73913 19.88333
When we assume the two variances are equal, our results are very similar.
Like we did with the one-group data, we can extract objects from the object create with the t.test() function.
# Group meanst$estimate
mean in group Extrinsic mean in group Intrinsic
15.73913 19.88333
# Degrees of freedomt$parameter # n - 2
df
45
# Standard errort$stderr
[1] 1.416397
# t-statistict$statistic
t
-2.925876
with(t, -diff(estimate) / stderr)
mean in group Intrinsic
-2.925876
# p-value and null valuet$p.value
[1] 0.005366476
t$null.value
difference in means between group Extrinsic and group Intrinsic
0
# Estimated standard deviationwith(t, stderr *sqrt(parameter +1))
df
9.606474
# Confidence interval for the meant$conf.int # Group 1 (Extrinsic) - Group 2 (Intrinsic)
A paired analysis can be used when the data have a natural grouping structure into a pair of observations. Within each pair of observations, one observation has one level of the explanatory variable while the other observation has the other level of the explanatory variable.
In the following example, the data are naturally paired because each set of observations is on a set of identical twins. One twin has schizophrenia while the other does not. These data compares the volume of the left hippocampus to understand its relationship to schizophrenia.
32.2.3.1 Summary statistics
We could compare summary statistics separately for all individuals.
summary(case0202)
Unaffected Affected
Min. :1.250 Min. :1.02
1st Qu.:1.600 1st Qu.:1.31
Median :1.770 Median :1.59
Mean :1.759 Mean :1.56
3rd Qu.:1.935 3rd Qu.:1.78
Max. :2.080 Max. :2.02
The power in these data arises from the use of pairing. In order to make use of this pairing we should compute the difference (or ratio) for each pair.
For plotting, it is useful to wrangling the data into a longer format.
# Prepare data for plottingschizophrenia <- case0202 |>mutate(pair = LETTERS[1:n()]) |># Create a variable for the pairpivot_longer(-pair, names_to ="diagnosis", values_to ="volume")
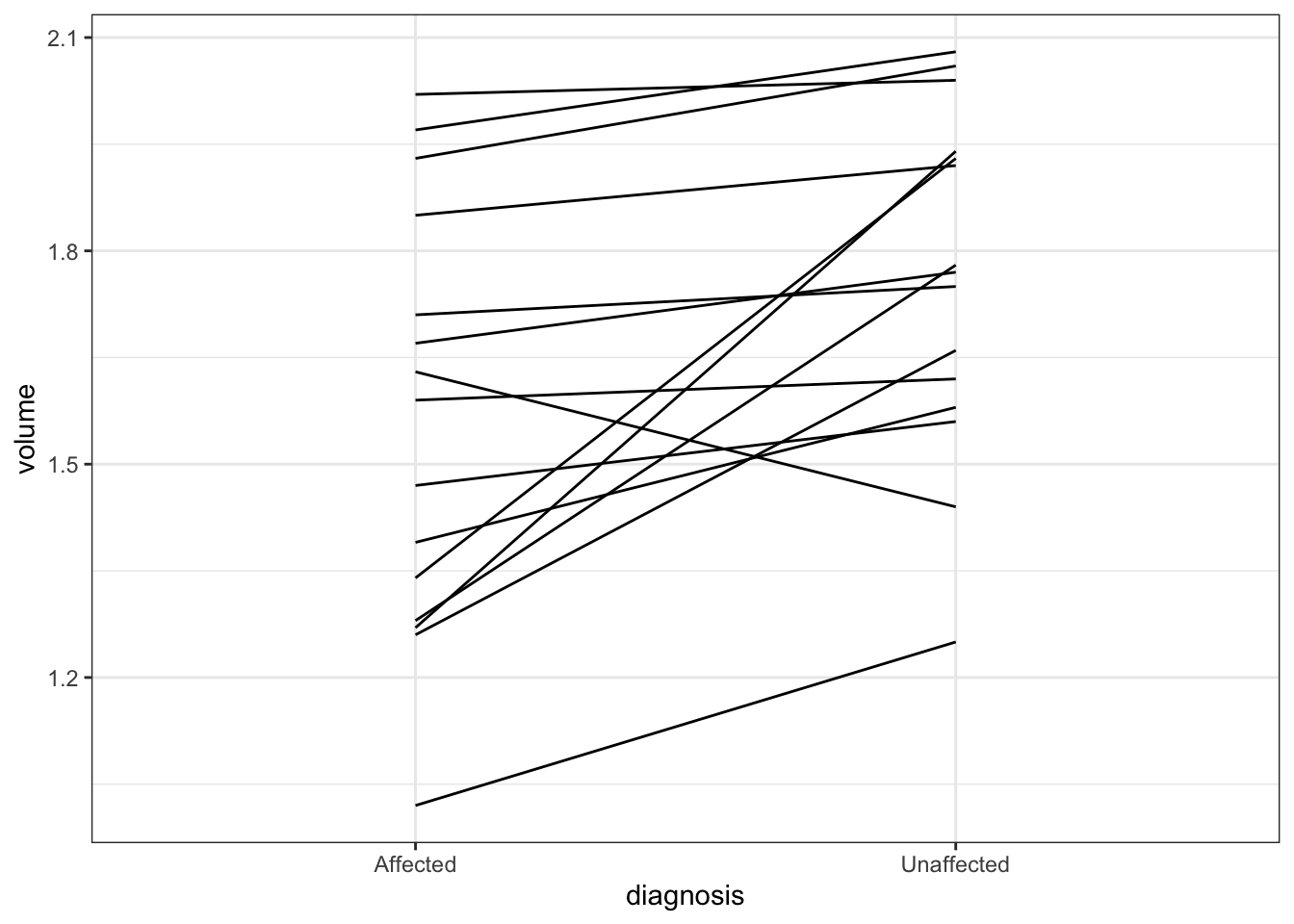
In this plot, each pair is a line with the affected twin on the left and the unaffected twin on the right.
ggplot(schizophrenia, aes(x = diagnosis, y = volume, group = pair)) +geom_line()
It is important to connect these points between each twin because we are looking for a pattern amongst the pairs.
32.2.3.2 Paired t-test
When the data are paired, we can perform a paired t-test.
Paired t-test
data: case0202$Unaffected and case0202$Affected
t = 3.2289, df = 14, p-value = 0.006062
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
0.0667041 0.3306292
sample estimates:
mean difference
0.1986667
This analysis is equivalent to taking the difference in each pair and performing a one-sample t-test.
# One-sample t-test on the differencet.test(case0202$Unaffected - case0202$Affected)
One Sample t-test
data: case0202$Unaffected - case0202$Affected
t = 3.2289, df = 14, p-value = 0.006062
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.0667041 0.3306292
sample estimates:
mean of x
0.1986667
32.3 More than two groups
If we have a single categorical variable with more than two groups, then \(G > 2\).
32.3.1 Summary statistics
# More than two-groups datacase0501 |>group_by(Diet) |>summarize(n =n(),mean =mean(Lifetime),sd =sd(Lifetime),.groups ="drop" )
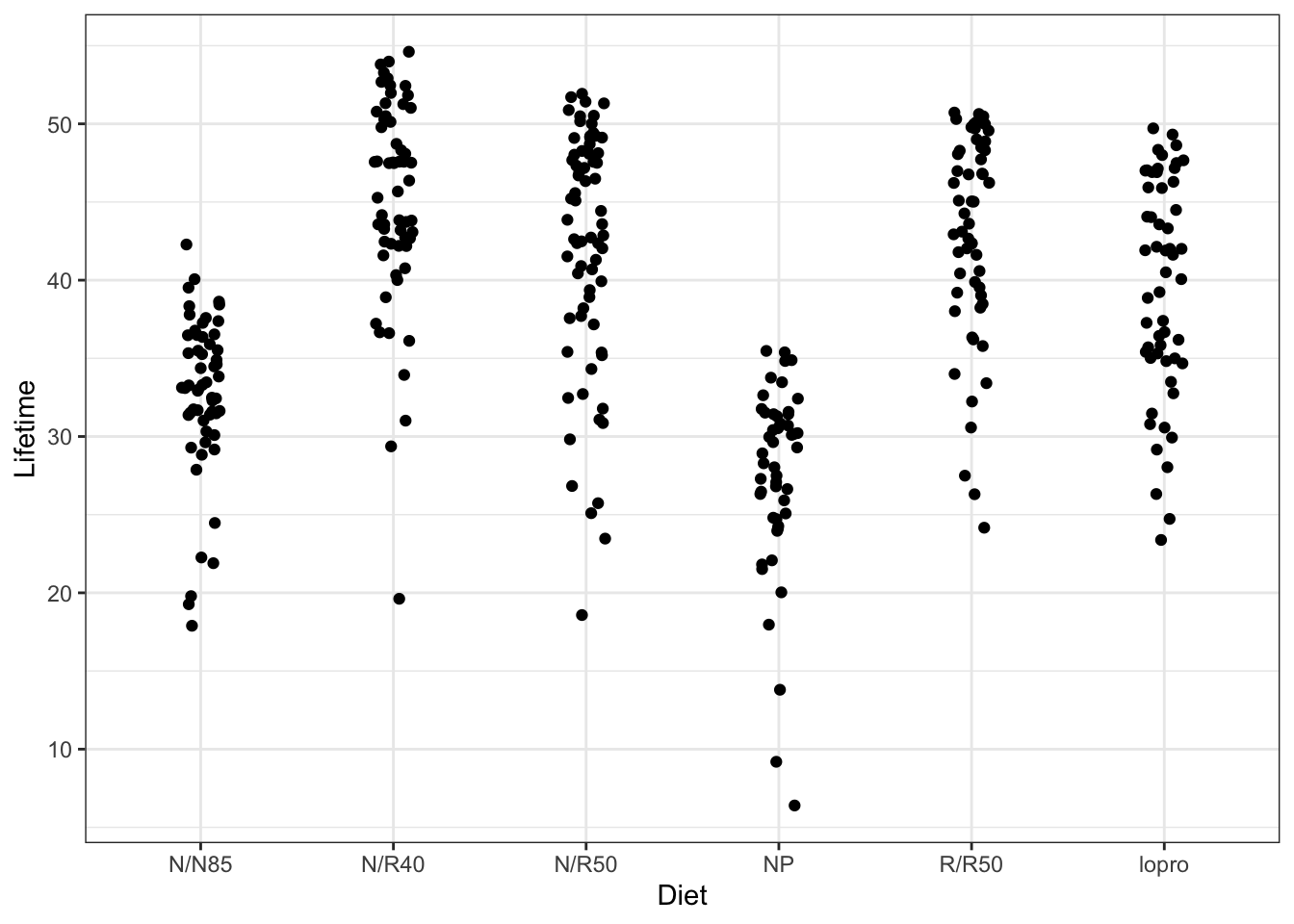
# Jitterplotggplot(case0501, aes(x = Diet, y = Lifetime)) +geom_jitter(width =0.1)
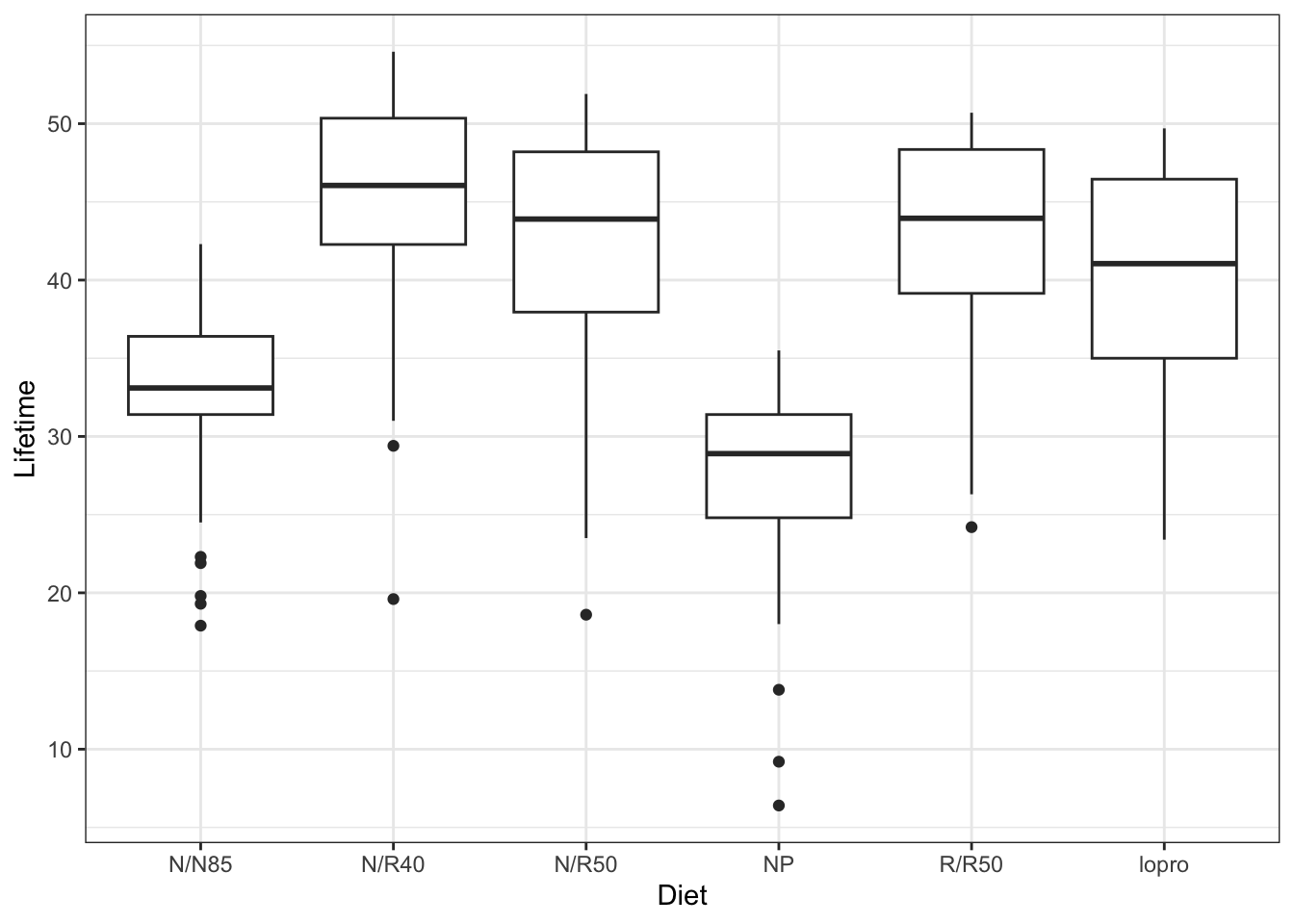
# Boxplotsggplot(case0501, aes(x = Diet, y = Lifetime)) +geom_boxplot()
We can see from these boxplots that the data appear a bit left-skewed, but that the variability in each group is pretty similar.
32.3.2 ANOVA
An ANOVA F-test considers the following null hypothesis \[
H_0: \mu_g = \mu \quad \forall\, g
\]
# ANOVAm <-lm(Lifetime ~ Diet, data = case0501)anova(m)
Analysis of Variance Table
Response: Lifetime
Df Sum Sq Mean Sq F value Pr(>F)
Diet 5 12734 2546.8 57.104 < 2.2e-16 ***
Residuals 343 15297 44.6
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
32.4 Summary
We introduced a number of analyses for normal (continuous) data depending on how many groups we have and the structure of those groups. In the future, we will introduce linear regression models that can be used for continuous data. We will see that these models allow us to perform all of the analyses above and analyze data with a more complicated structure.