── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
The vast majority of Monte Carlo simulations aim to estimate either an expectation or a probability. The formulas we use for these two are both based on the Central Limit Theorem, but the formulas different depending on whether we are estimating an expectation or a probability.
28.1 Expectation
If we have \(X_i\) for \(i=1,\ldots,n\) that are independent and identically distributed with \(E[X_i] = \mu\) and \(Var[X_i] = \sigma^2 < \infty\), then \[
\frac{\overline{X}-\mu}{S/\sqrt{n}} \stackrel{d}{\to} N(0,1) \quad \mbox{as } n\to \infty.
\] where \(\overline{X}\) is the sample average and \(S\) is the sample standard deviation.
Thus, for large enough n, \[
\overline{X} \stackrel{\cdot}{\sim} N(\mu, s^2/n)
\] where \(\stackrel{\cdot}{\sim}\) expectations “approximately distributed.”
This result is the basis of a common asymptotic confidence interval formula for \(\mu = E[X_i]\): \[
\overline{x} \pm z_{\alpha/2} \, s/\sqrt{n}
\] where \(z_{\alpha/2}\) is a critical value that depends on the confidence level (\(1-\alpha/2\)) of the confidence interval.
As a reminder, the term \(s/\sqrt{n}\) is often referred to as the standard error (SE) and \(z_{\alpha/2}s/\sqrt{n}\) as the margin of error.
28.1.1 Functions
Let’s first make a function to construct the data.frame we’ll need to plot to visualize
# Create data.frame that contains # n: number of simulations# xbar: cumulative expectation# s: cumulative standard deviation# se: cumulative standard error# lcl: cumulative lower confidence limit of confidence interval# ucl: cumulative upper confidence limit of confidence intervalcreate_expectation_dataframe <-function(x, alpha =0.05) {data.frame(n =1:length(x)) %>%mutate(xbar =cumsum(x) / n,s =sqrt(cumsum( (x-xbar)^2 ) / (n-1)),se = s/sqrt(n), lcl = xbar -qnorm( 1- alpha/2 ) * se,ucl = xbar +qnorm( 1- alpha/2 ) * se )}
As long as we’re at it, let’s make a function to create the plot
# Function to cumulative expectation with confidence intervalplot_expectation <-function(d, truth =NULL) { g <-ggplot(d, aes(x = n, y = xbar, ymin = lcl, ymax = ucl)) +geom_ribbon(fill ="blue", alpha =0.3) +geom_line(color ="blue")if (!is.null(truth)) g <- g +geom_hline(yintercept = truth, color ="red", linetype =2)return(g)}
28.1.2 Examples
28.1.2.1 Normal expectation
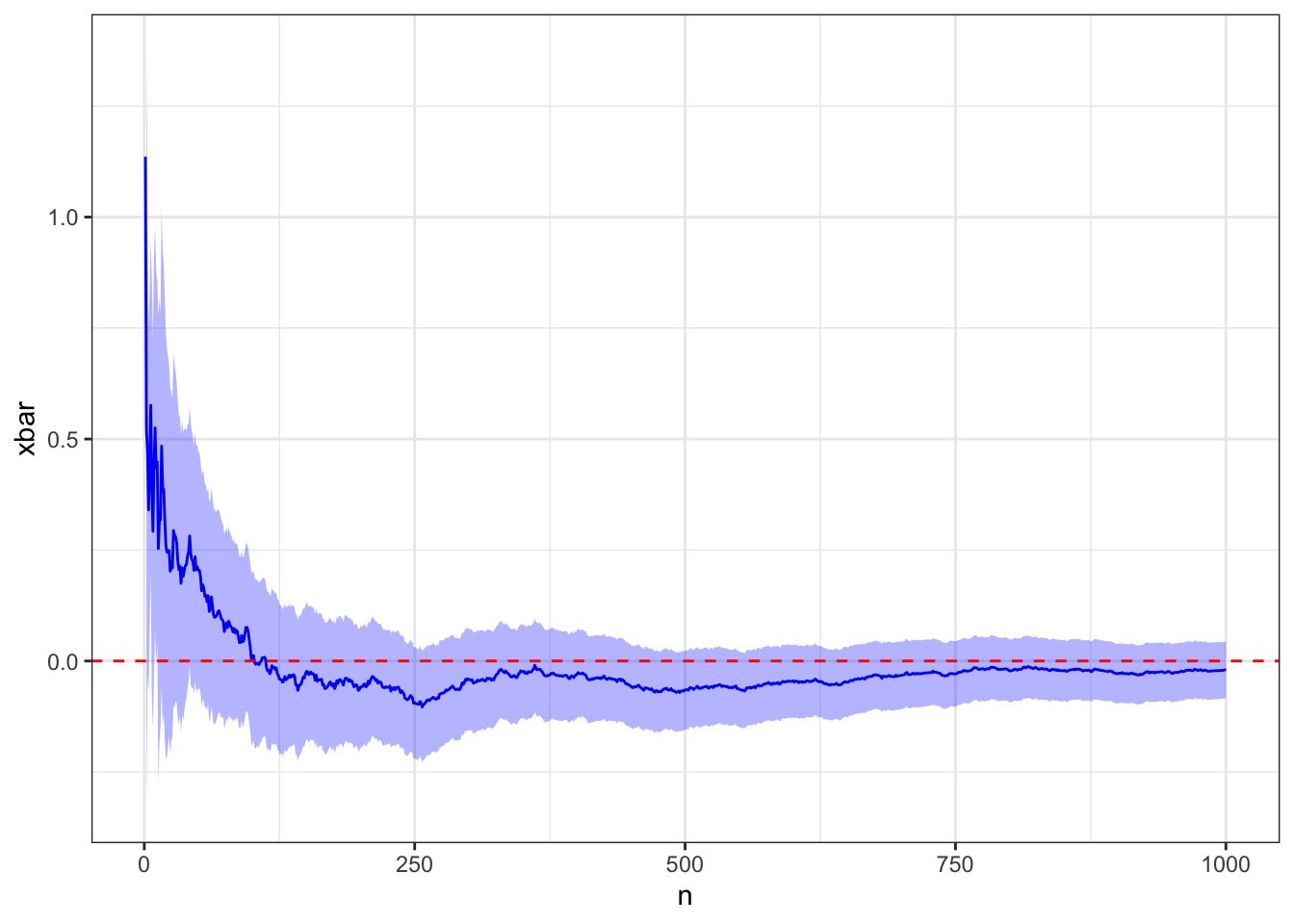
Let \(X_i \stackrel{ind}{\sim} N(\mu, \sigma^2)\). If we sample enough \(X_i\), then we can learn about \(\mu\).
# Pick these values m <-0# true expectations <-1# true standard deviation# Simulate datax <-rnorm(1e3, mean = m, sd = s)# Create and plot Monte Carlo estimatesd <-create_expectation_dataframe(x)plot_expectation(d, truth = m)
28.1.2.2 Truncated normal expectation
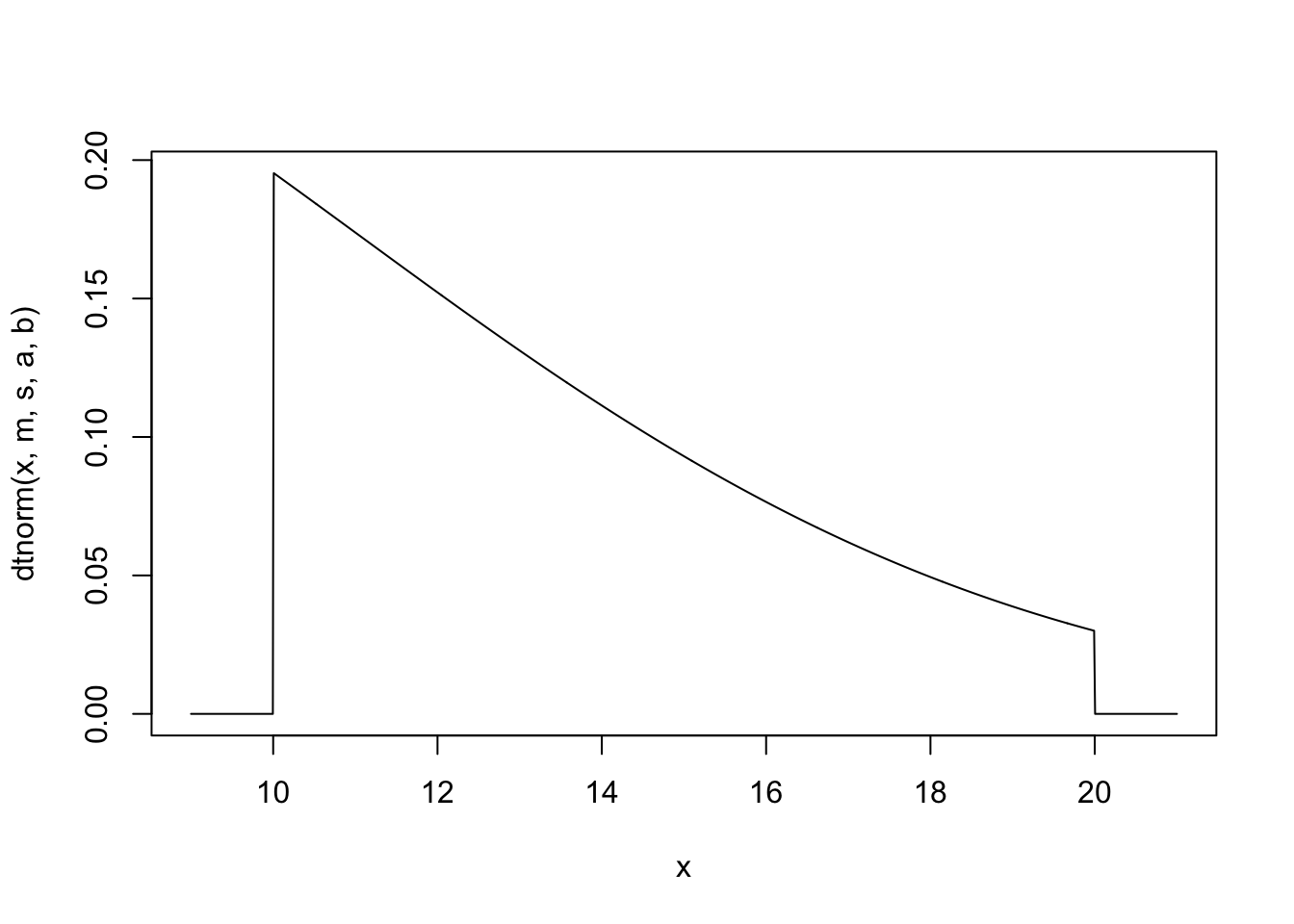
Suppose our random variables have a normal distribution but are truncated between two values \(a\) and \(b\). We might write this as \(N(\mu,\sigma^2)[a,b]\).
Let’s first construct a function to simulate this random variable. (There are better ways to do this.)
# Function to simulate a truncated normalrtnorm <-function(n, mean, sd, a, b) {# Propose n values [not all will be (a,b)] x <-rnorm(n, mean, sd) # Replace values not in (a,b) # with new values in (a,b)for (i inseq_along(x)) {while (x[i] < a || x[i] > b) { x[i] <-rnorm(1, mean, sd) } }return(x)}
also the density for a truncated normal
# Density for a truncated normaldtnorm <-function(x, mean, sd, a, b) {# Calculate probability of being in (a,b) c <-diff(pnorm(c(a,b), mean, sd))# Normalize untruncated normal by this probability# to ensure this density integrates to 1 d <-dnorm(x, mean, sd)/c# Return this density or 0 if outside (a,b)return(d * (a < x & x < b))}
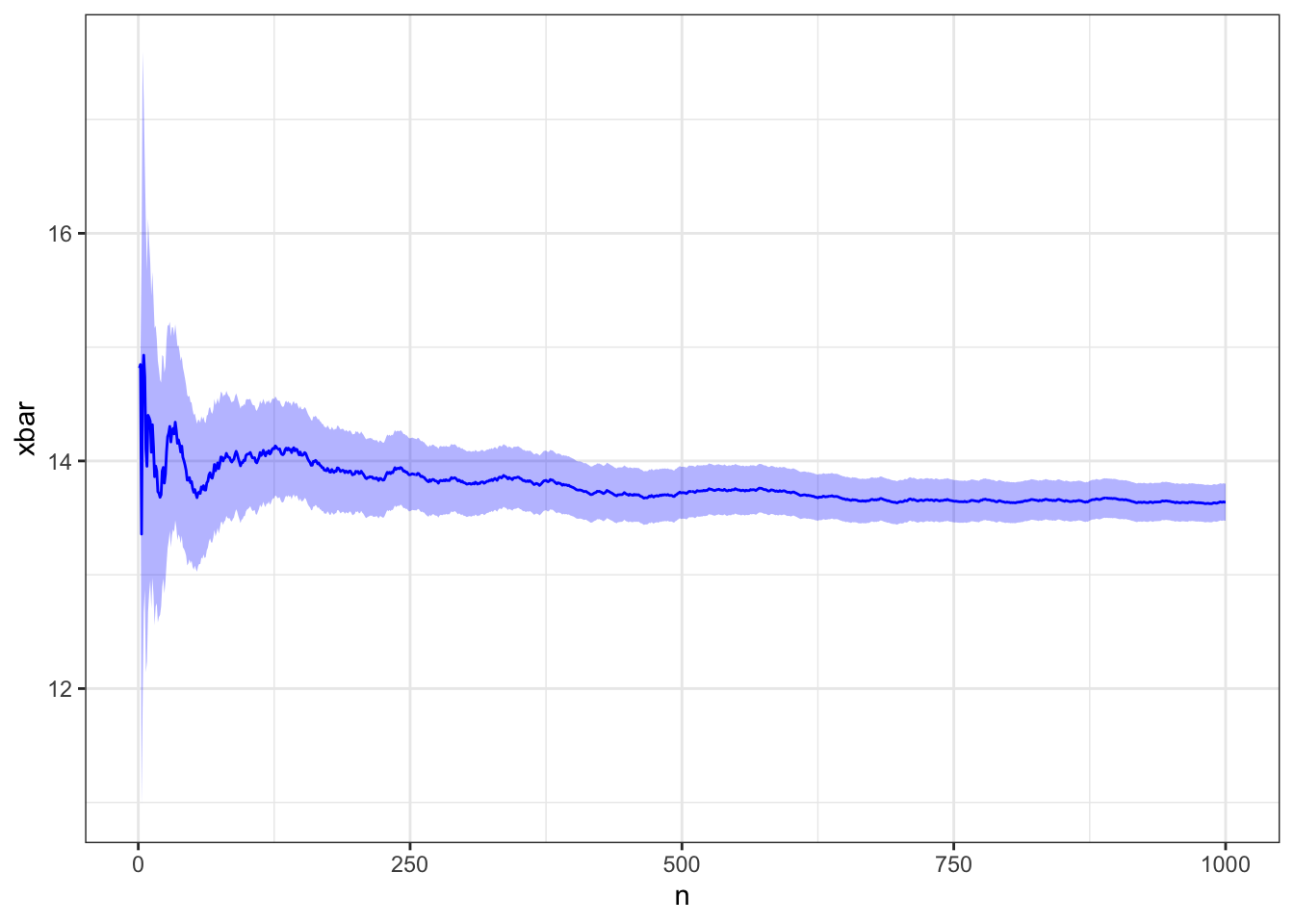
Simulate and plot
# Pick these valuesm <-3# untruncated expectations <-8# untruncated standard deviationa <-10# lower truncation boundb <-20# upper truncation bound# Plot densitycurve(dtnorm(x, m, s, a, b), from = a -1, to = b +1, n =1001)
Monte Carlo
# Estimate expectation via Monte Carlox <-rtnorm(1e3, m, s, a, b)d <-create_expectation_dataframe(x)plot_expectation(d)
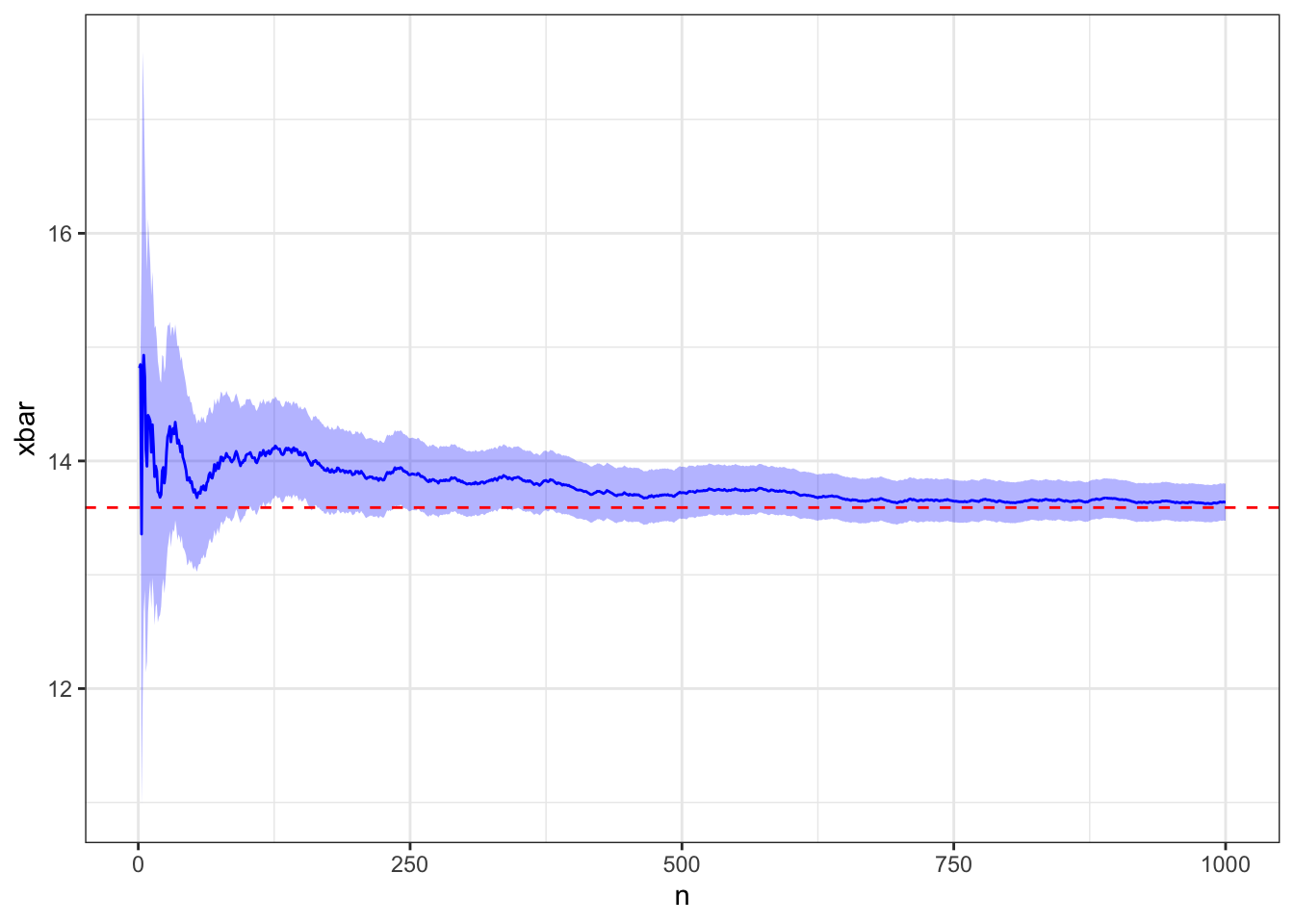
The expectation actually can be calculated for a truncated normal
# Calculate true expectation for truncated normal and plot italpha <- (a-m)/sbeta <- (b-m)/sexpectation <- m + s * (dnorm(alpha) -dnorm( beta)) / (pnorm(beta ) -pnorm(alpha)) plot_expectation(d, truth = expectation)
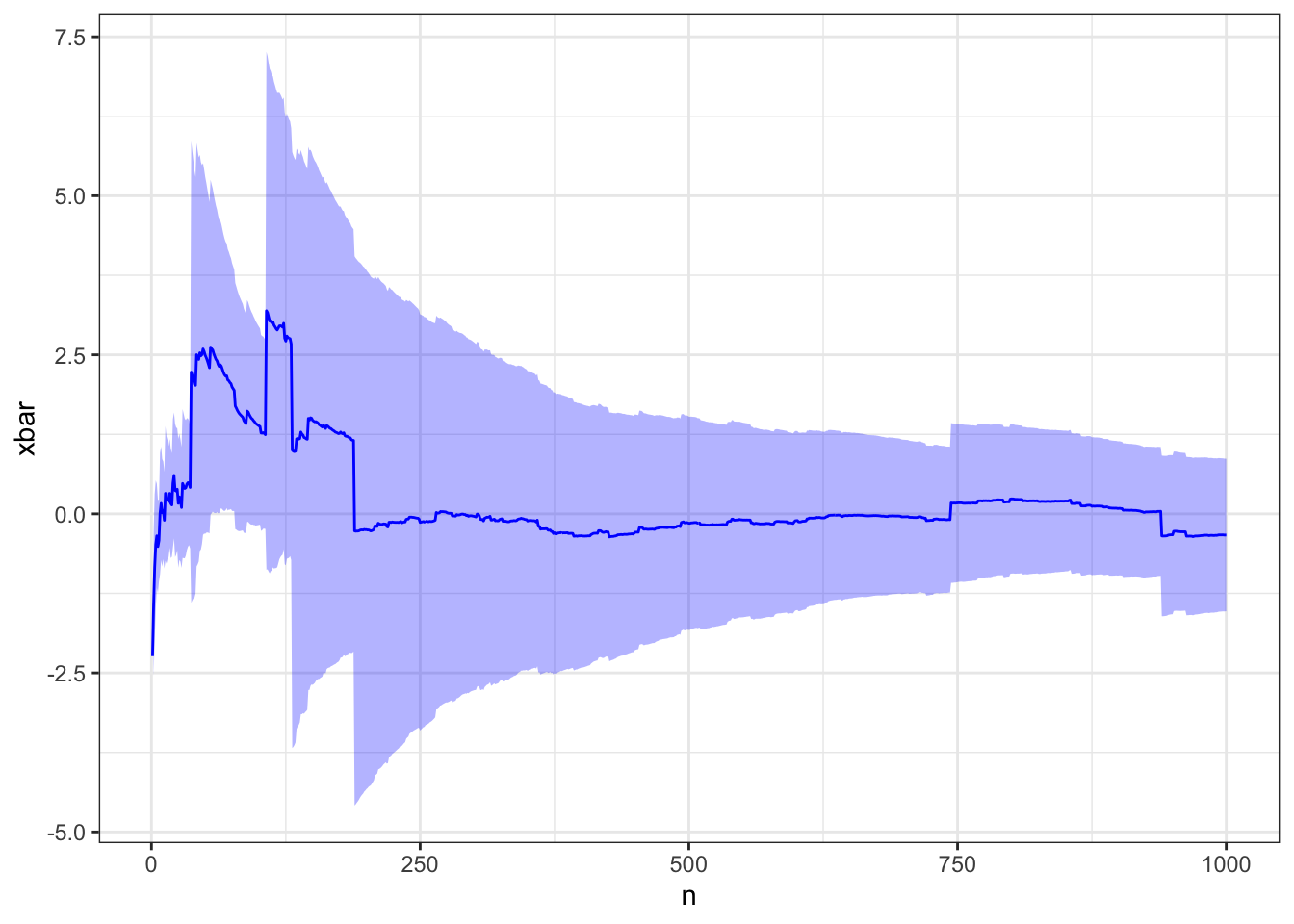
28.1.2.3 Cauchy expectation
Watch out!
You need to pay attention to whether the variance is finite amongst your random variables. A Cauchy distribution has no moments and therefore its expectation and variance are both undefined. This occurs because the Cauchy distribution has extremely heavy tails.
Let’s use Monte Carlo to try and estimate a Cauchy ``expectation’’
# Pick thesem <-0# Cauchy location s <-1# Cauchy scale# Simulate random Cauchyx <-rcauchy(1e3, m, s)# Create Monte Carlo estimate and plot itd <-create_expectation_dataframe(x)plot_expectation(d)
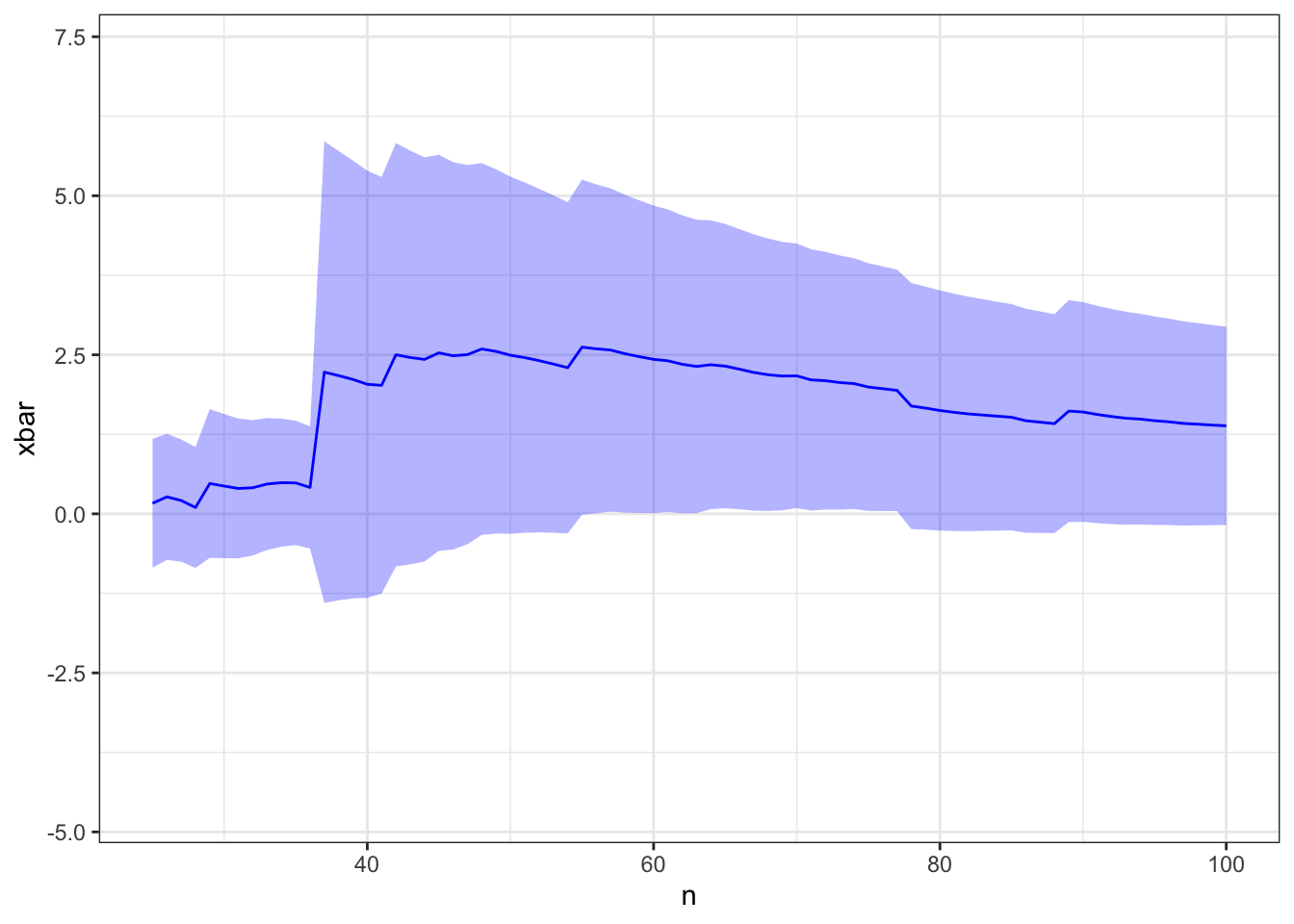
plot_expectation(d) +xlim(25,100) # will likely need to adjust the limits
Warning: Removed 924 rows containing missing values or values outside the scale range
(`geom_line()`).
The CLT is not relevant here because the variance of the random variables is not finite.
28.2 Probability
If we have \(Y \sim Bin(n,\theta)\) with \(\theta \in (0,1)\) and \(\hat\theta = Y/n\), then \[
\frac{\hat\theta-\theta}{\sqrt{\frac{\hat\theta(1-\hat\theta)}{n}}} \stackrel{d}{\to} N(0,1) \quad \mbox{as } n\to \infty.
\] Thus, for large enough n, \[
\hat\theta \stackrel{\cdot}{\sim} N\left(\theta, \frac{\hat\theta(1-\hat\theta)}{n}\right)
\] where \(\stackrel{\cdot}{\sim}\) expectations “approximately distributed.”
This result is the basis of a common asymptotic confidence interval formula for \(\theta\): \[
\hat\theta \pm z_{\alpha/2} \sqrt{\frac{\hat\theta(1-\hat\theta)}{n}}
\] where \(z_{\alpha/2}\) is a critical value that depends on the confidence level \(100(1-\alpha)\)% of the confidence interval. The term \(\sqrt{\hat\theta(1-\hat\theta)/n}\) is referred to as the standard error (SE).
28.2.1 Functions
Function to create proportion data frame. The data will be binary (0/1) or logical (TRUE/FALSE).
# Create data frame to construct # n : number of simulations# theta_hat : cumulative estimated proportion# se : cumulative standard error# lcl : cumulative lower confidence limit for CI# ucl : cumulative upper confidence limit for CIcreate_proportion_dataframe <-function(x, alpha =0.05) {data.frame(n =1:length(x)) %>%mutate(theta_hat =cumsum(x)/n,se =sqrt( theta_hat * (1-theta_hat) / n ),lcl = theta_hat -qnorm( 1- alpha/2 ) * se,ucl = theta_hat +qnorm( 1- alpha/2 ) * se )}
and the plot function
# Function to plot cumulative proportion with CIplot_proportion <-function(d, truth =NULL) { g <-ggplot(d, aes(x = n, y = theta_hat, ymin = lcl, ymax = ucl)) +geom_ribbon(fill ="blue", alpha =0.3) +geom_line(color ="blue")if (!is.null(truth)) g <- g +geom_hline(yintercept = truth, color ="red", linetype =2)return(g)}
28.2.2 Examples
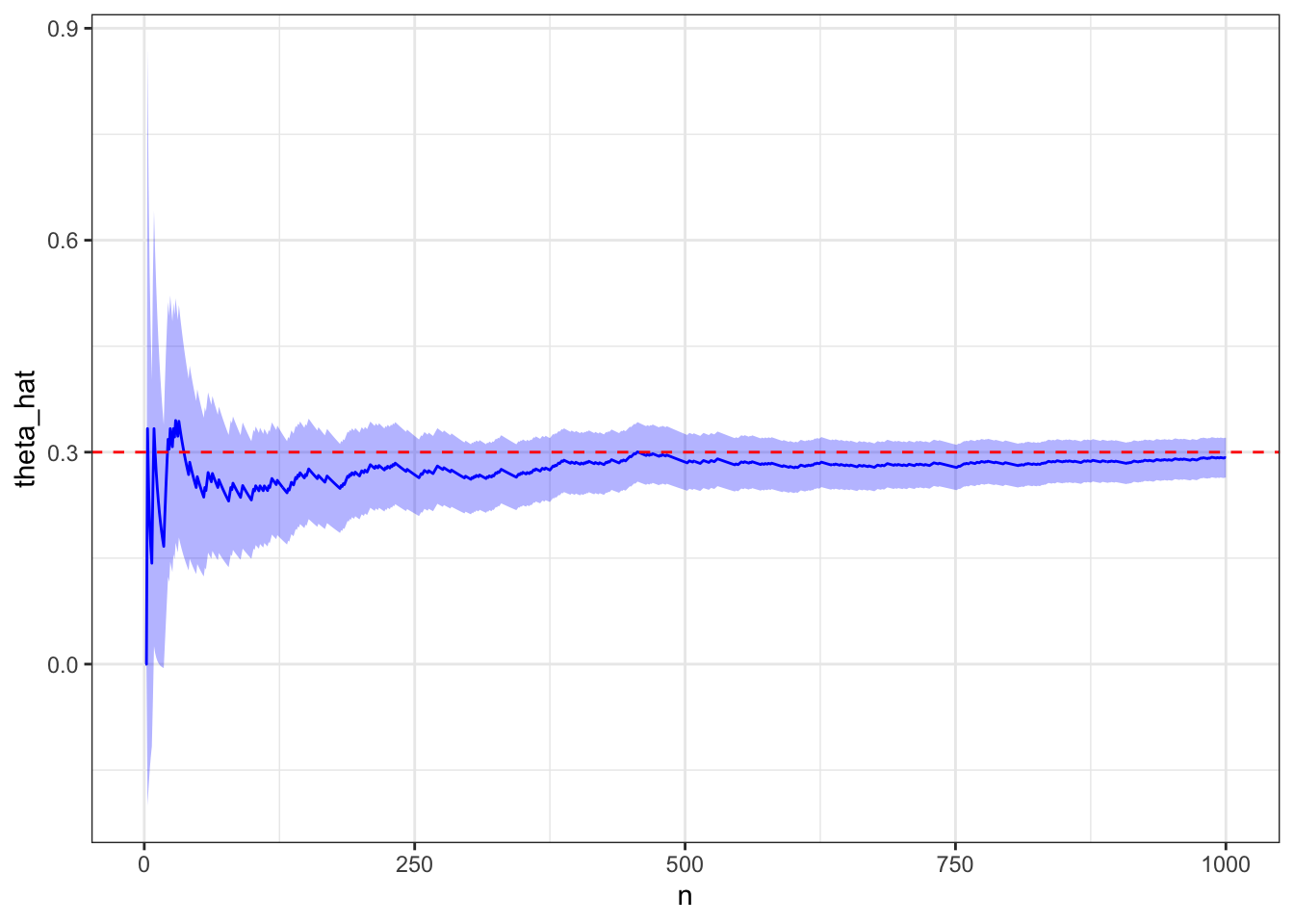
28.2.2.1 Bernoulli
Let’s generate some Bernoulli data that, when summed, will be binomial.
# Pick thisp <-0.3# Bernoulli success probability# Monte Carlo simulation and plotx <-rbinom(1e3, size =1, prob = p)d <-create_proportion_dataframe(x)plot_proportion(d, truth = p)
28.2.2.2 Normal probability
How about the probability a normal random variable is between two end points? Of course, we can calculate the truth here.
# Pick thesem <-0# normal expectations <-1# normal standard deviationa <-2# lower endpointb <-4# upper endpoint# Monte Carlo simulationy <-rnorm(1e3, m, s)x <- a < y & y < b # data in (a,b)# Plotd <-create_proportion_dataframe(x)plot_proportion(d, truth =diff(pnorm(c(a,b), mean = m, sd = s)))
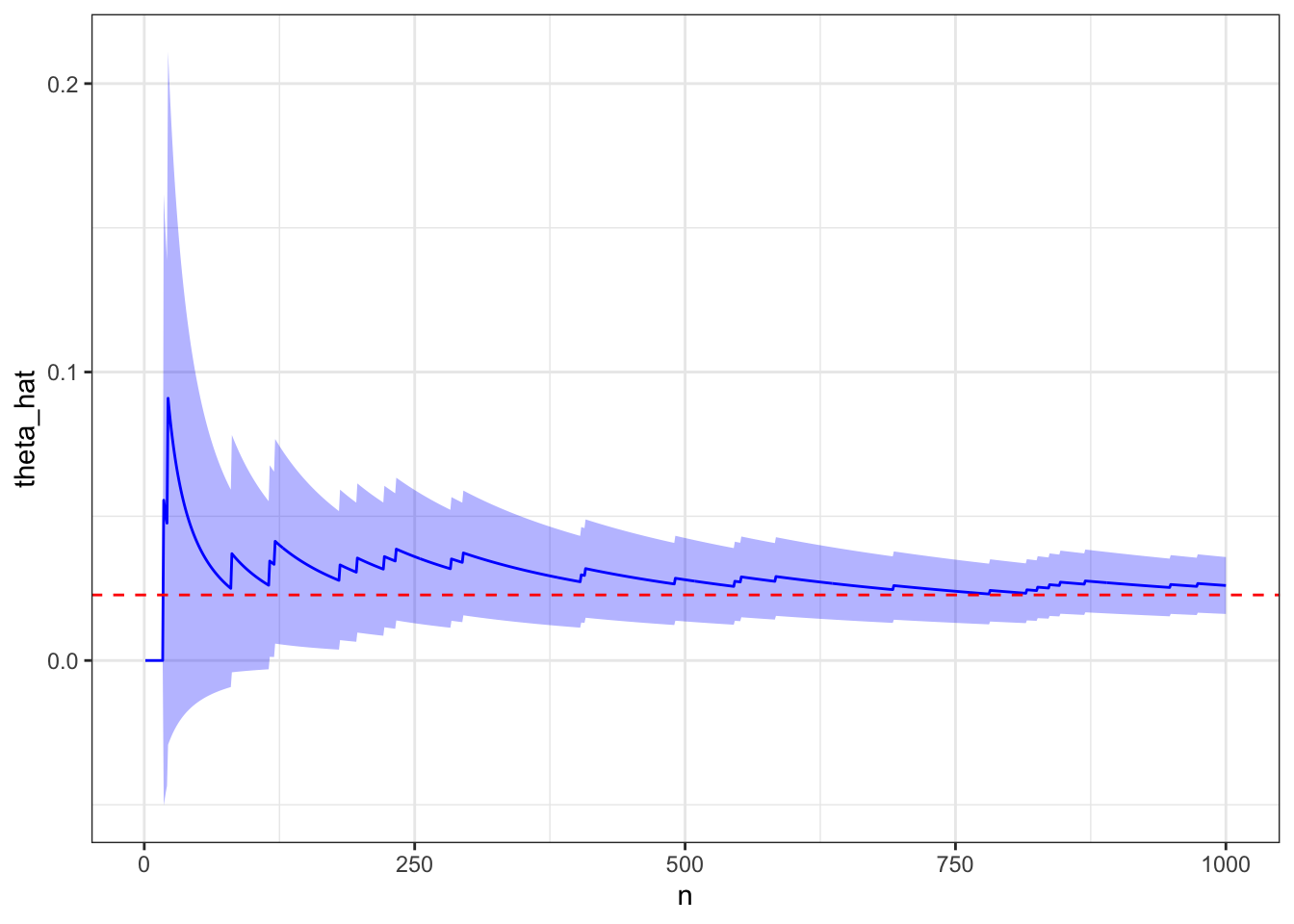
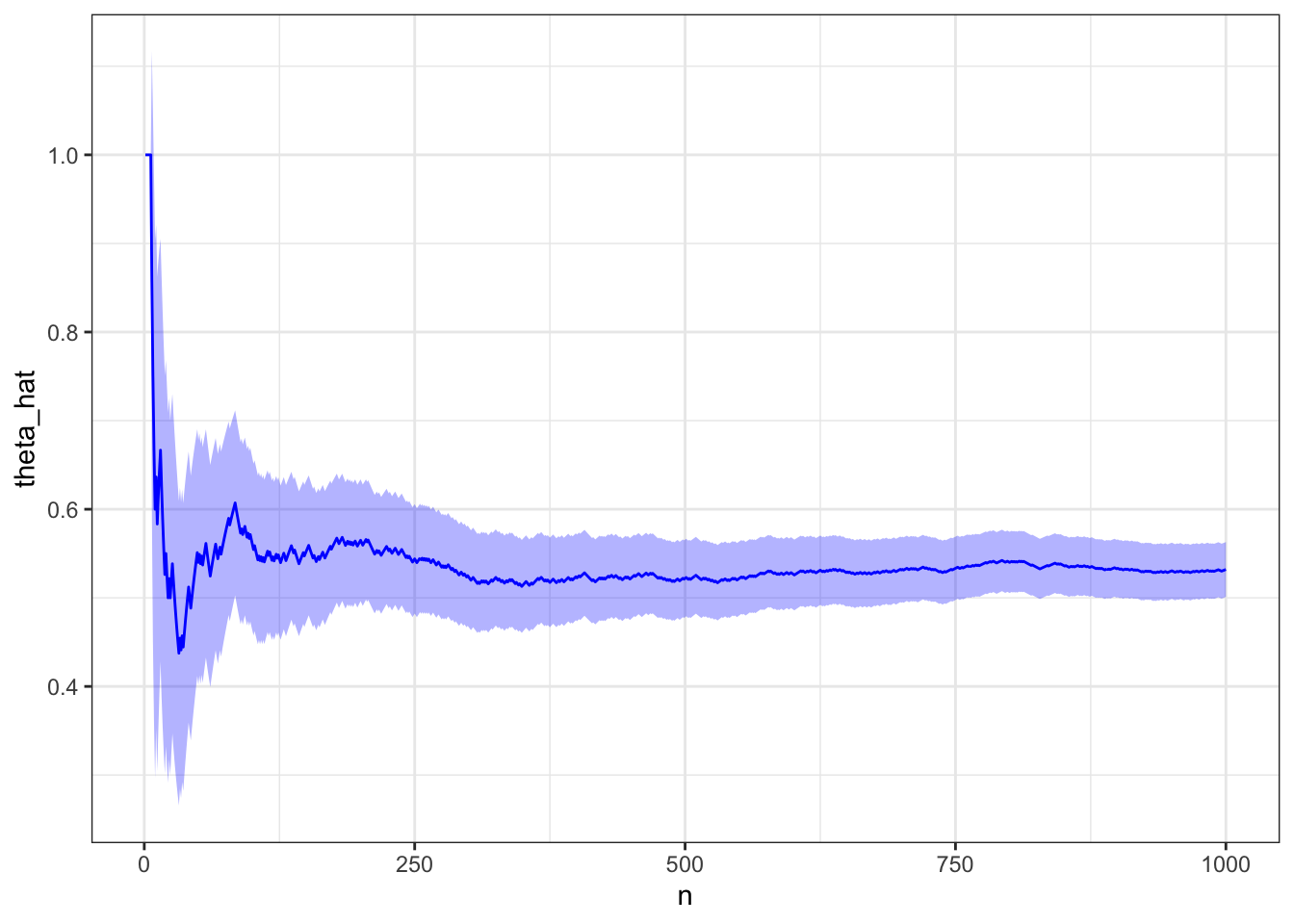
28.2.2.3 Unknown probability
How about the probability that the absolute value of a normal random variable is less than an exponential random variable?
# Let Y ~ N(0,1)# X ~ Exp(1)# Estimate P(|Y| < X)# Simulate X and Yn <-1e3y <-rnorm(n)e <-rexp(n)# Calculate proportion |Y| < ex <-abs(y) < e# Create and plotd <-create_proportion_dataframe(x)plot_proportion(d)
tail(d, 1)
n theta_hat se lcl ucl
1000 1000 0.532 0.01577897 0.5010738 0.5629262
28.3 Summary
Throughout these examples, we have focused on visualizing the estimated expectation or probability as the number of simulations increases. We have noted how the uncertainty decreases as we increase the number of simulations. Typically, we simply need to run enough simulations so that our uncertainty is sufficiently small.
Below is some code and examples for estimating an expectation.
# Function to calculate Monte Carlo expectation with standard errormc_expectation <-function(x) {return(c(mean =mean(x),se =sd(x)/sqrt(length(x))) )}# Normal # as Monte Carlo sample size increases# standard error decreasesmc_expectation(rnorm(1e3, mean =10))
mean se
10.0256019 0.0321432
mc_expectation(rnorm(1e4, mean =10))
mean se
10.00947644 0.01005021
mc_expectation(rnorm(1e5, mean =10))
mean se
9.995909568 0.003160671
# Truncated normalmc_expectation(rtnorm(1e4, mean =10, sd =1, a =7, b =11))
mean se
9.720711797 0.007835022
# Exponentialmc_expectation(rexp(1e4, rate =5))
mean se
0.197352813 0.001973589
Below is some code and examples for estimating a proportion
# Function to calculate Monte Carlo proportion with standard errormc_probability <-function(x) { p <-mean(x)return(c(prop = p,se =sqrt(p*(1-p)/length(x))) )}# Normalx <-rnorm(1e4, mean =10, sd =0.1)mc_probability(x >9)
One frustrating aspect of Monte Carlo studies is that they are not reproducible. Every time you run a simulation, you will obtain a different answer. This is especially frustrating when you are trying to debug your code. In these situations, you can set the seed using the set.seed() function which will make the Monte Carlo study reproducible.
set.seed(20240423)mc_expectation(rnorm(1e3, mean =10))
mean se
10.03307003 0.03261884
mc_expectation(rnorm(1e3, mean =10)) # not reproducible
mean se
9.96191213 0.03218702
set.seed(20240423)mc_expectation(rnorm(1e3, mean =10)) # reproducible