── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Recall that estimators are statistics that attempt to estimate a population parameter. We are generally assuming here that we have a simple random sample from the population and we are interested in estimating a mean or proportion from that population.
29.1 Examples
29.1.1 Binomial
Let \(X \sim Bin(n,p)\). The MLE for \(p\) is \[
\hat{p} = \frac{x}{n}.
\]
29.1.2 Normal
Let \(Y_i \stackrel{ind}{\sim} N(\mu,\sigma^2)\).
29.1.2.1 Mean
The maximum likelihood estimator (MLE) for \(\mu\) is \[
\hat\mu = \overline{y}.
\] This also happens to be the least squares estimator and the Bayes estimator (assuming the standard default prior).
29.1.2.2 Variance
The MLE for \(\sigma^2\) is \[
\hat\sigma^2_{MLE} = \frac{1}{n} \sum_{i=1}^n (y_i-\overline{y})^2
\] while the sample variance is \[
s^2 = \frac{1}{n-1} \sum_{i=1}^n (y_i-\overline{y})^2.
\] So why might we prefer one of these estimators over another?
29.1.3 Regression
The regression model (in multivariate normal form) is \[
Y \sim N(X\beta,\sigma^2\mathrm{I}).
\] The MLE, least squares, and default Bayes estimator for \(\beta\) is \[
\hat\beta = (X^\top X)^{-1}X^\top y.
\]
29.2 Properties
There are a variety of reasons we might use to choose an estimator. We might appreciate the universality of the maximum likelihood estimator or the ability to incorporate prior information in Bayes estimator. Here we will talk about some properties of estimators, namely:
bias
variance
mean squared error
consistency
For the following \(\theta\) is the population parameter we are trying to estimate and \(\hat{\theta}\) is the estimator of \(\theta\).
29.2.1 Bias
The bias of an estimator is the expectation of the estimator minus the true value of the estimator. \[
\mbox{Bias}\left[\hat{\theta}\right]
= E\left[\hat{\theta} - \theta\right]
= E\left[\hat{\theta}\right] - \theta.
\]
An estimator is unbiased when the bias is 0 or, equivalently, its expectation is equal to the true value.
For example,
\(E\left[\hat{p}_{MLE}\right] = p\)
\(E\left[\hat\mu\right] = \mu\)
\(E\left[s^2\right] = \sigma^2\)
indicate that all of these estimators are unbiased.
The variance of an estimator is just the variance of the statistic: \[
Var\left[\hat{\theta}\right]
= E\left[(\hat{\theta} - E[\hat{\theta}])^2\right].
\]
For example, the MLE for a binomial probability of success is
Notice how both of these decrease as \(n\to \infty\).
29.2.3 Mean squared error
The mean squared error (MSE) of an estimator is the expectation of the squared difference between the estimator and the truth. This turns out to have a simple formula in terms of the bias and variance.
For unbiased estimators, the MSE is the same as the variance which is why we talk about minimum variance unbiased estimators (MVUE).
For biased estimators, the formula is a bit more interesting and can result in estimators that are better than MVUE in regard to MSE.
29.2.4 Consistency
An estimator is consistent if it gets closer to the true value in probability as the sample size gets larger. Specifically \[
\lim_{n\to\infty} P(|\hat{\theta}-\theta| > \epsilon) = 0
\] for all \(\epsilon>0\).
For unbiased estimators, the estimator is consistent if the variance converges to zero as the sample size increases. For biased estimators, the estimator is consistent if both the variance and the bias converge to zero as the sample size increases.
Every estimator discussed above is consistent.
29.3 Monte Carlo Evaluation
Let’s use Monte Carlo to evaluate these estimators. We will need to obtain many samples to estimate bias and variance. Recall the following function from the Monte Carlo basics page.
# Function to calculate Monte Carlo expectation with standard errormc_expectation <-function(x) {return(c(mean =mean(x),se =sd(x)/sqrt(length(x))) )}
29.3.1 Binomial - maximum likelihood estimator
Recall that, if \(X\sim Bin(n,p)\), then the MLE for the probability of success in a binomial is \[
\hat{p}_{MLE} = x/n.
\]
29.3.1.1 Bias
# Binomial examplen <-10p <-0.3x <-rbinom(1e3, size = n, prob = p)theta_hat = x / n
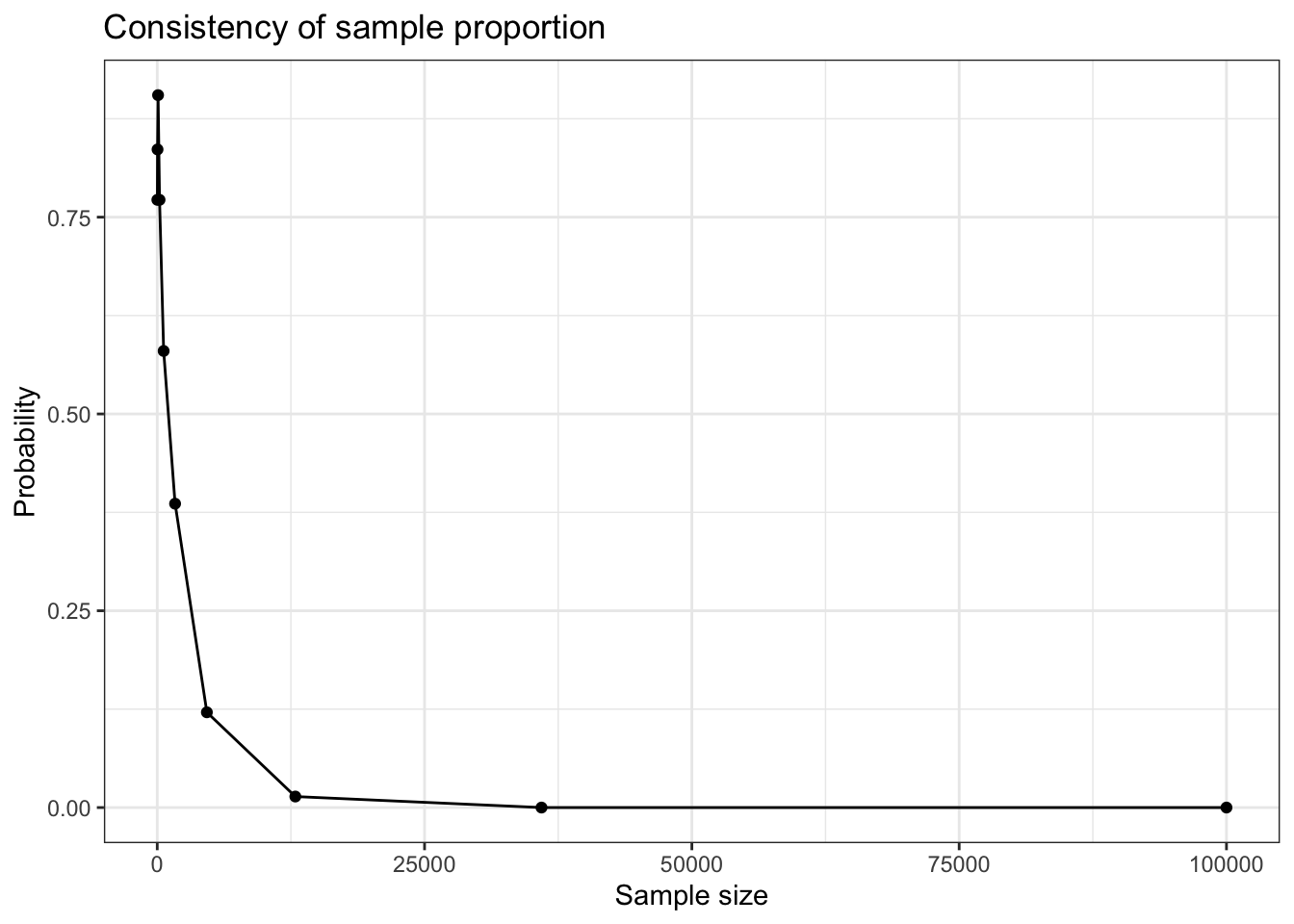
# Sampling distribution for binomial MLEggplot() +geom_histogram(mapping =aes(x = theta_hat,y =after_stat(density)), bins =30) +geom_vline(xintercept = p, col ='red') +labs(x =expression(hat(theta)[MLE]),title ="Sampling distribution for sample proportion")
# Binomial MLE expectationsmc_expectation( theta_hat ) # mean
mc_expectation( (theta_hat - p )^2 ) # mean-squared error
mean se
0.0213200000 0.0009942062
29.3.1.2 Consistency
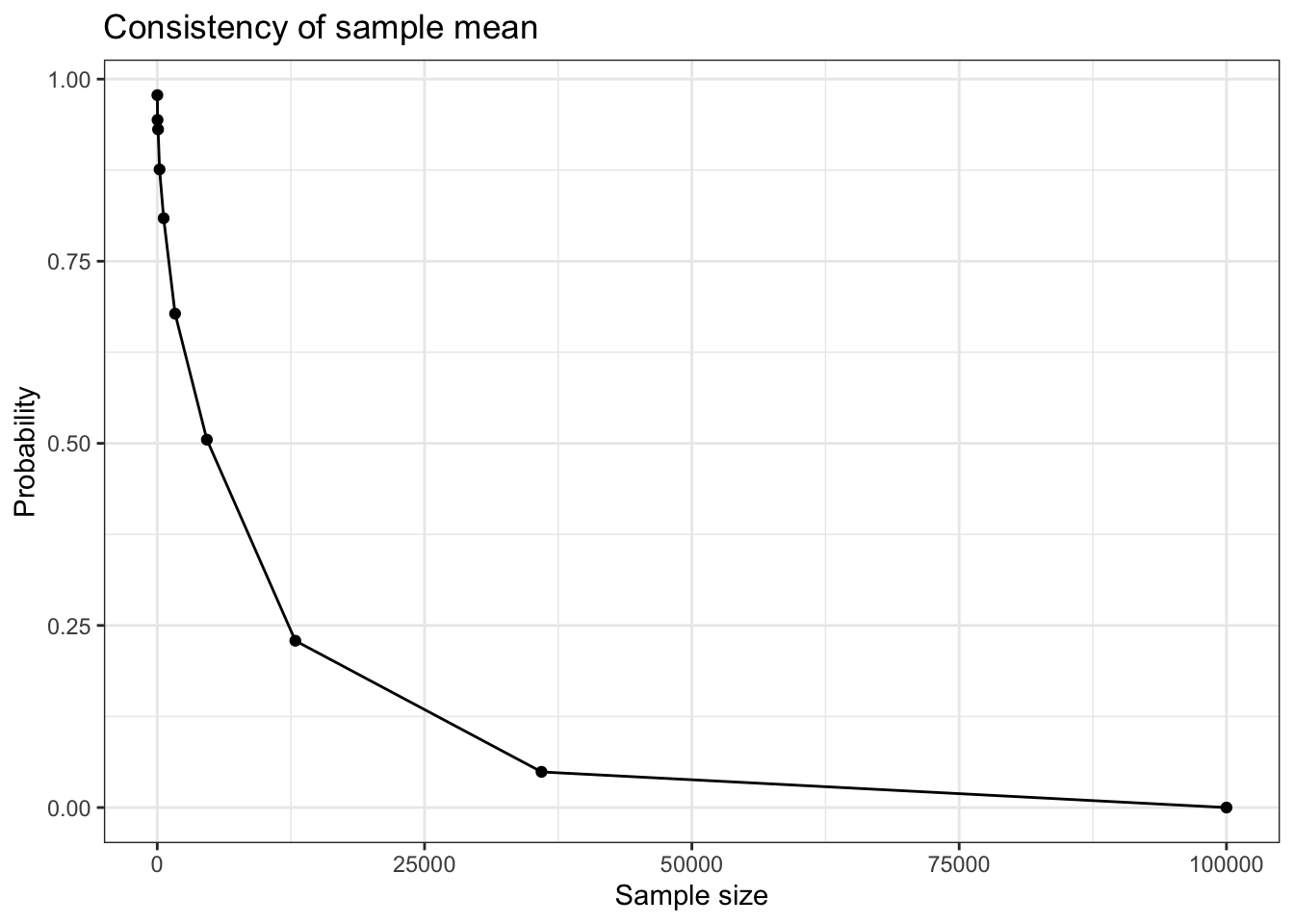
Consistency is evaluated through a probability as the number of samples tends to infinity. Thus, we will need to evaluate a collection of probabilities.
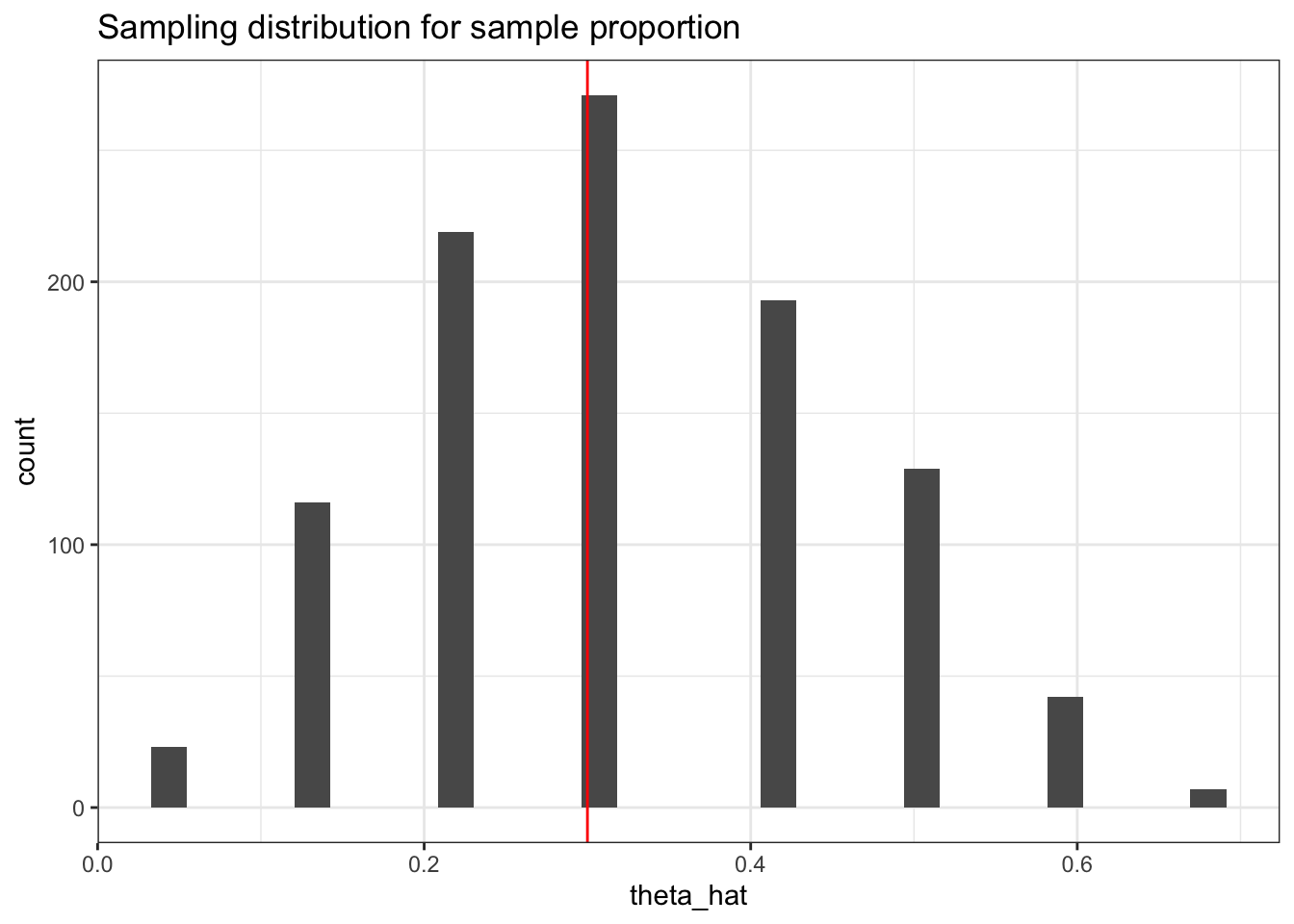
For MLE for a binomial distribution with unknown probability of success, we can compute the probability that the MLE is outside of \(\epsilon\) of the true value. For consistency to hold, the limit of this probability must be 0 for any \(\epsilon>0\). But to visualize results, we need to make \(\epsilon\) relatively large.
# Pick theseepsilon <-0.01p <-0.3# Set up sequence of values of nn_seq <-floor(10^seq(1, 5, length =10))p_seq <-numeric(length(n_seq))# Conduct Monte Carlo study for (i inseq_along(n_seq)) {# Simulate binomial random variables x <-rbinom(1e3, # Determines accuracy of Monte Carlo estimates of the probabilitiessize = n_seq[i], # This is the n involved in the limit of the consistency definitionprob = p)# Calculate probability of being p_seq[i] <-mean(abs(x/n_seq[i] - p) > epsilon)}ggplot(data.frame(n = n_seq, p = p_seq),aes(x = n, y = p_seq)) +geom_point() +geom_line() +labs(x ="Sample size", y ="Probability",title ="Consistency of sample proportion")
29.3.2 Binomial - default Bayesian
A default Bayesian analysis for an unknown binomial probability is \[
\hat{p}_{Bayes} = \frac{0.5 + x}{1 + n}
\]
29.3.2.1 Bias
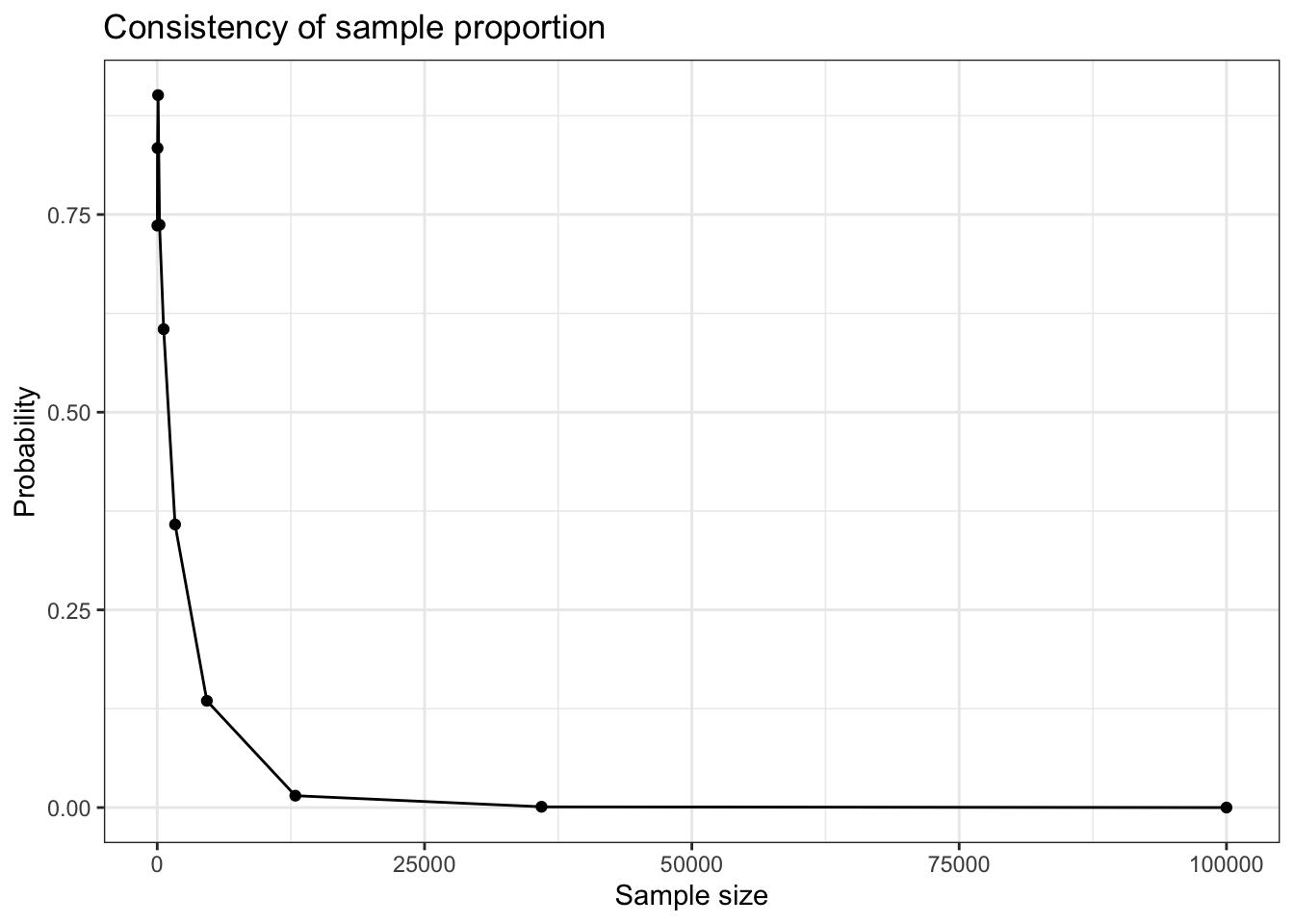
# Pick thesen <-10p <-0.3# Monte Carlo simulationsx <-rbinom(1e3, size = n, prob = p)theta_hat <- (0.5+ x) / (1+ n)
Plot the Bayes estimator.
ggplot() +geom_histogram(mapping =aes(x = theta_hat), bins =30) +geom_vline(xintercept = p, col ='red') +labs(title="Sampling distribution for sample proportion")
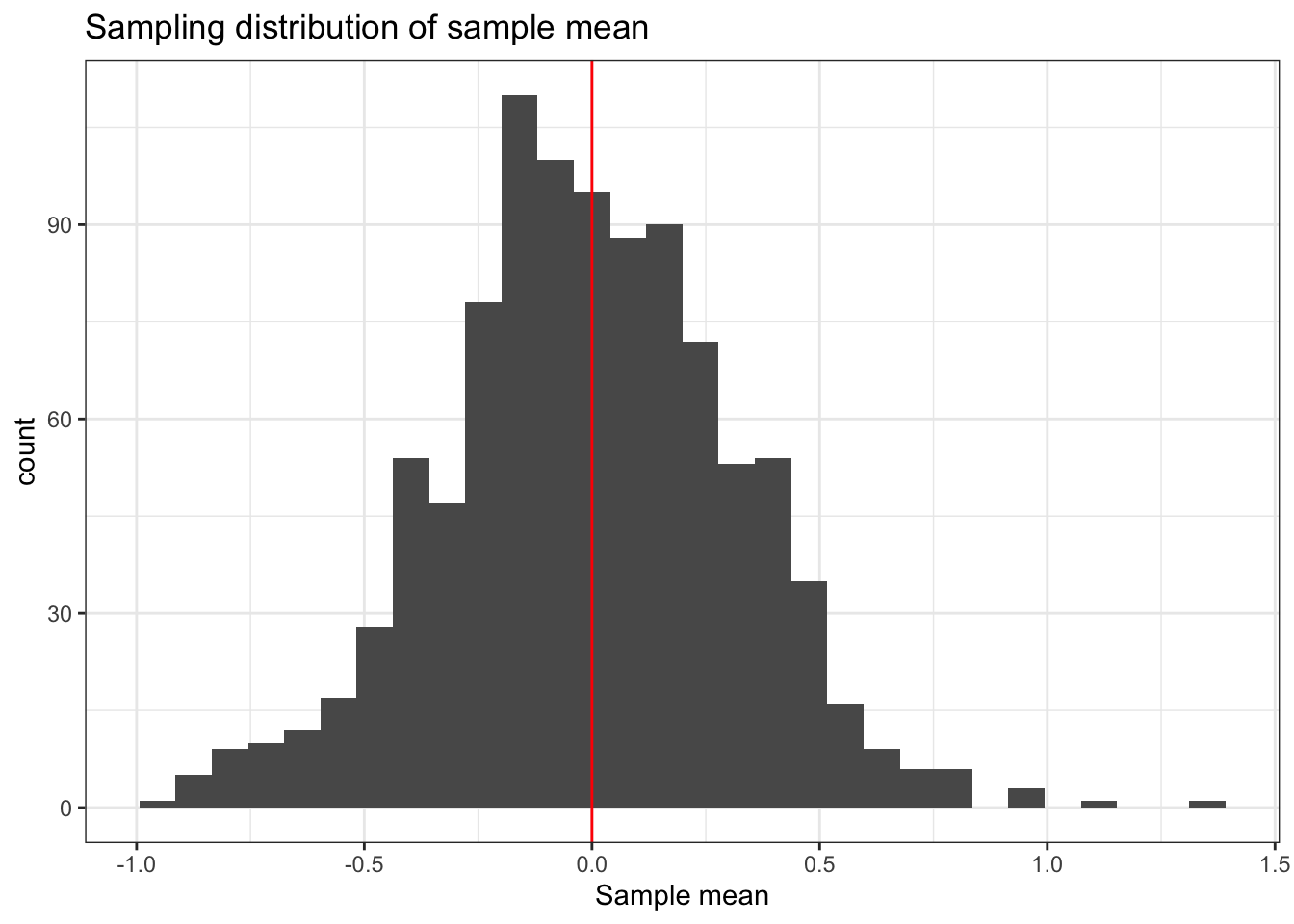
ggplot(d, aes(x = ybar)) +geom_histogram(bins =30) +geom_vline(xintercept = m, color ="red") +labs(x ="Sample mean", title ="Sampling distribution of sample mean")
# Monte Carlo expectationsmc_expectation( d$ybar ) # mean