── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library("Sleuth3")library("ggResidpanel")
Generally, the simple linear regression model has a continuous response variable and a continuous explanatory variable.
34.1 Model
The structure of a simple linear regression model is \[
Y_i \stackrel{ind}{\sim} N(\beta_0 + \beta_1X_{i}, \sigma^2)
\] for \(i=1,\ldots,n\) or, equivalently, \[
Y_i = \beta_0 + \beta_1X_{i} + \epsilon_i,
\qquad \epsilon_i \stackrel{ind}{\sim} N(0, \sigma^2).
\]
where, for observation \(i\),
\(Y_i\) is the value of the response variable,
\(X_{i}\) is the value of the explanatory variable, and
\(\epsilon_i\) is the error.
The model parameters are
the intercept \(\beta_0\),
the slope \(\beta_1\), and
the error variance \(\sigma^2\).
34.2 Assumptions
The assumptions in every regression model are
errors are independent,
errors are normally distributed, and
errors have constant variance.
For simple linear regression,
the expected response, \(E[Y_i] = \beta_0 + \beta_1X_i\), is a linear function of the explanatory variable.
34.3 Visualize
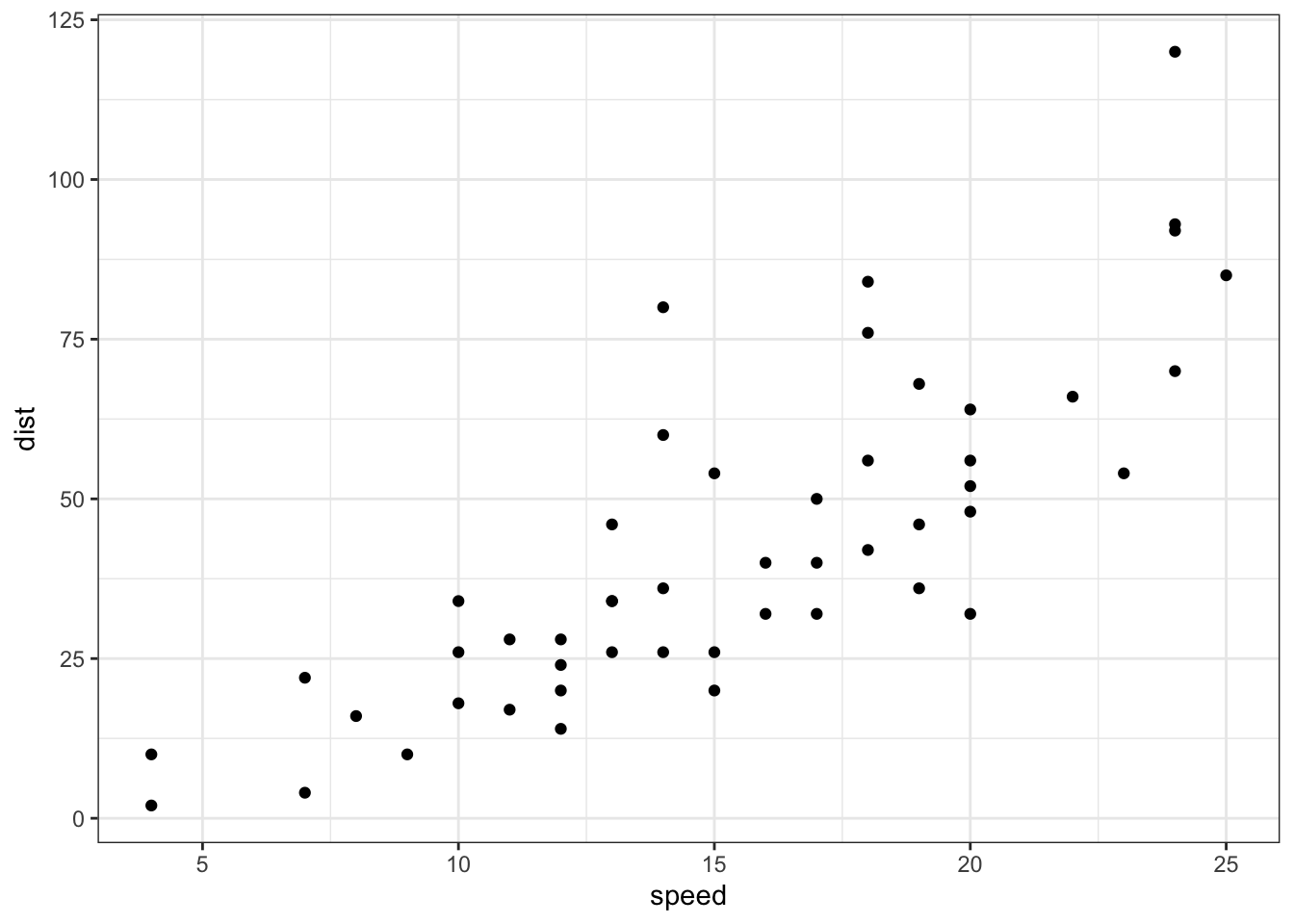
Let’s start with an example where the simple linear regression model is straight forward. When constructing a plot, the explanatory variable should be put on the x-axis while the response variable should be put on the y-axis.
# Simple linear regression modelg <-ggplot(cars, aes(x = speed,y = dist)) +geom_point() g
To fit a linear regression model use lm()
# Regression model fitm <-lm(dist ~ speed, data = cars)
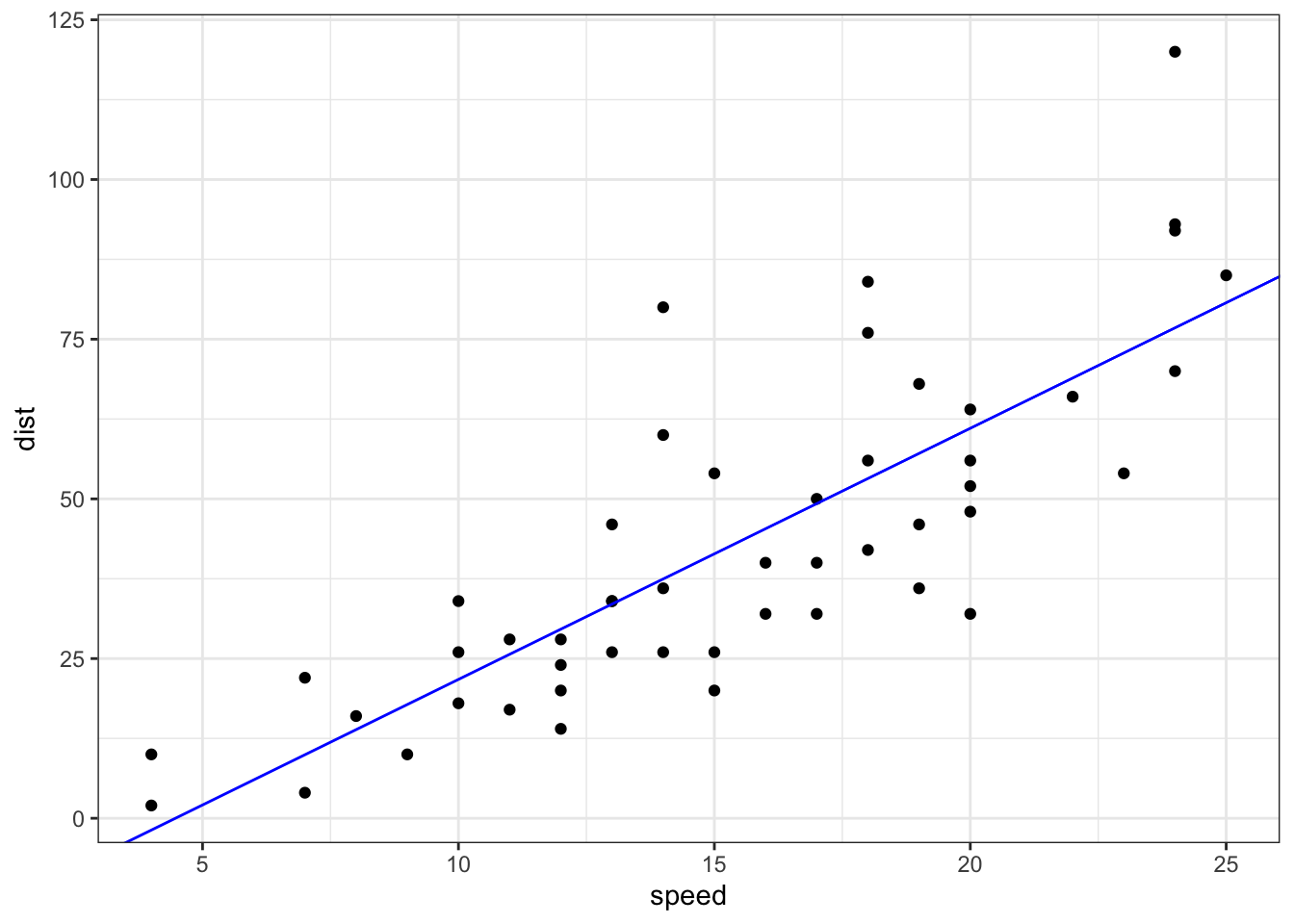
It is typically helpful to visualize the data with the line added.
Call:
lm(formula = dist ~ speed, data = cars)
Residuals:
Min 1Q Median 3Q Max
-29.069 -9.525 -2.272 9.215 43.201
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -17.5791 6.7584 -2.601 0.0123 *
speed 3.9324 0.4155 9.464 1.49e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 15.38 on 48 degrees of freedom
Multiple R-squared: 0.6511, Adjusted R-squared: 0.6438
F-statistic: 89.57 on 1 and 48 DF, p-value: 1.49e-12
Recall that coefficients can be calculated from the formulas \[\widehat{\beta}_1 = \frac{SXY}{SXX} =
\frac{\sum_{i=1}^n (x_i - \overline{x})(y_i-\overline{y})}{\sum_{i=1}^n (x_i-\overline{x})^2}\] and \[\widehat{\beta}_0 = \overline{y} - \widehat{\beta}_1 \overline{x}\] where \(\overline{x}\) and \(\overline{y}\) are the sample means for the explanatory and response variables, respectively. /
# Intercept (beta0) and slope (beta1)m$coefficients
(Intercept) speed
-17.579095 3.932409
coef(m)
(Intercept) speed
-17.579095 3.932409
Residuals are the estimated errors and can be calculated from the formula \[r_i = \widehat{e}_i = y_i - \left(\widehat{\beta}_0 + \widehat{\beta}_1 x_i\right).\] These residuals can be used to calculate the estimated error variance using the formula \[\widehat{\sigma}^2
= \frac{1}{n-2} RSS
= \frac{1}{n-2} \sum_{i=1}^n r_i^2\] where \(n-2\) is the degrees of freedom.
# Calculate residualsr <- y - (beta0 + beta1*x)head(r)
Confidence intervals and p-values for the intercept and slope require the associated standard errors. The standard error for the slope is \[SE(\widehat{\beta}_1) = \sqrt{\frac{\widehat{\sigma}^2}{SXX}}\] and the standard error for the intercept is \[SE(\widehat{\beta}_0) = s_{\widehat{\beta}_1}\sqrt{\frac{1}{n}\sum_{i=1}^n x_i^2}.\]
# Standard errorsse_beta1 <-sqrt(s$sigma^2/ sxx)se_beta0 <- se_beta1 *sqrt(mean(x^2))se_beta0
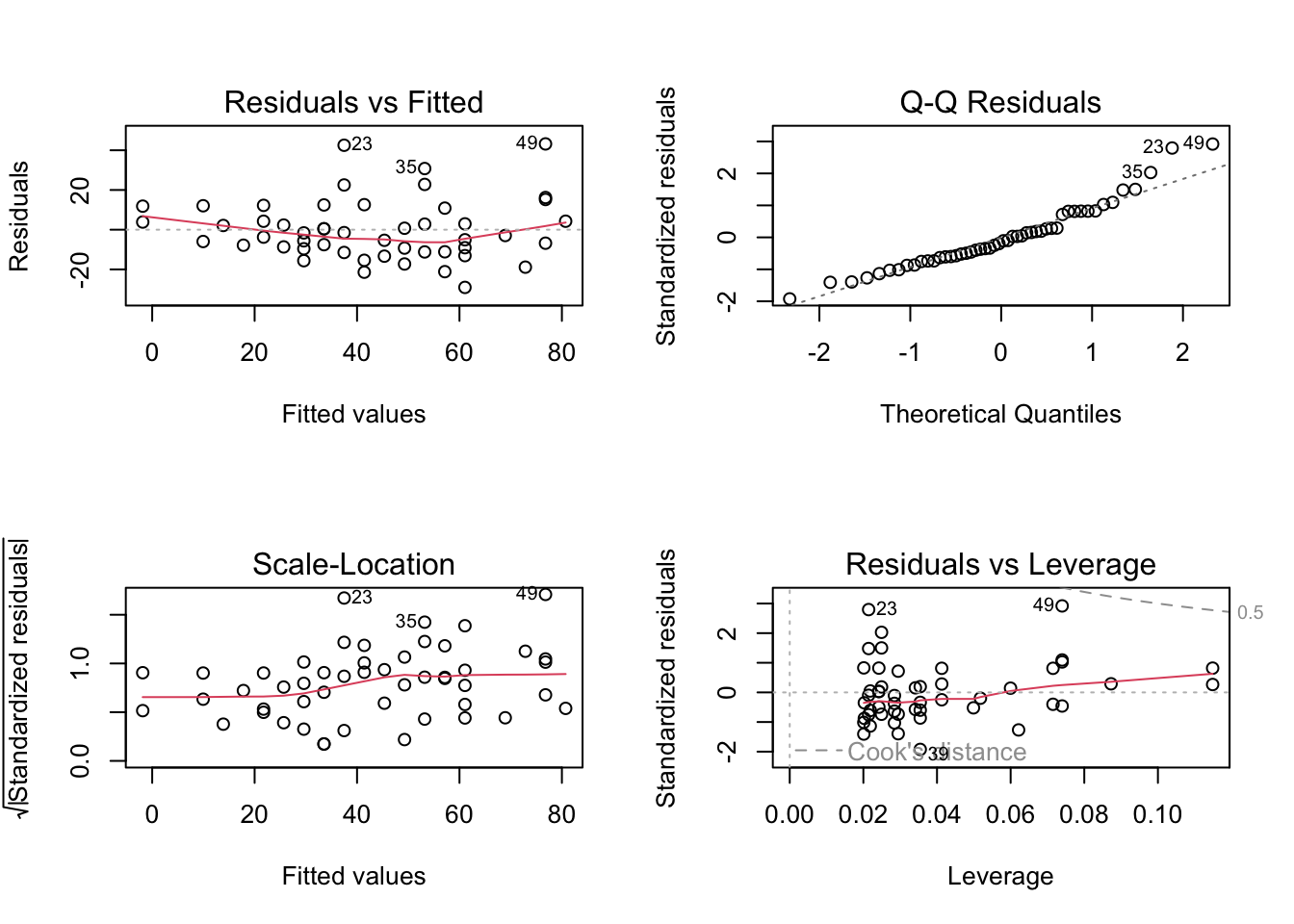
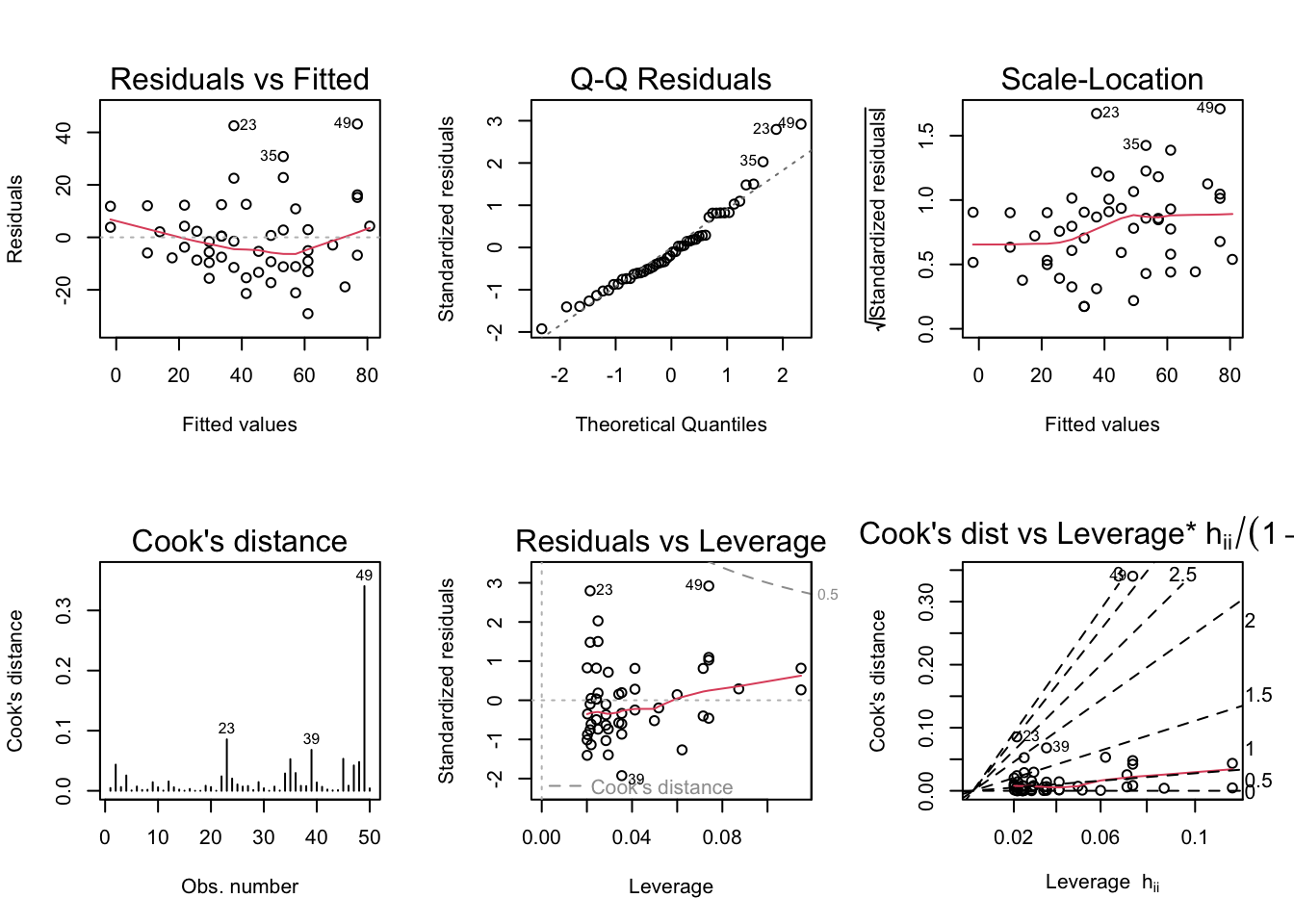
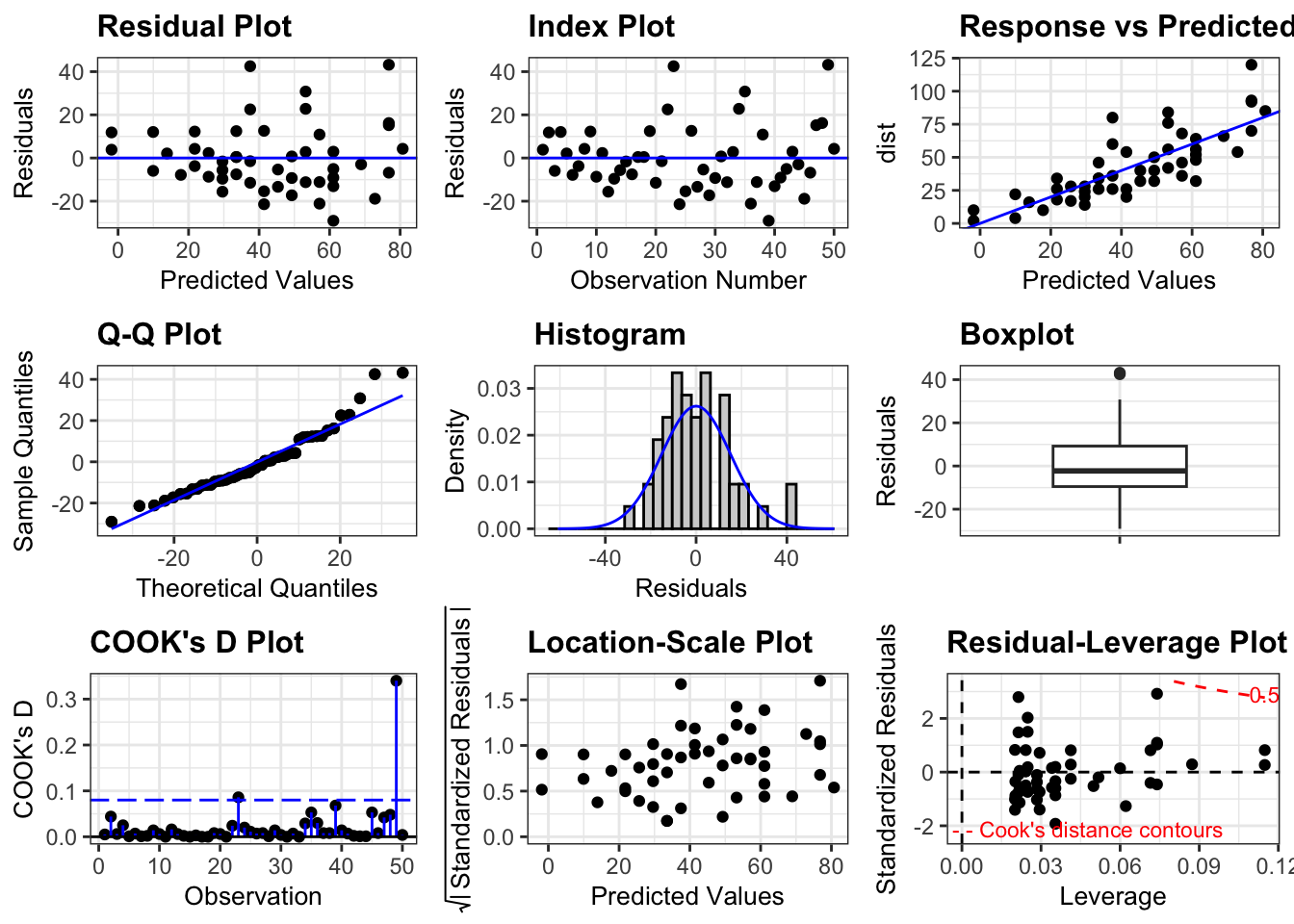
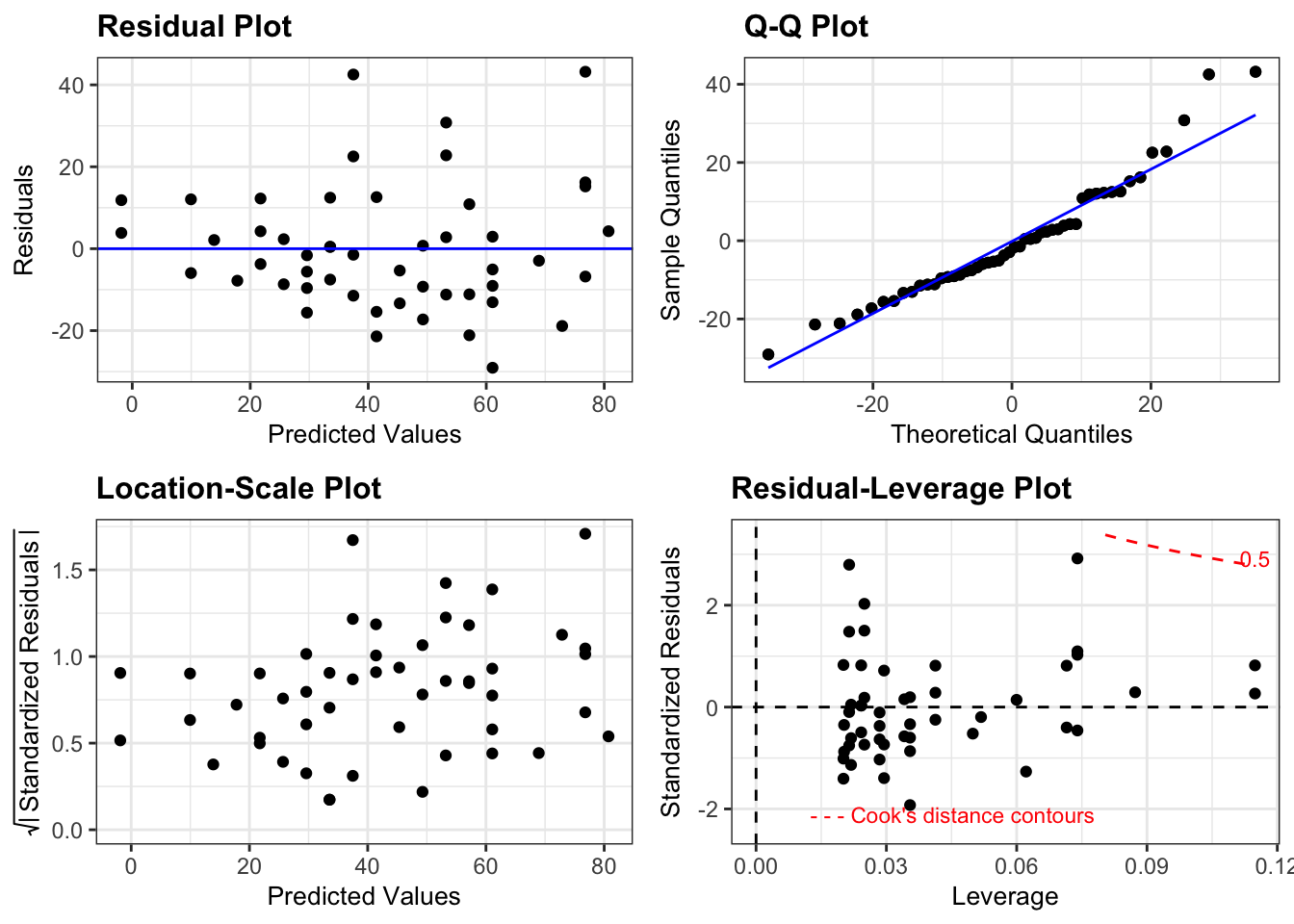
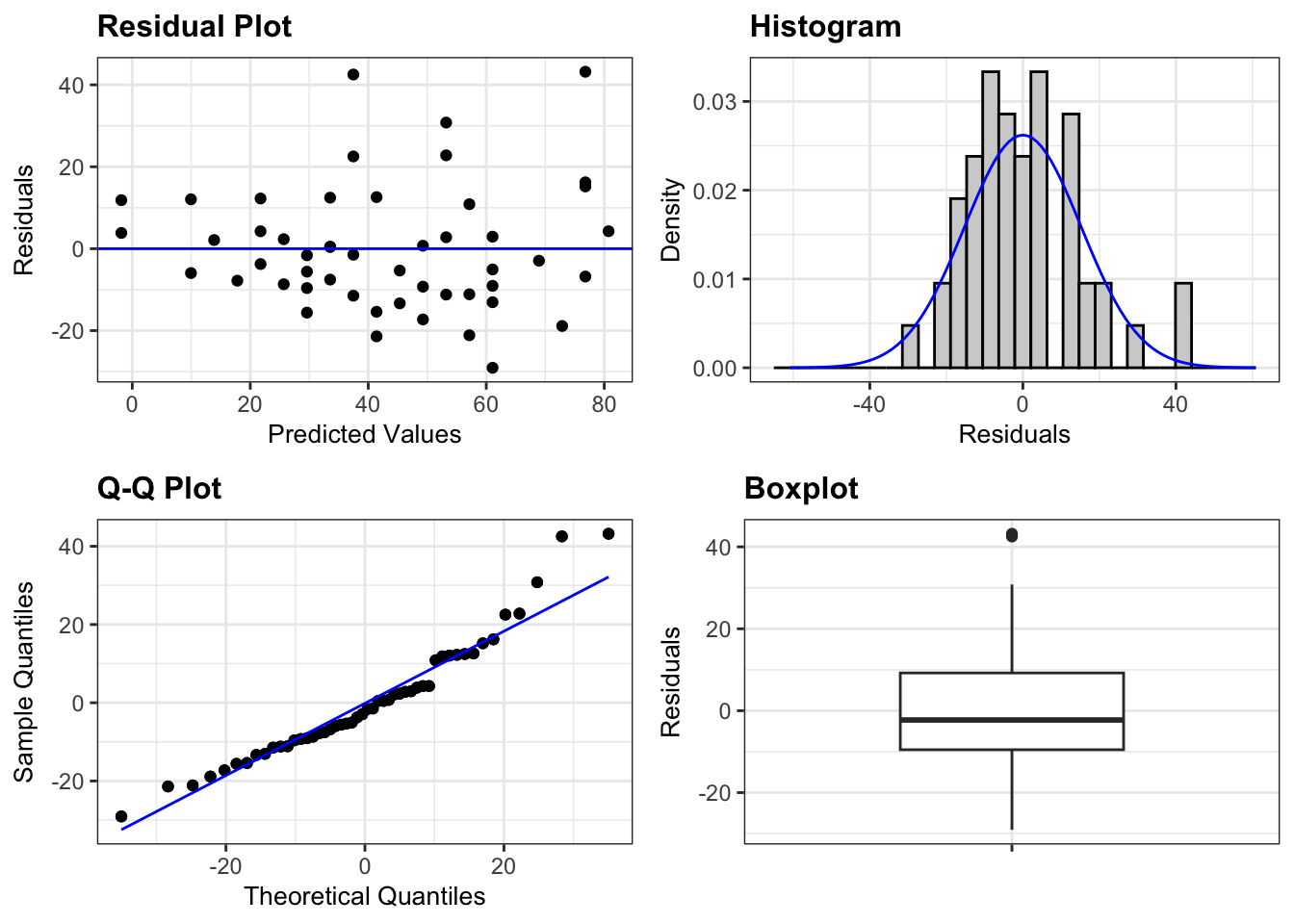
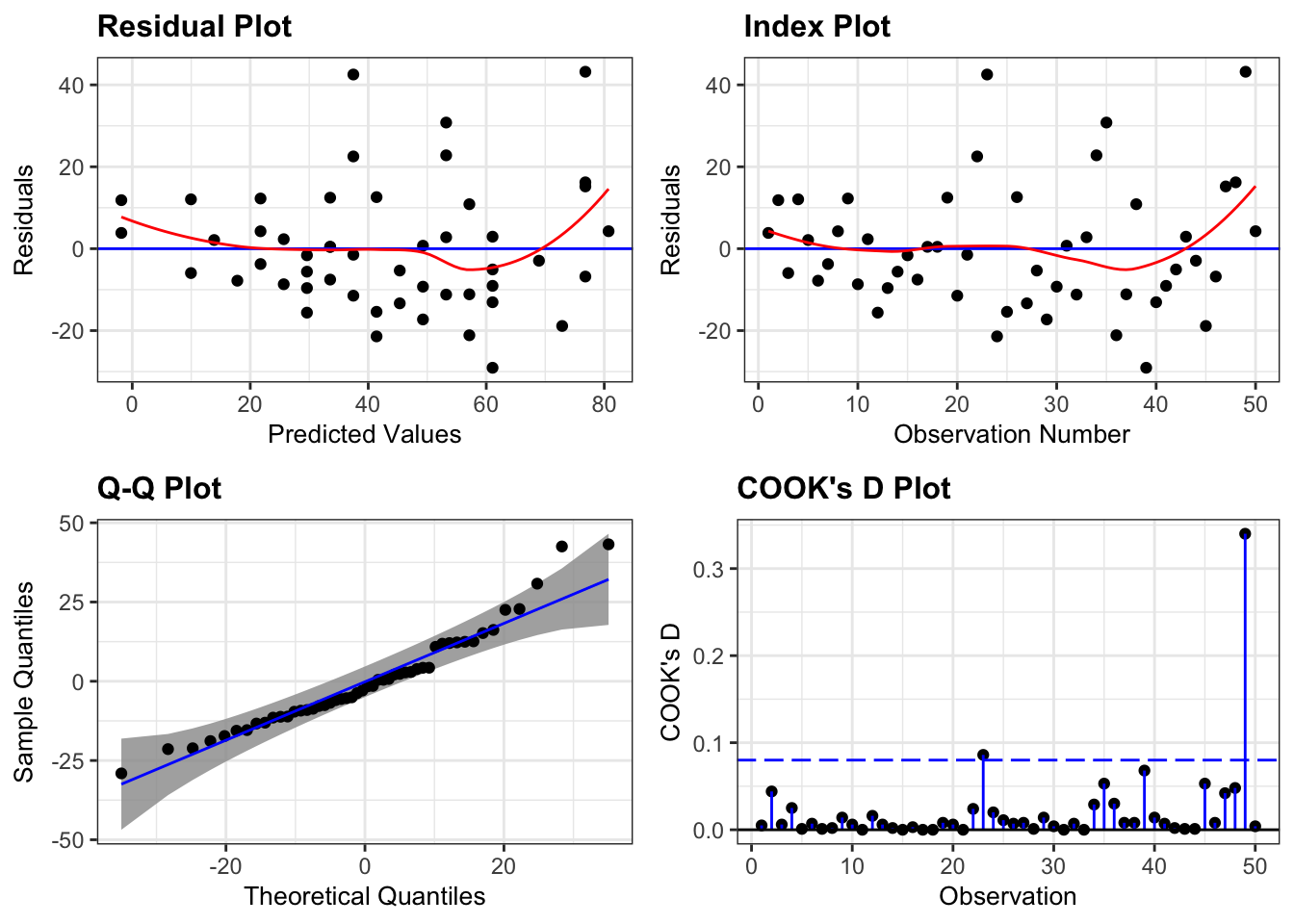
Diagnostic plots are used to help evaluate model assumptions. As a general rule, we are looking for patterns in these diagnostic plots. Sometimes, those patterns are explainable by the structure of the data. Other times, these patterns are due to violations of the model assumptions.
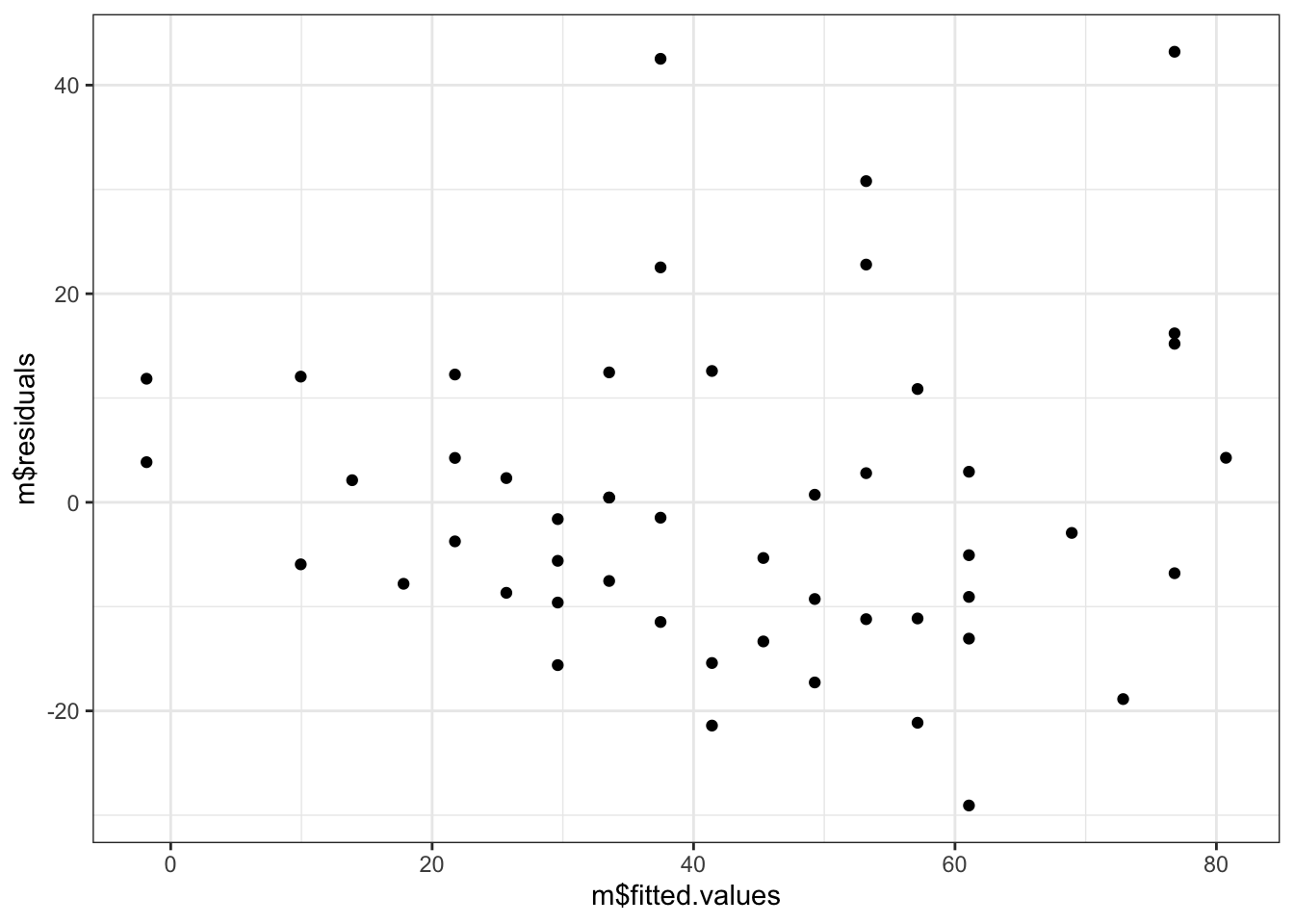
34.5.1 Residuals vs fitted values
# Residuals vs fitted valuesggplot( # no data argumentmapping =aes(x = m$fitted.values, y = m$residuals)) +geom_point()
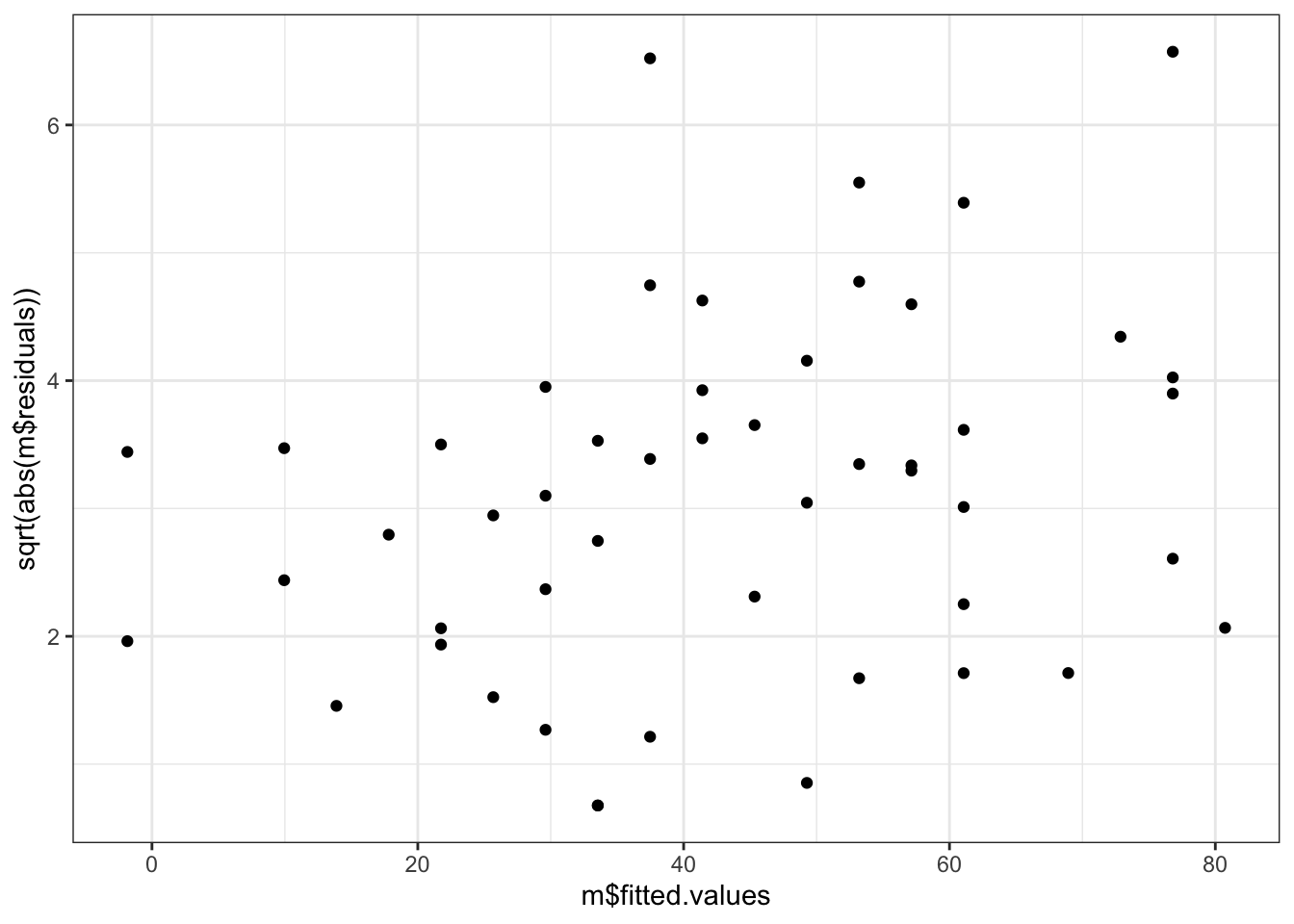
# Alternative residuals v fittedggplot( # no data argumentmapping =aes(x = m$fitted.values, y =sqrt(abs(m$residuals)))) +geom_point()
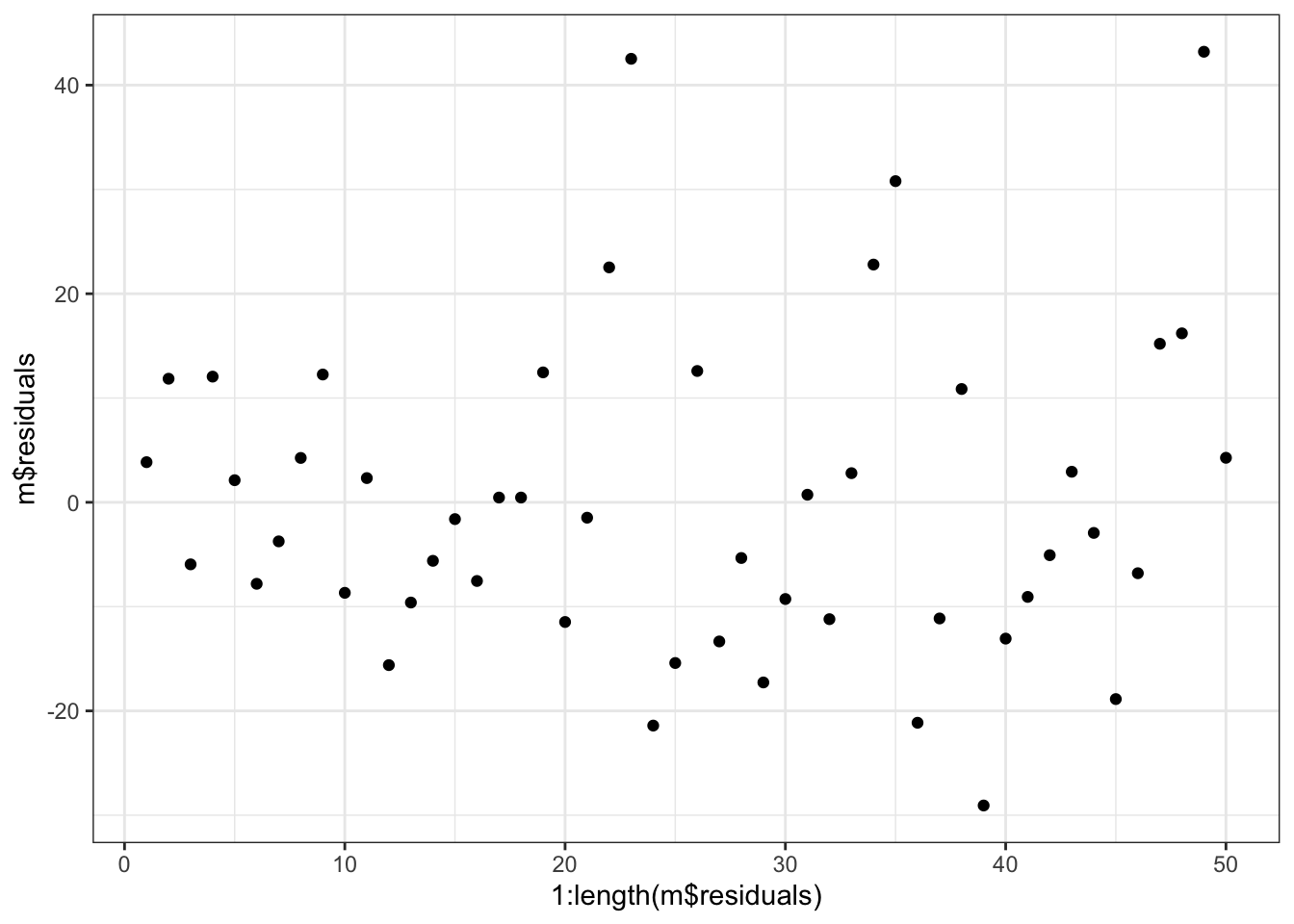
34.5.2 Residuals vs index
Since data are often recorded in temporal order, the row number for an observation can be used as a proxy for time. Thus, we can plot residuals vs index (row number) to (possibly) assess violates of independence due to time. Of course, if our
# Residuals versus indexggplot(mapping =aes(x =1:length(m$residuals),y = m$residuals)) +geom_point()
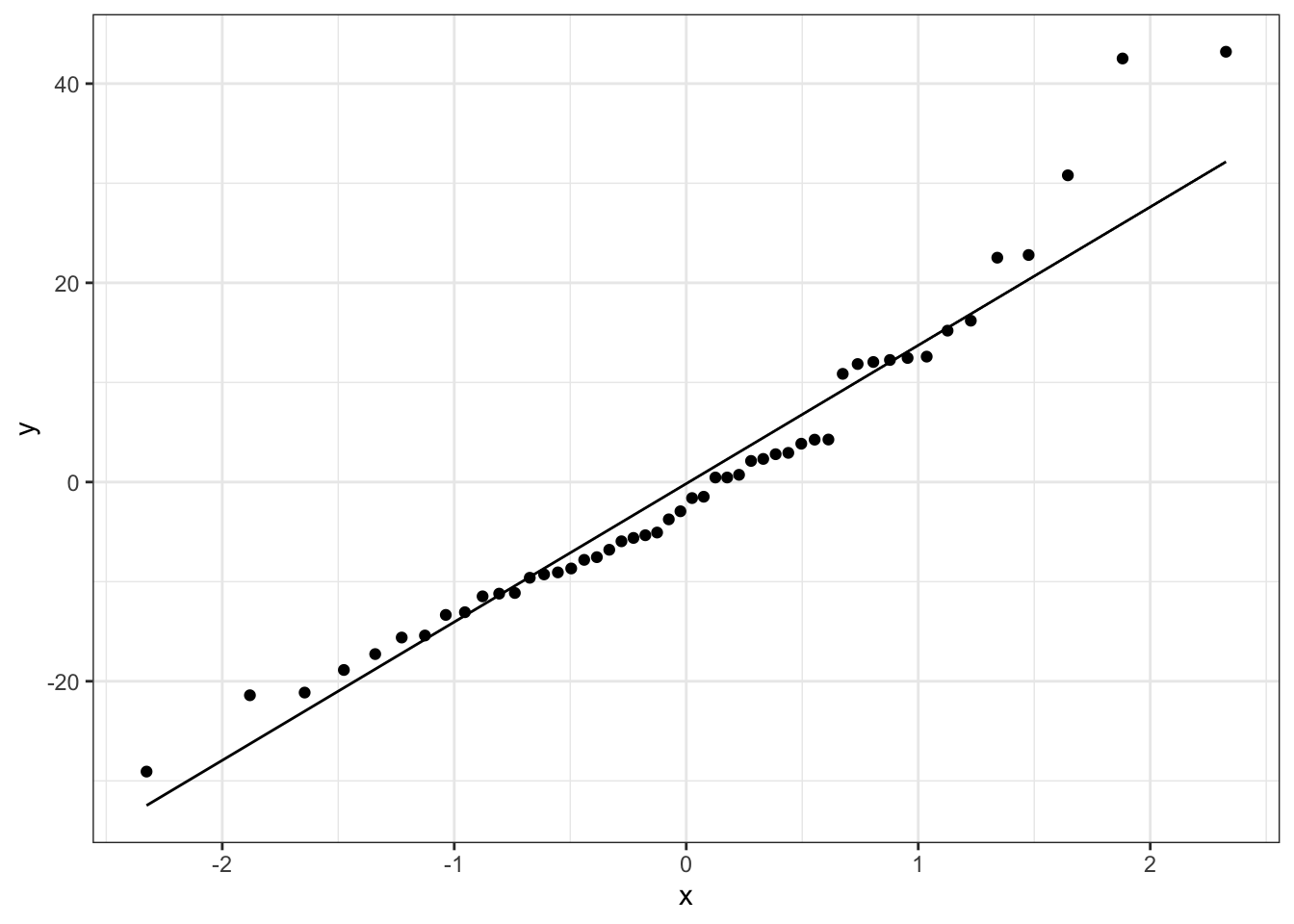
34.5.3 Normal qq-plots
While we could use histograms or density plots to try to evaluate normality, a much better plot for this purpose is a normal quantile-quantile (qq) plot. In this plot, data should generally fall along the line. Severe deviations from this line are indications of non-normality.
# Normal qq plotggplot( # no data argumentmapping =aes(sample = m$residuals)) +geom_qq() +geom_qq_line()
34.5.4 Residuals v explanatory
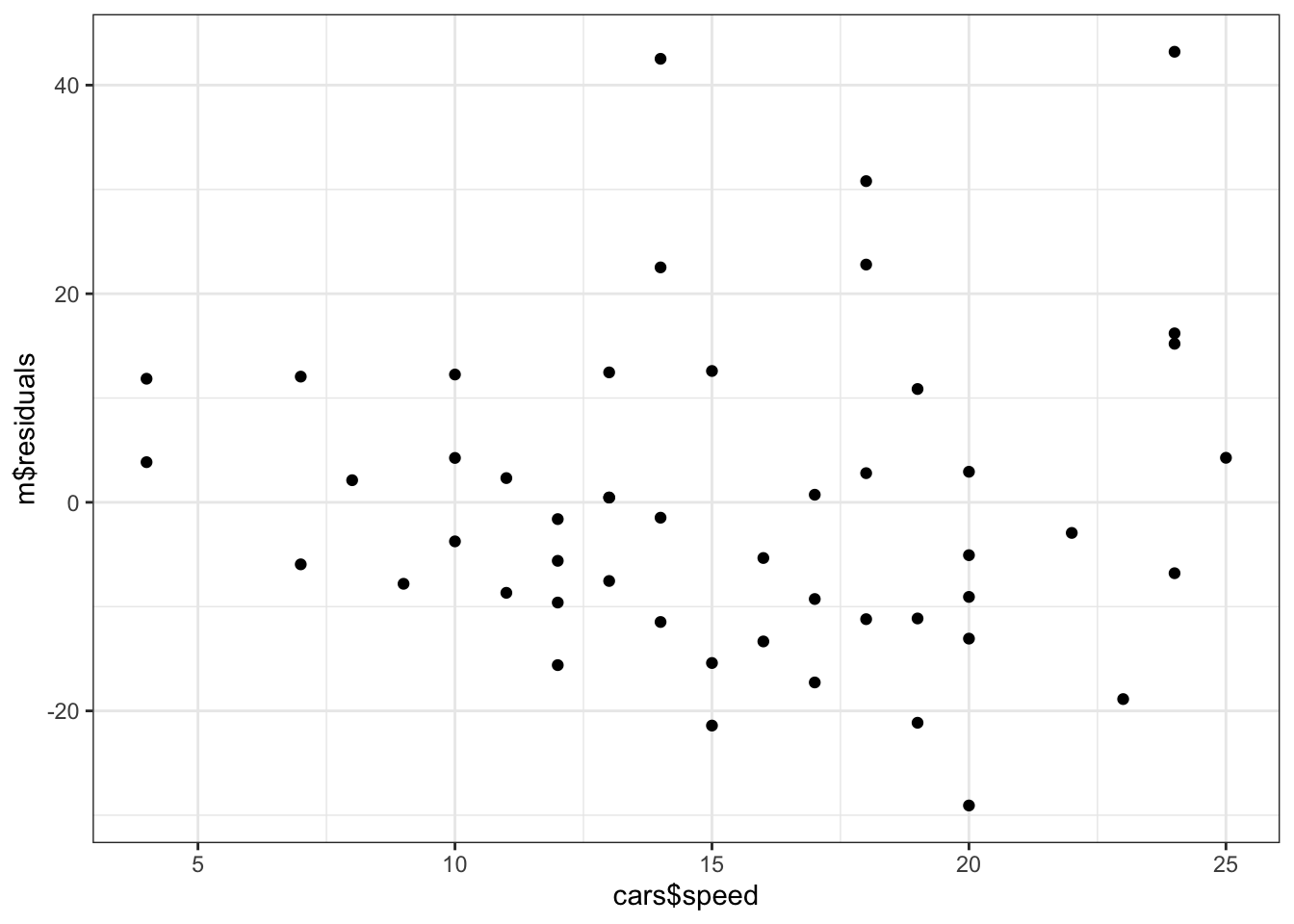
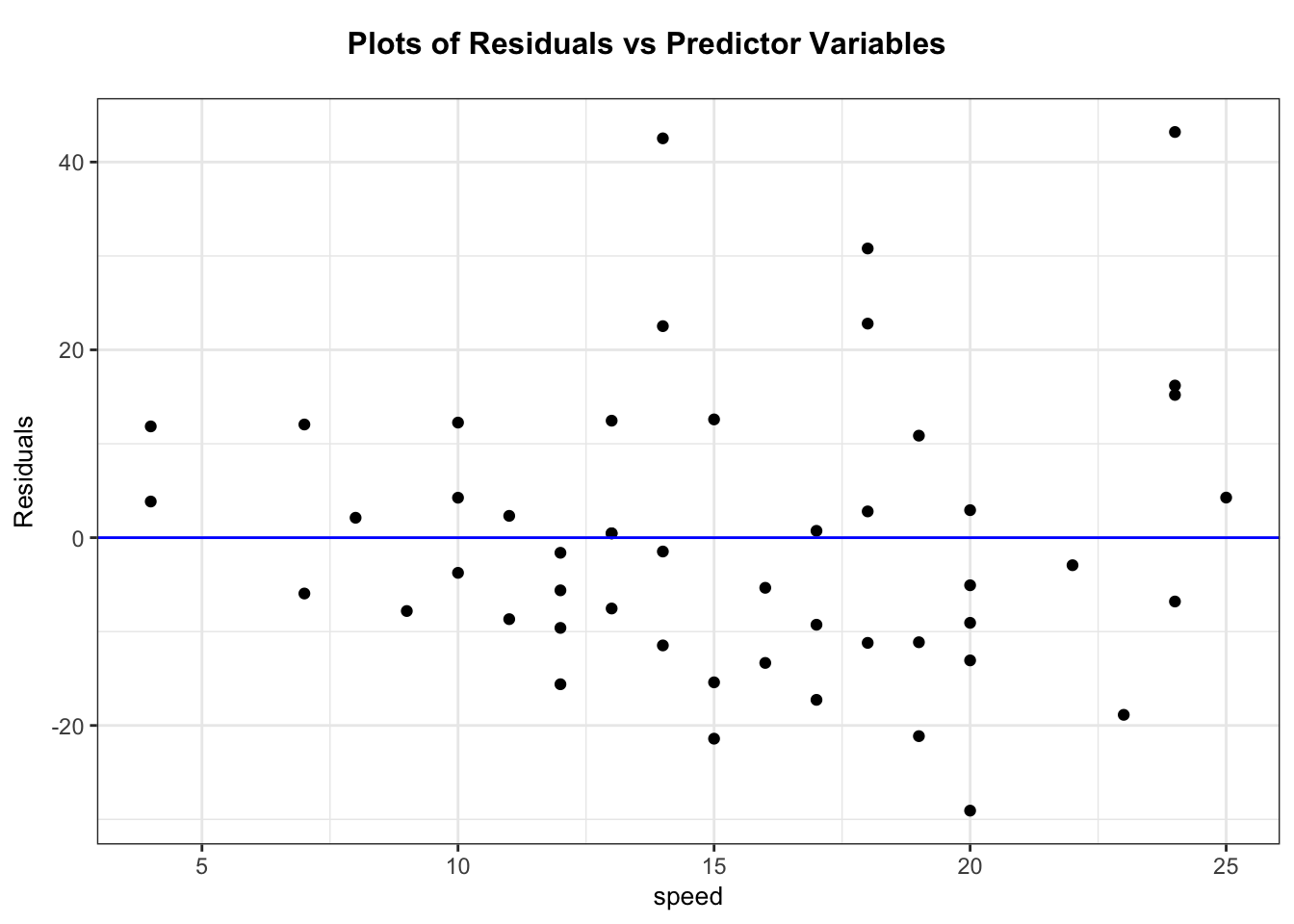
A good plot to use to evaluate the linearity assumption is residuals versus explanatory.
# Residual versus explanatoryggplot( # no data argumentmapping =aes(x = cars$speed, y = m$residuals)) +geom_point()
34.5.5 Default
A collection of plots can be produced quickly by plotting the fitted regression object.
`geom_smooth()` using formula = 'y ~ x'
`geom_smooth()` using formula = 'y ~ x'
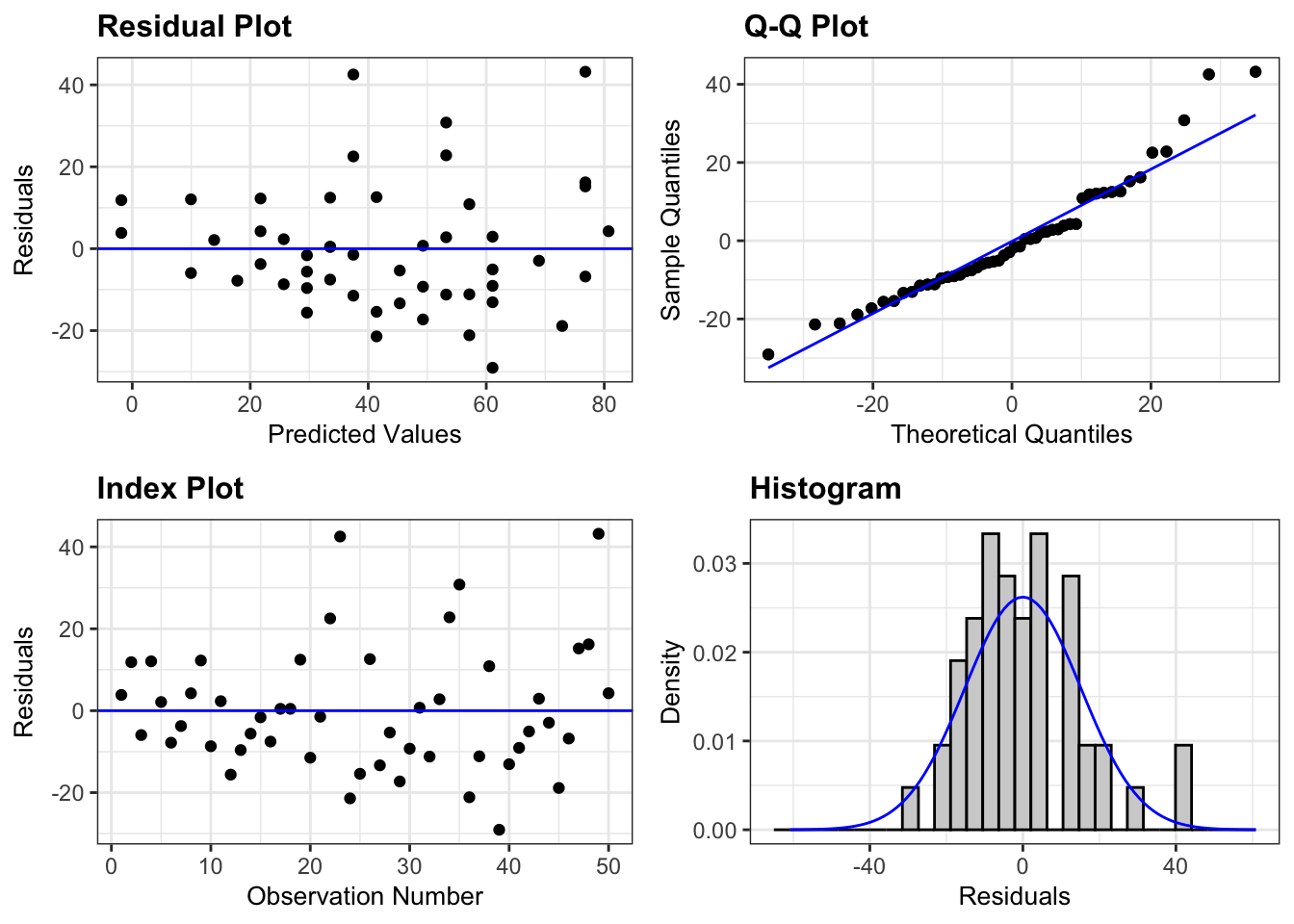
The ggResidpanel package also has a convenient function to plot the residuals versus explanatory variables.
# Residuals v explanatoryresid_xpanel(m)
34.6 Examples
Here we introduce three examples. The first example illustrates the origin of the term “regression”. The second example illustrates a situation where the diagnostic plots suggest the use of logarithms. The third example illustrates the use of a binary categorical variable within the context of a simple linear regression model.
34.6.1 Regression to the mean
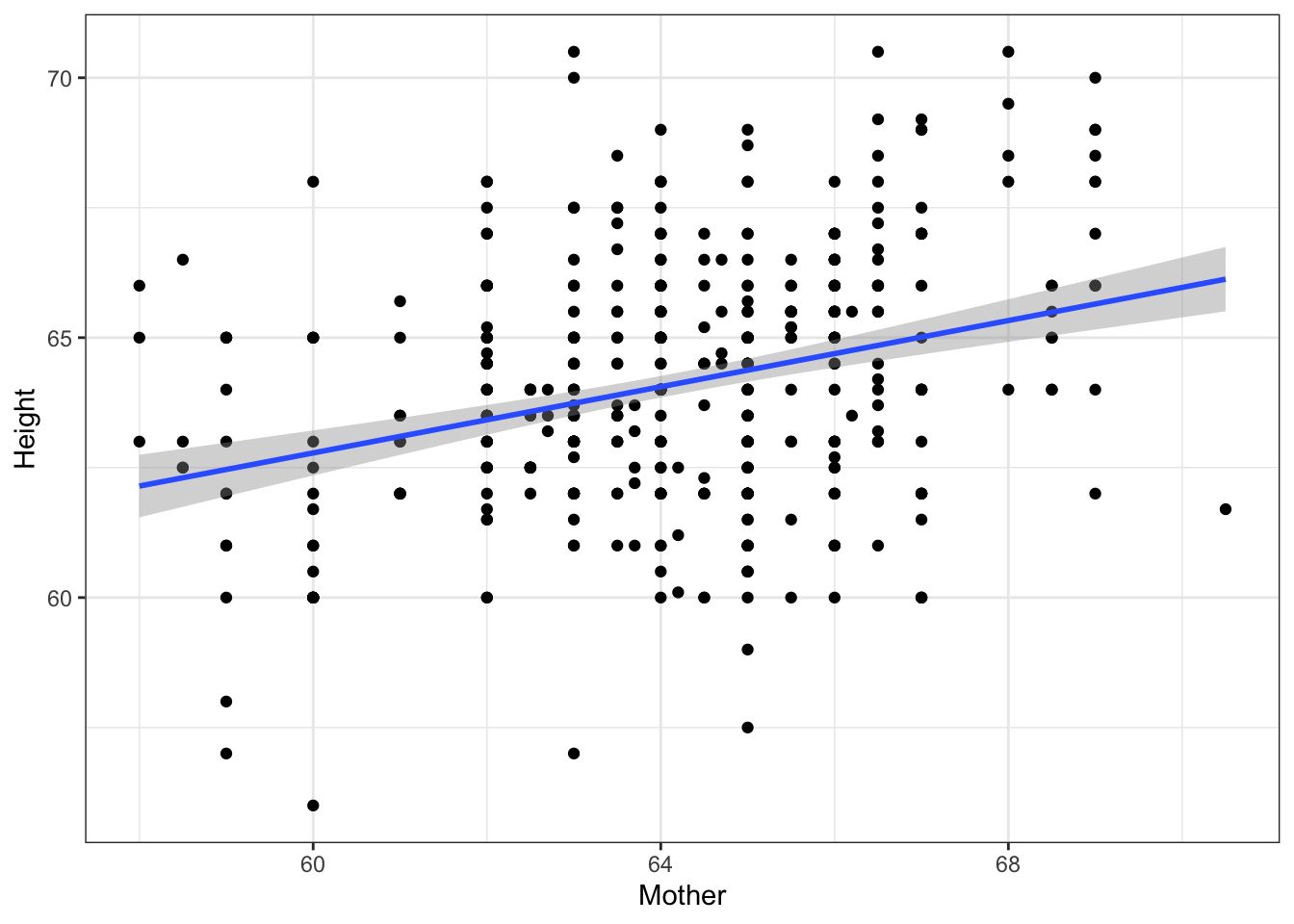
This data set contains the heights of parents and their children. It provides the origin of the term “regression” where children are, on average, closer to the mean height (for their sex) than their parents. This phenomenon is known as “regression to the mean”.
# Wrangle datad <- ex0726 |>filter(Gender =="female")# The data are clearly not independent# since there are multiple observations# from the same familyd |>group_by(Family) |>summarize(n =n()) |>filter(n >1)
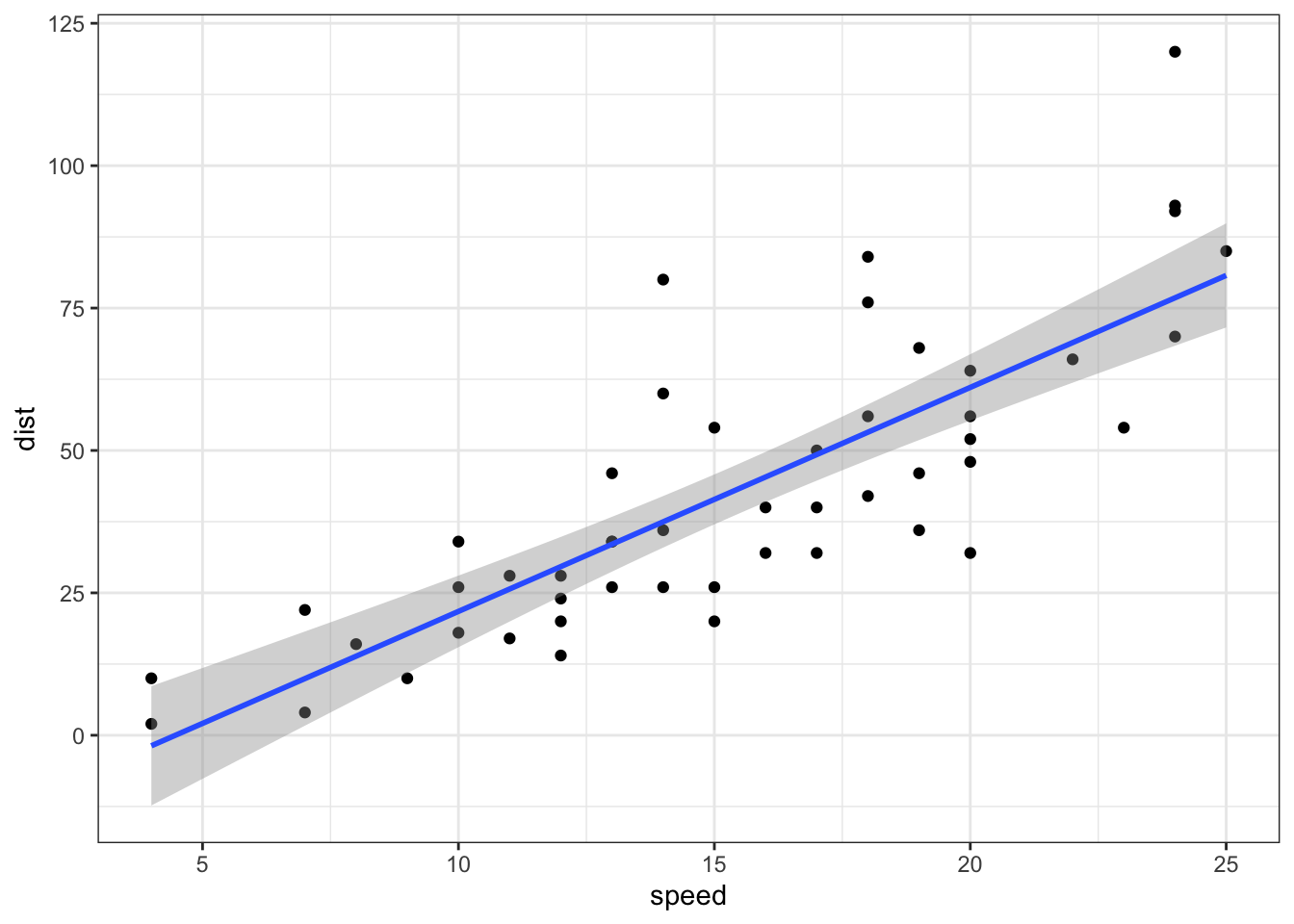
# Plot data with regression lineggplot(d,aes(x = Mother,y = Height)) +geom_point() +geom_smooth(method ="lm")
`geom_smooth()` using formula = 'y ~ x'
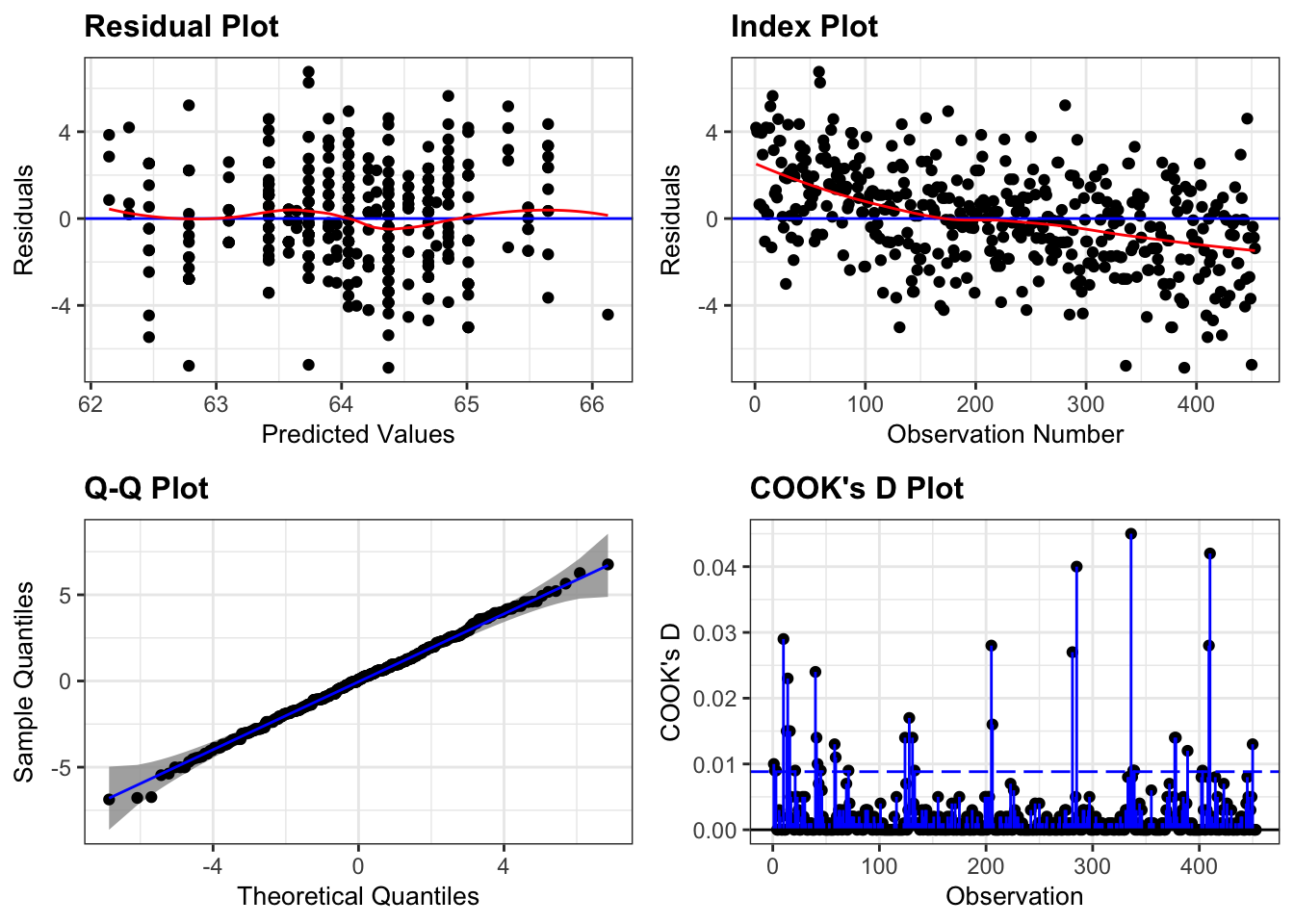
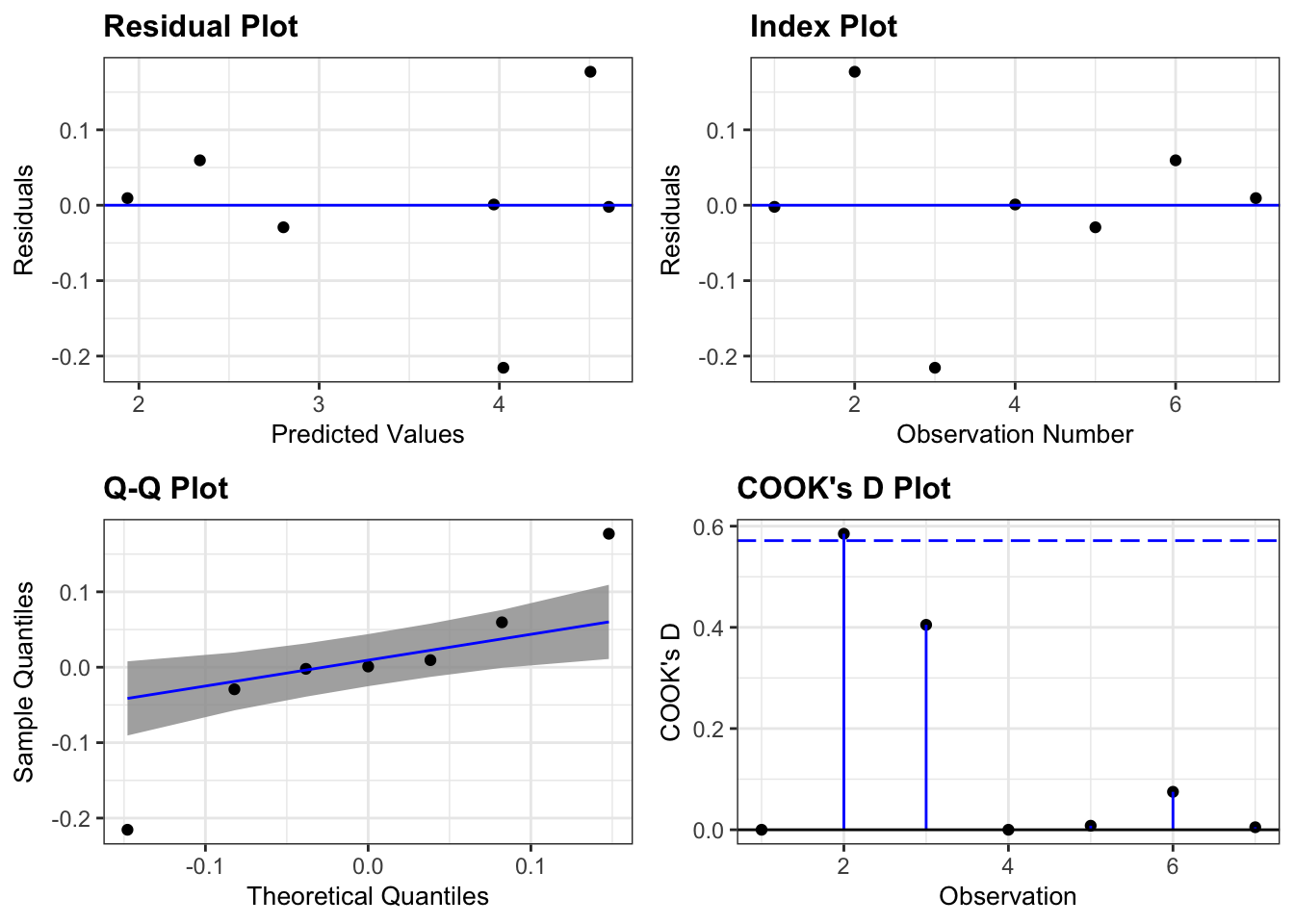
# Fit modelm <-lm(Height ~ Mother, data = d)# Assess diagnostic plotsresid_panel(m, plots = my_plots,qqbands =TRUE,smoother =TRUE)
`geom_smooth()` using formula = 'y ~ x'
`geom_smooth()` using formula = 'y ~ x'
34.6.2 Logarithmic transformation
# Exploratorysummary(case0801)
Area Species
Min. : 1.0 Min. : 7.00
1st Qu.: 18.5 1st Qu.: 13.50
Median : 3435.0 Median : 45.00
Mean :11615.1 Mean : 48.57
3rd Qu.:16807.5 3rd Qu.: 76.50
Max. :44218.0 Max. :108.00
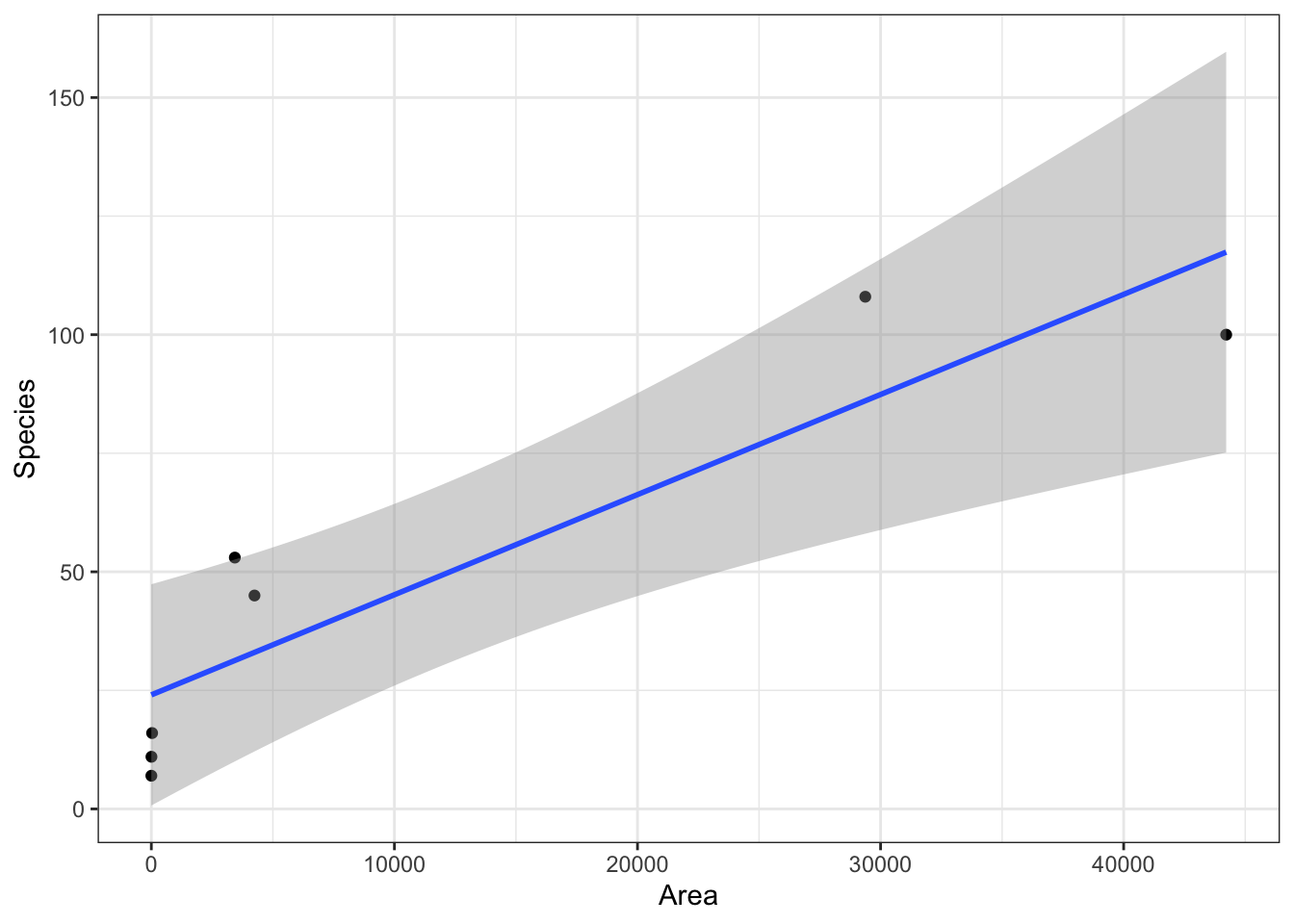
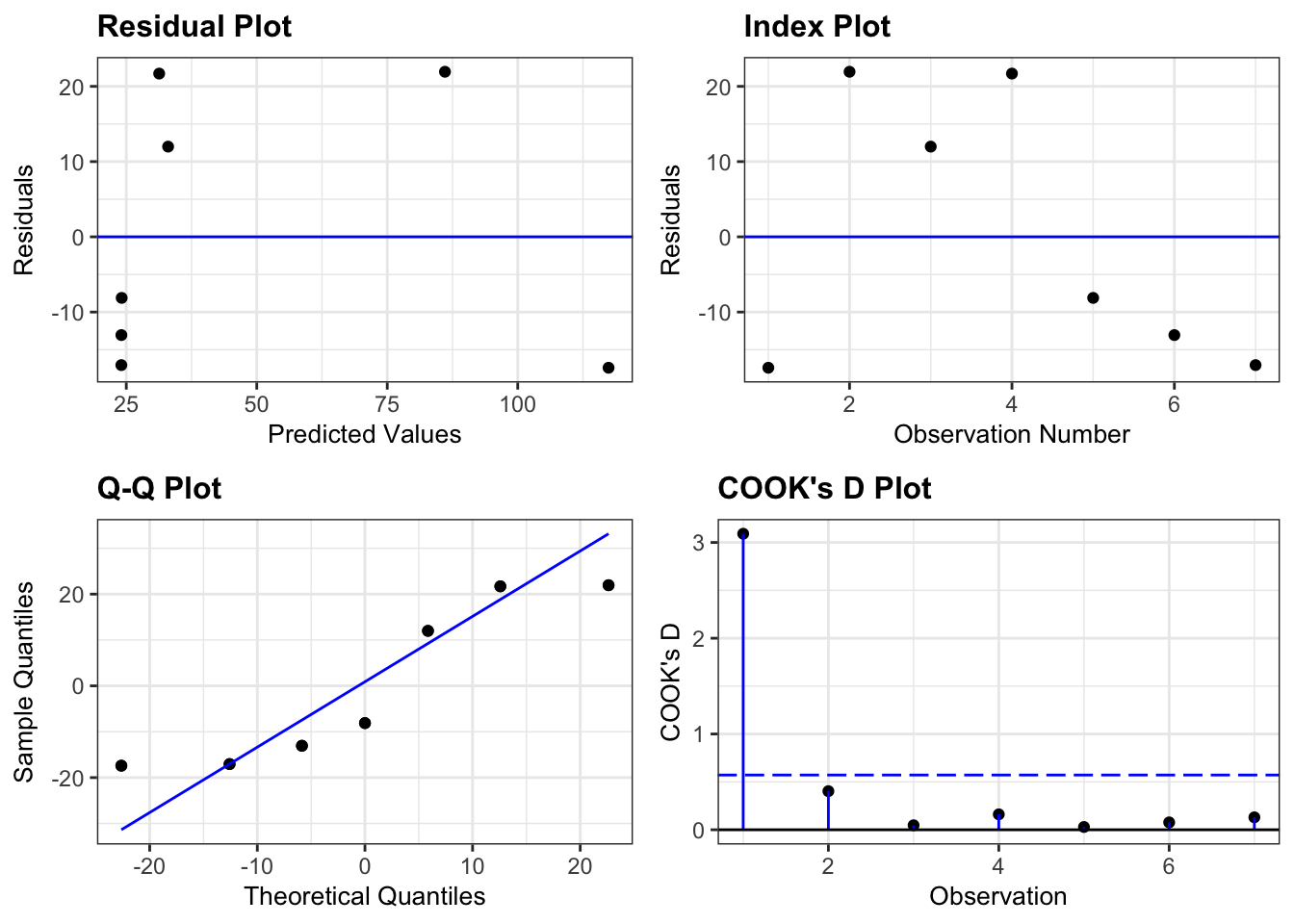
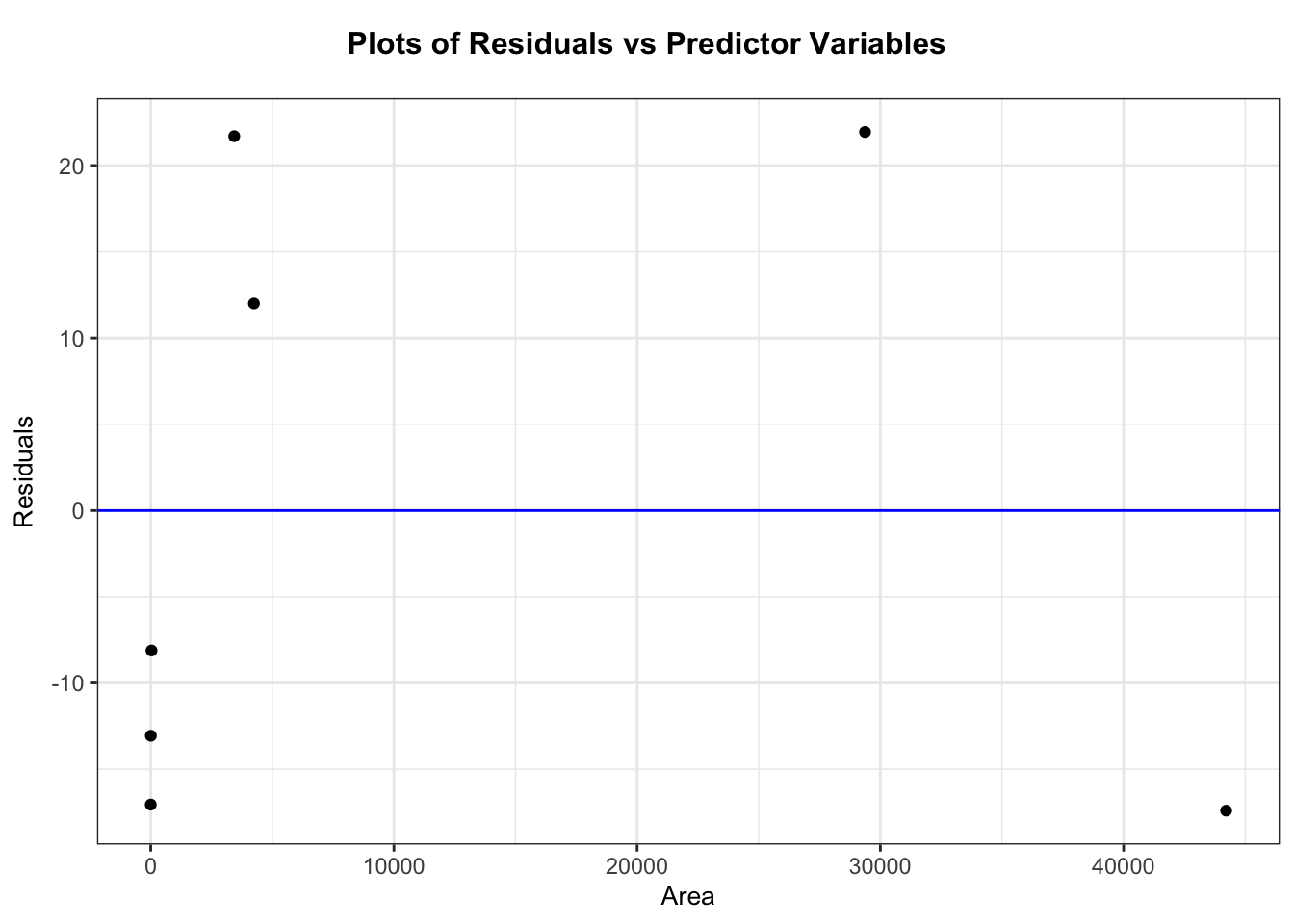
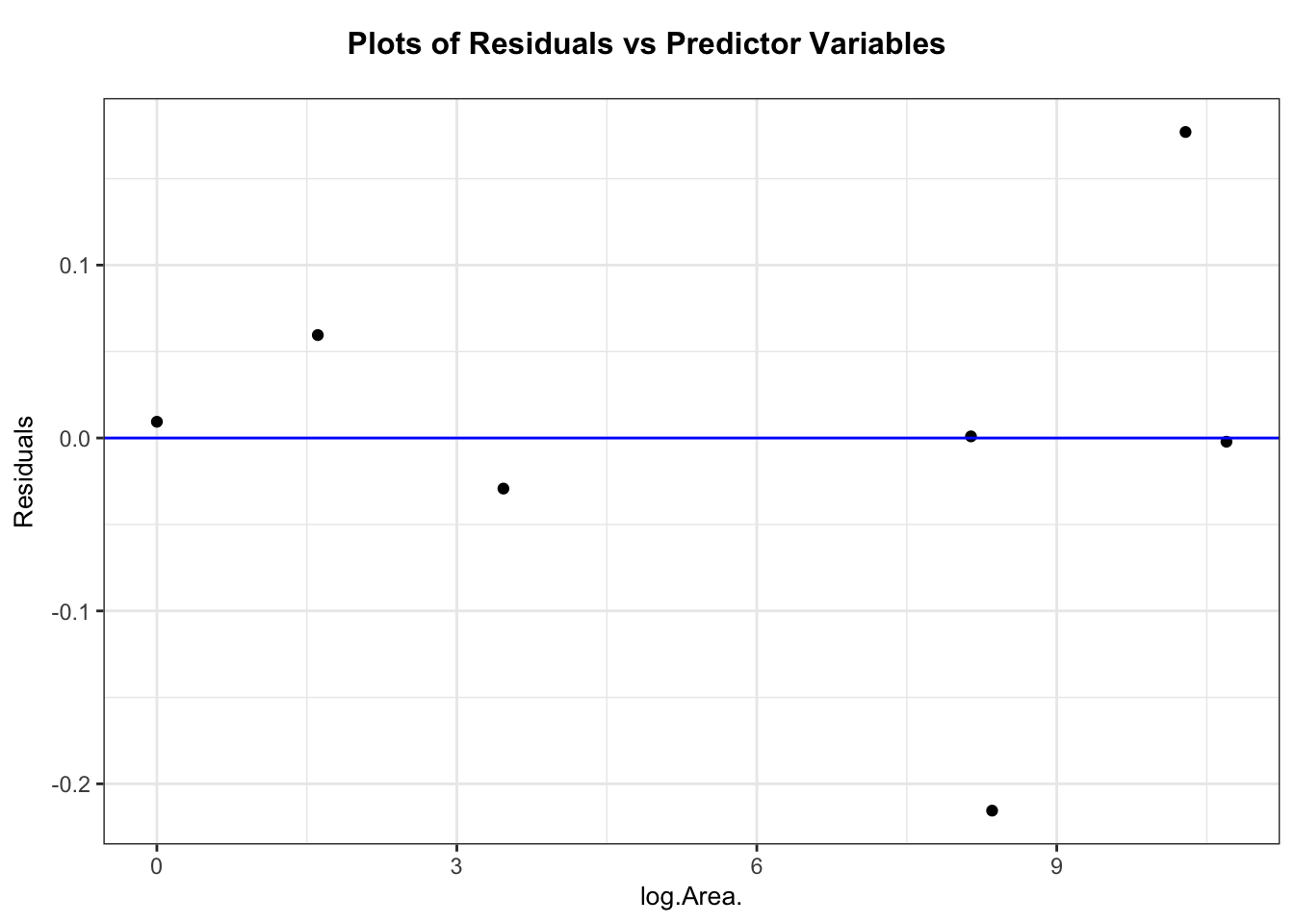
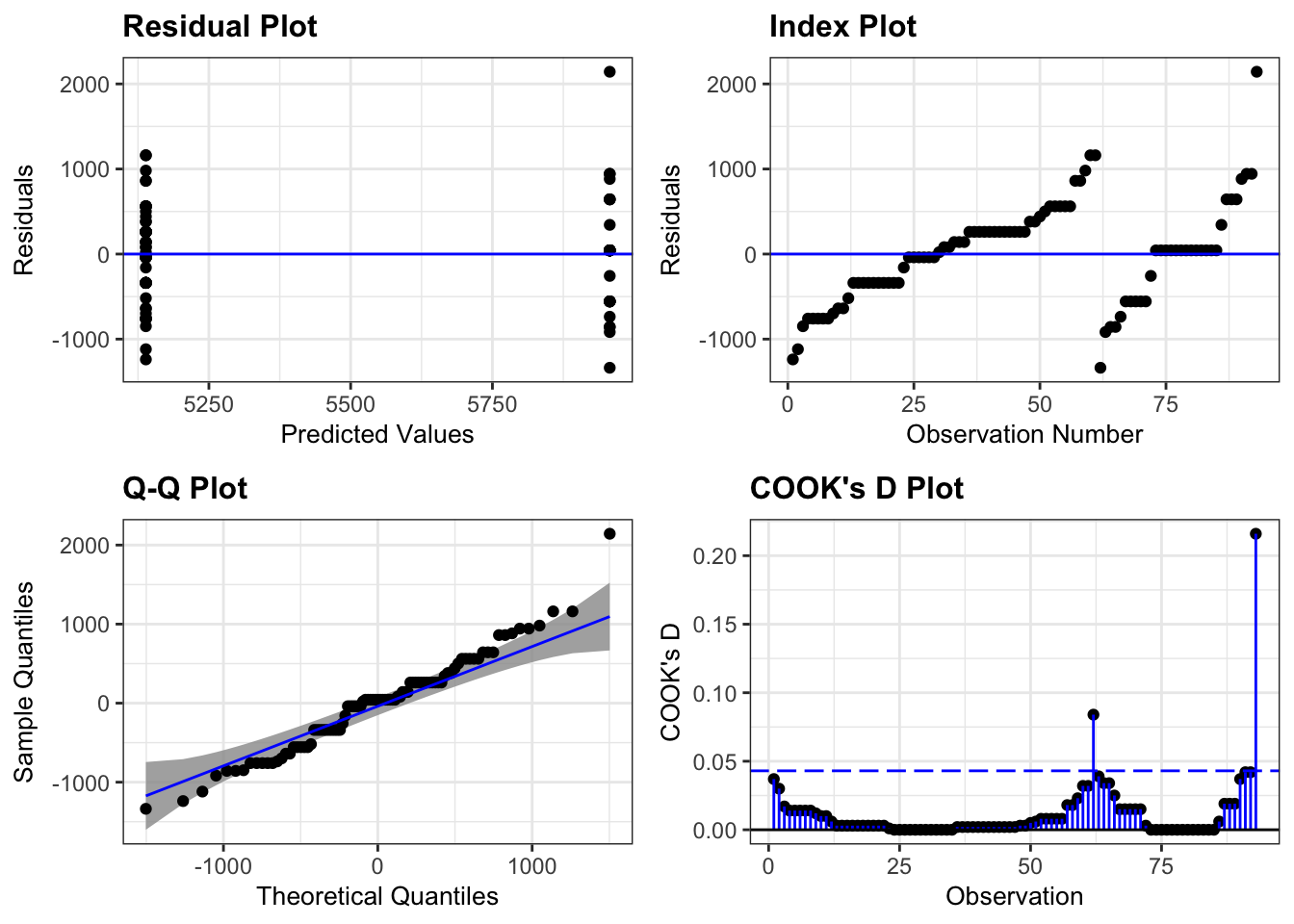
# Fit modelm <-lm(Species ~ Area, data = case0801)# Diagnostic plotsresid_panel(m, plots = my_plots)
resid_xpanel(m)
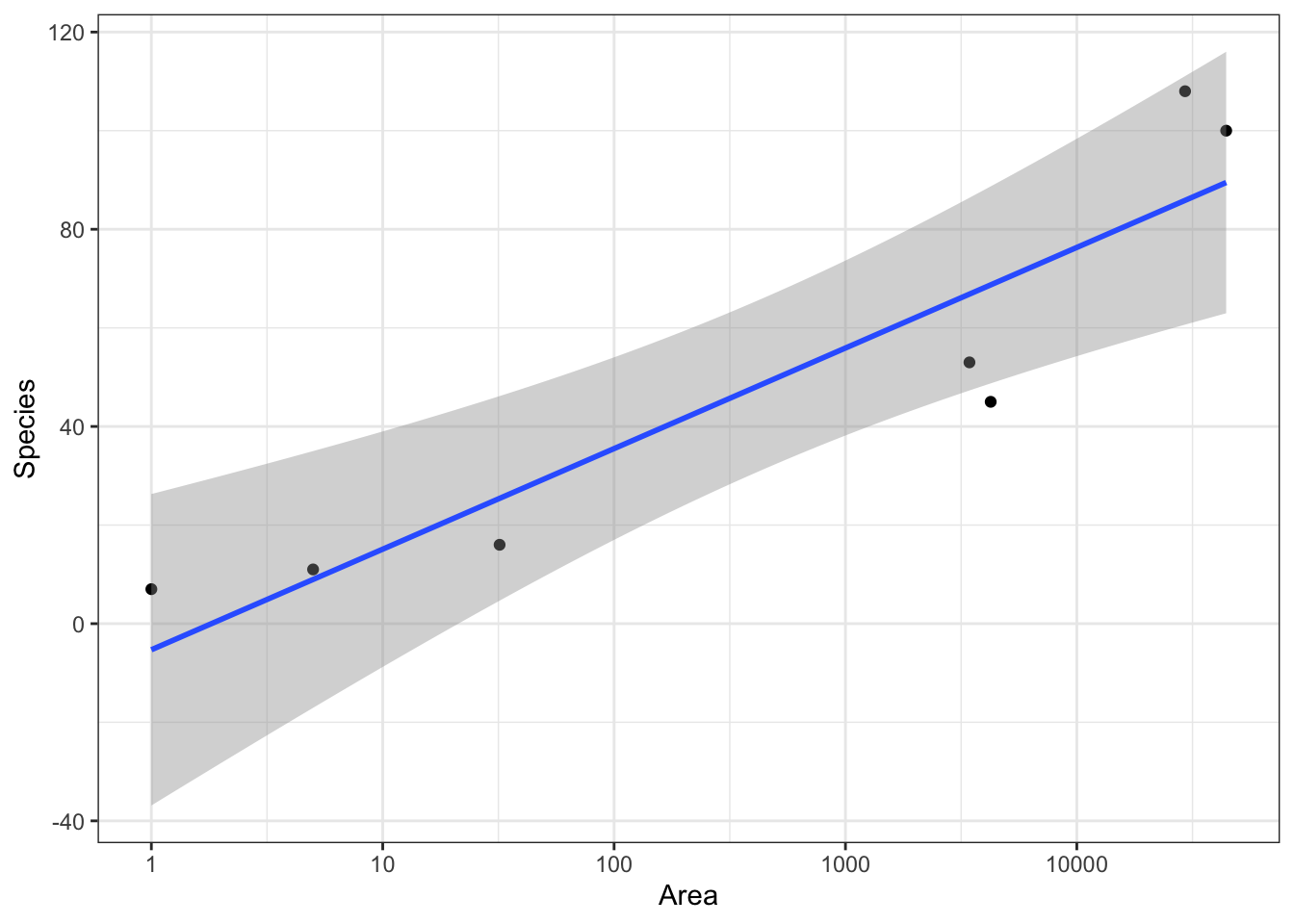
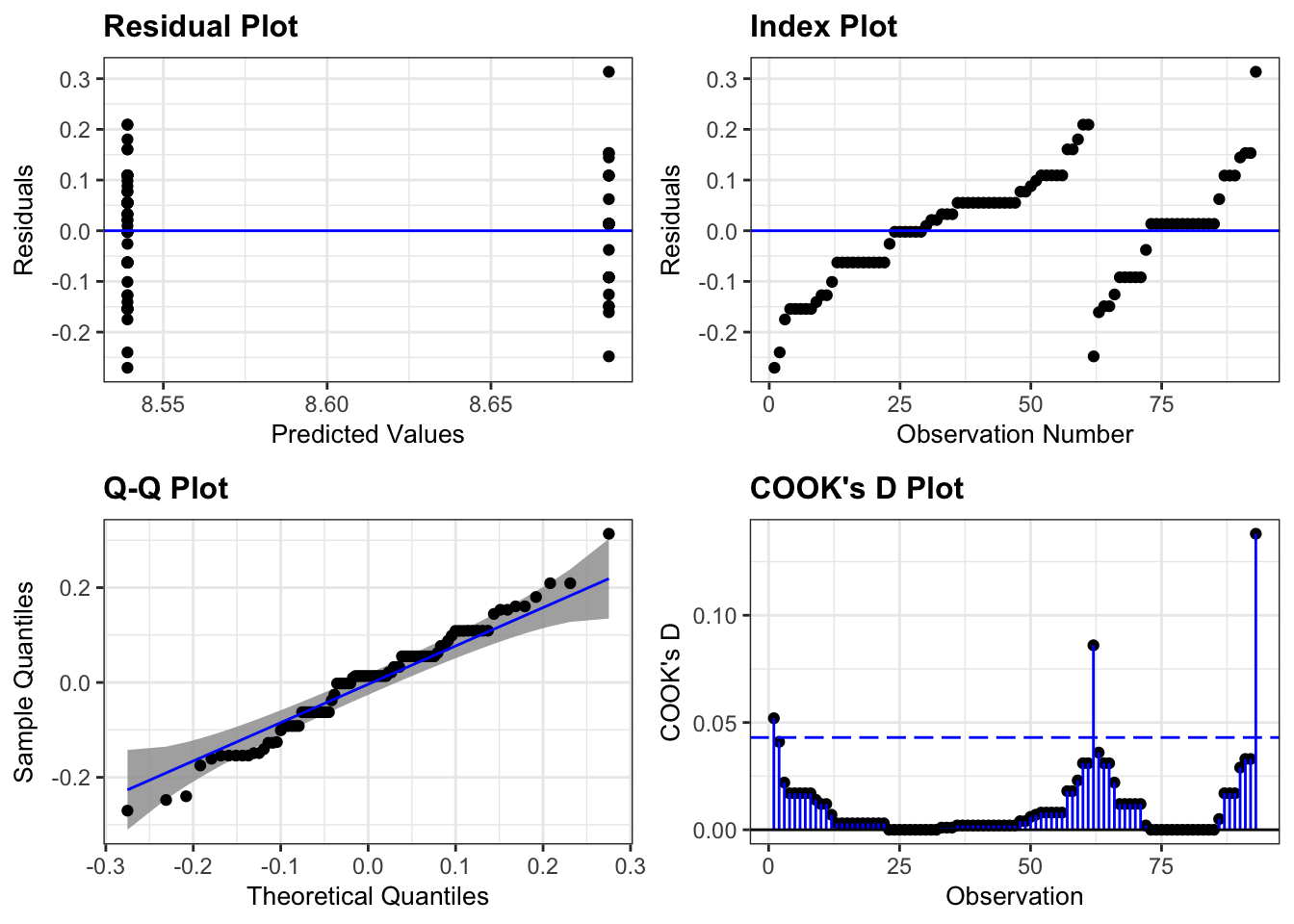
Try taking logarithsm
# Consider logarithms of both variablesg +scale_x_log10()
`geom_smooth()` using formula = 'y ~ x'
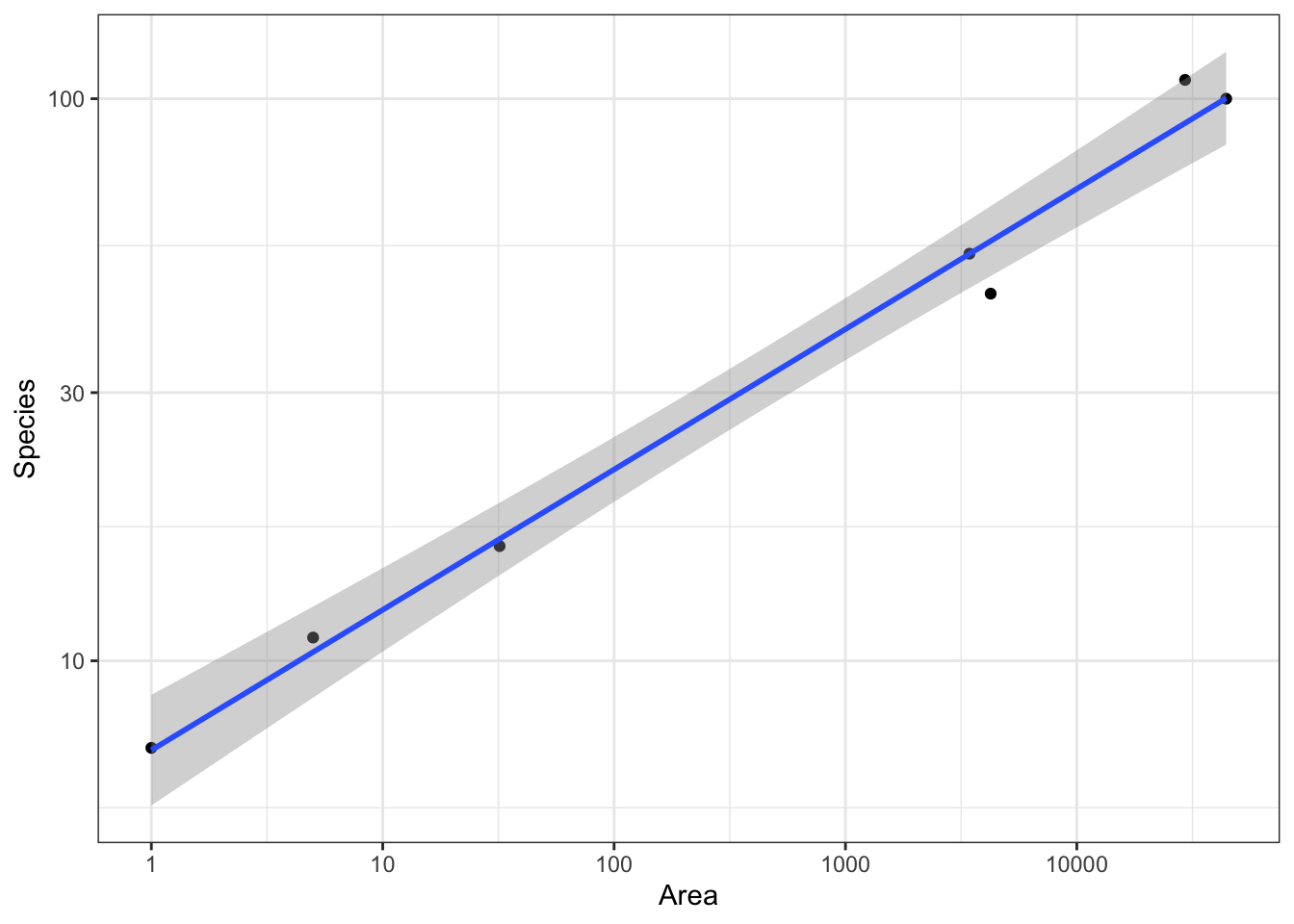
g +scale_x_log10() +scale_y_log10()
`geom_smooth()` using formula = 'y ~ x'
# Fit model with logarithmsm <-lm(log(Species) ~log(Area), data = case0801)# Diagnostic plotsresid_panel(m, plots = my_plots, qqbands =TRUE)
resid_xpanel(m)
34.6.3 Categorical explanatory variable
We can also fit a simple linear regression model when we have a binary categorical explanatory variable. Since the mathematics requires that \(X_i\) be numeric, the standard approach to a binary categorical variable is to encode the levels as 0 and 1. To do this, we create a dummy (or indicator) variable.
Generally, \[X_i = \left\{ \begin{array}{ll}
0 & \mbox{obs $i$ is reference level} \\
1 & \mbox{obs $i$ is NOT the reference level}
\end{array} \right.\]
Thus, we have to choose one of the two levels as the reference level. The reference level gets encoded as 0 and the other level as 1.
R indicates a categorical variable level by including the variable name and the level, e.g. SexMale. We can verify that this level has been encoded as a 1 and the reference level Female as a 0.
Call:
lm(formula = Salary ~ X, data = d)
Coefficients:
(Intercept) X
5139 818
If you want to change the reference level, you can change order of the factor.
lm(Salary ~ Sex, data = case0102 |>mutate(Sex =relevel(Sex, ref ="Male")))
Call:
lm(formula = Salary ~ Sex, data = mutate(case0102, Sex = relevel(Sex,
ref = "Male")))
Coefficients:
(Intercept) SexFemale
5957 -818
When the explanatory variable is categorical, the “slope” is the difference between the means of the two groups.
# Interpretationm <-lm(Salary ~ Sex,data = case0102)# 95% CI for mean difference in Salary (Male - Female)confint(m)[2,] |># Does this data prove there is a causal relationshipround() # between Salary and Sex?
An alternative is to model the logarithm of Salary. If you do, \(e^{\beta_1}\) is the multiplicative change in median salary from the reference level to the other level.
# 95% CI for multiplicative change in median Salary (Male / Female)confint(m)[2,] |>exp() |>round(2)
2.5 % 97.5 %
1.10 1.21
34.7 Summary
Simple linear regression models are used when the response variable is continuous and the explanatory variable is continuous or a binary categorical variable. When the explanatory variable is a binary categorical variable, then the results are the same as the two-sample t test when the variance in the two groups is assumed to be equal.