── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library("gridExtra")
Attaching package: 'gridExtra'
The following object is masked from 'package:dplyr':
combine
library("Sleuth3")
Logistic regression can be used when your response variable is a count with a known maximum. Similar to regression, explanatory variables can be continuous, categorical, or both. Here we will consider models up to two explanatory variables.
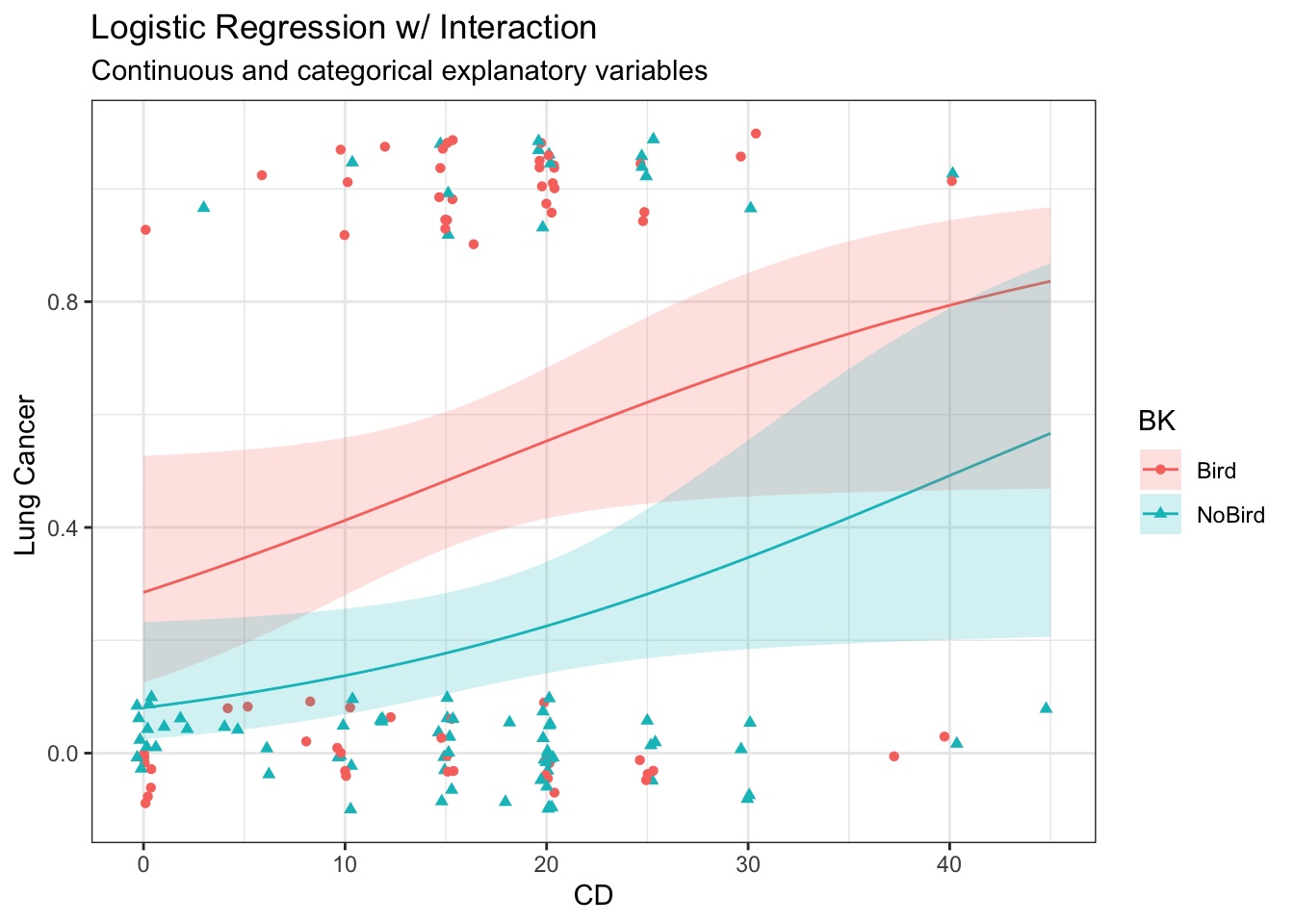
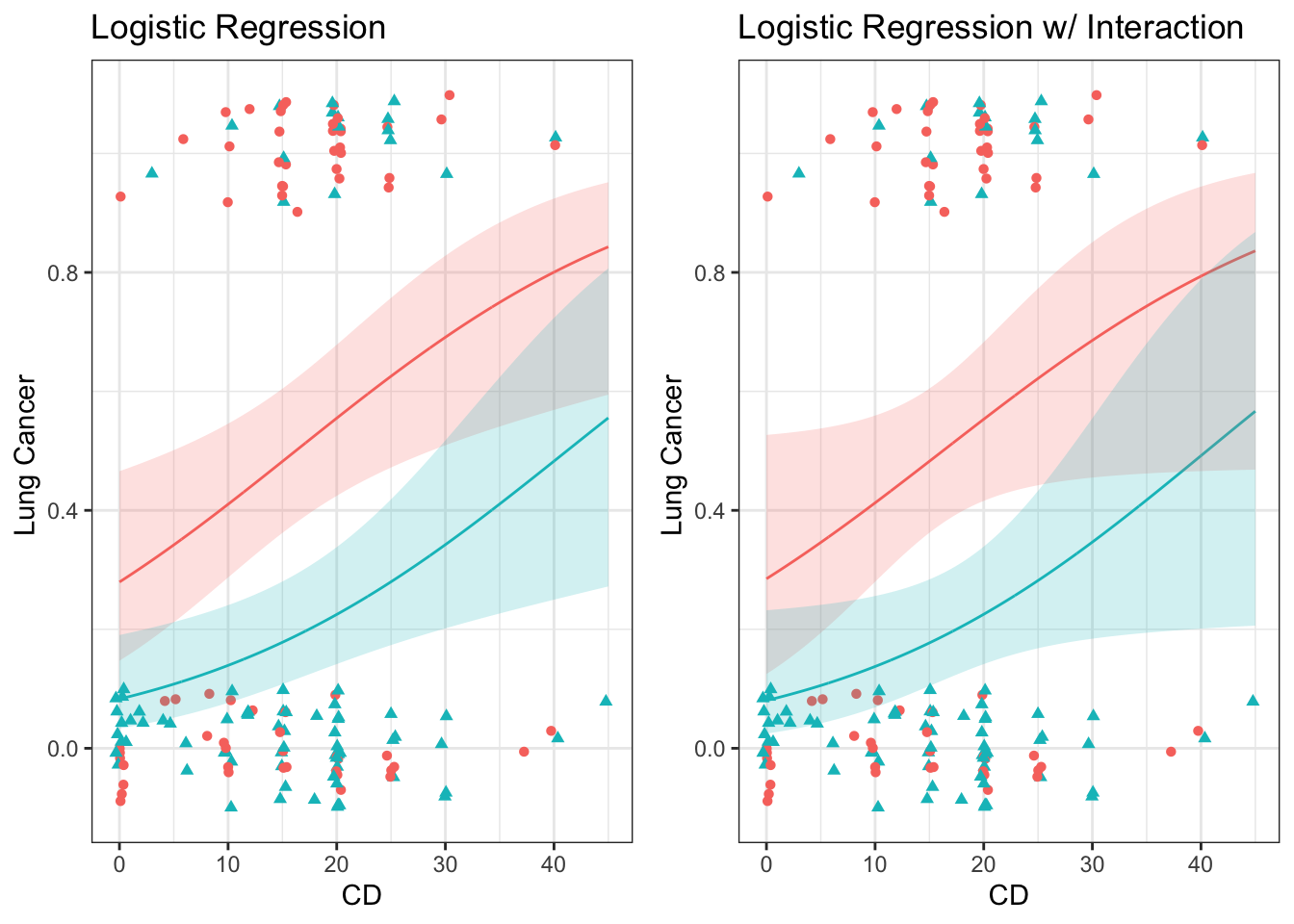
When there are two (or more) explanatory variables, we can consider a main effects model or models with interactions. The main effects model will result in parallel lines or line segments while the interaction model will result in more flexible lines or line segments. These lines will be straight when plotting the response variable on a logistic axis, although we will rarely do so since the interpretation is very difficult.
37.1 Model
Let \(Y_i\) be the number of successes out of \(n_i\) attempts. The logistic regression model assumes Assume \[
Y_i \stackrel{ind}{\sim} Bin(n_i, p_i), \quad
\mbox{logit}(p_i) = \log\left(\frac{p_i}{1-p_i} \right) =
\beta_0 + \beta_1X_{i,1} + \cdots + \beta_{p} X_{i,p}
\] where \(Bin\) designates a binomial random variable and, for observation \(i\),
\(p_i\) is the probability of success
\(p_i/(1-p_i)\) is the odds, and
\(\log[p_i/(1-p_i)]\) is the log-odds.
A common special case of this model is when \(n_i=1\) for all \(i\). In this situation, the response is binary since \(Y_i\) can only be 0 or 1.
37.1.1 Assumptions
The assumptions in a logistic regression are
observations are independent
observations have a binomial distribution (each with its own mean)
and
the relationship between the probability of success and the explanatory variables is through the \(\mbox{logit}\) function.
Later we will need the inverse of the logit function. We will call this expit.
# Inverse of logit functionexpit <-function(x) {1/ (1+exp(-x))}
37.1.2 Interpretation
When no interactions are in the model, an exponentiated regression coefficient is the multiplicative effect on the odds for a 1 unit change in the explanatory variable when all other explanatory variables are help constant. Mathematically, we can see this through \[
\frac{p'}{1-p'} = e^{\beta_j} \times \frac{p}{1-p}
\] where \(p\) is the probability when \(X_j = x\) and \(p'\) is the probability when \(X_j = x+1\).
If \(\beta_p\) is positive, then \(e^{\beta_p} > 1\) and the mean goes up. If \(\beta_p\) is negative, then \(e^{\beta_p} < 0\) and the mean goes down.
37.1.3 Inference
Individual regression coefficients are evaluated using \(z\)-statistics derived from the Central Limit Theorem and data asymptotics. This approach is known as a Wald test. Similarly confidence intervals and prediction intervals are constructed using the same assumptions and are thus refered to as Wald intervals.
Collections of regression coefficients are evaluated with drop-in-deviance where the residual deviances from the model with and without these terms in the model are compared with a \(\chi^2\)-test.
37.2 Continuous variable
DISCLAIMER: The example used here is a case-control study and thus none we cannot estimate probabilities directly.
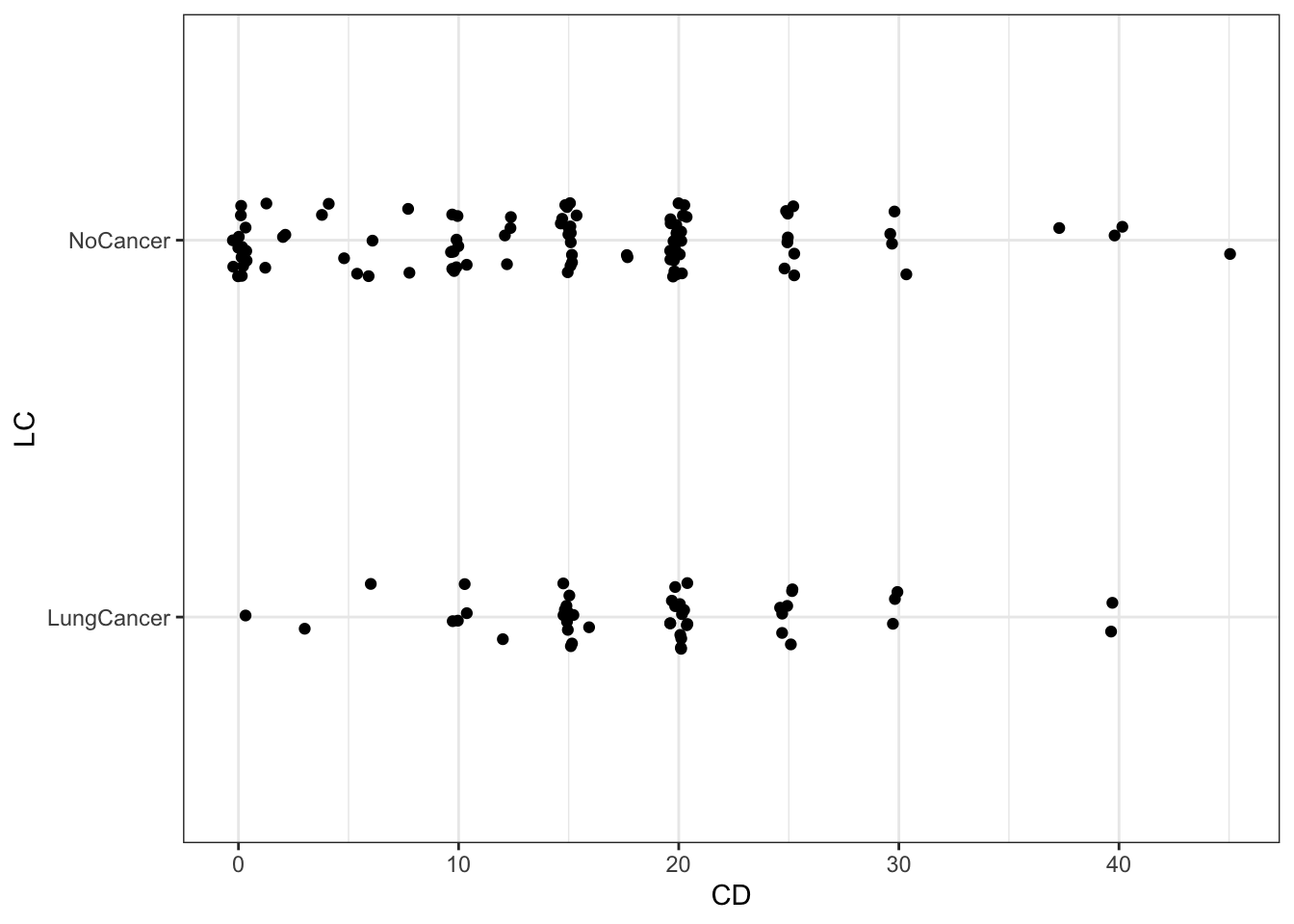
First we will consider simple logistic regression where there is a single continuous explanatory variable.
`summarise()` has grouped output by 'LC'. You can override using the `.groups`
argument.
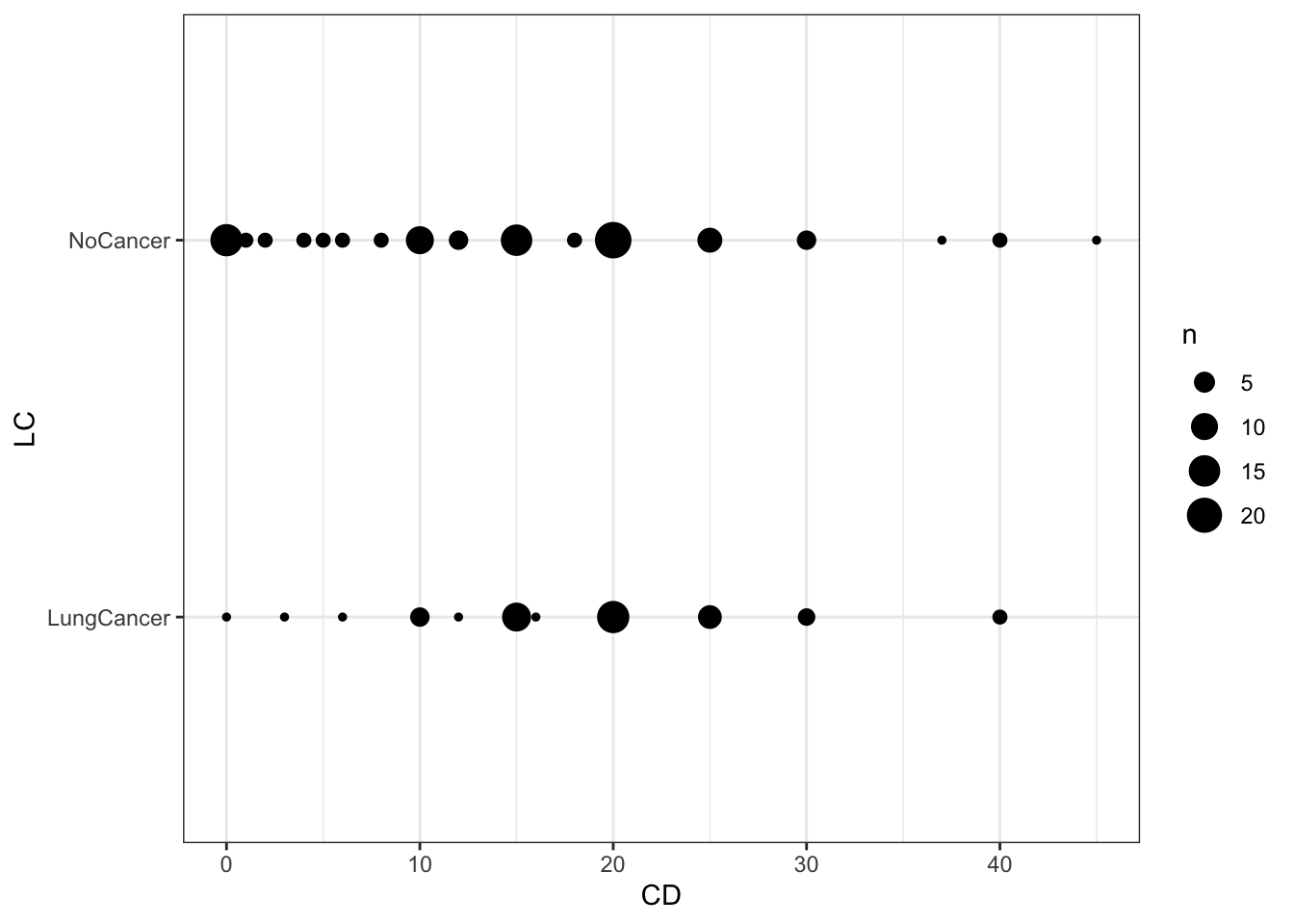
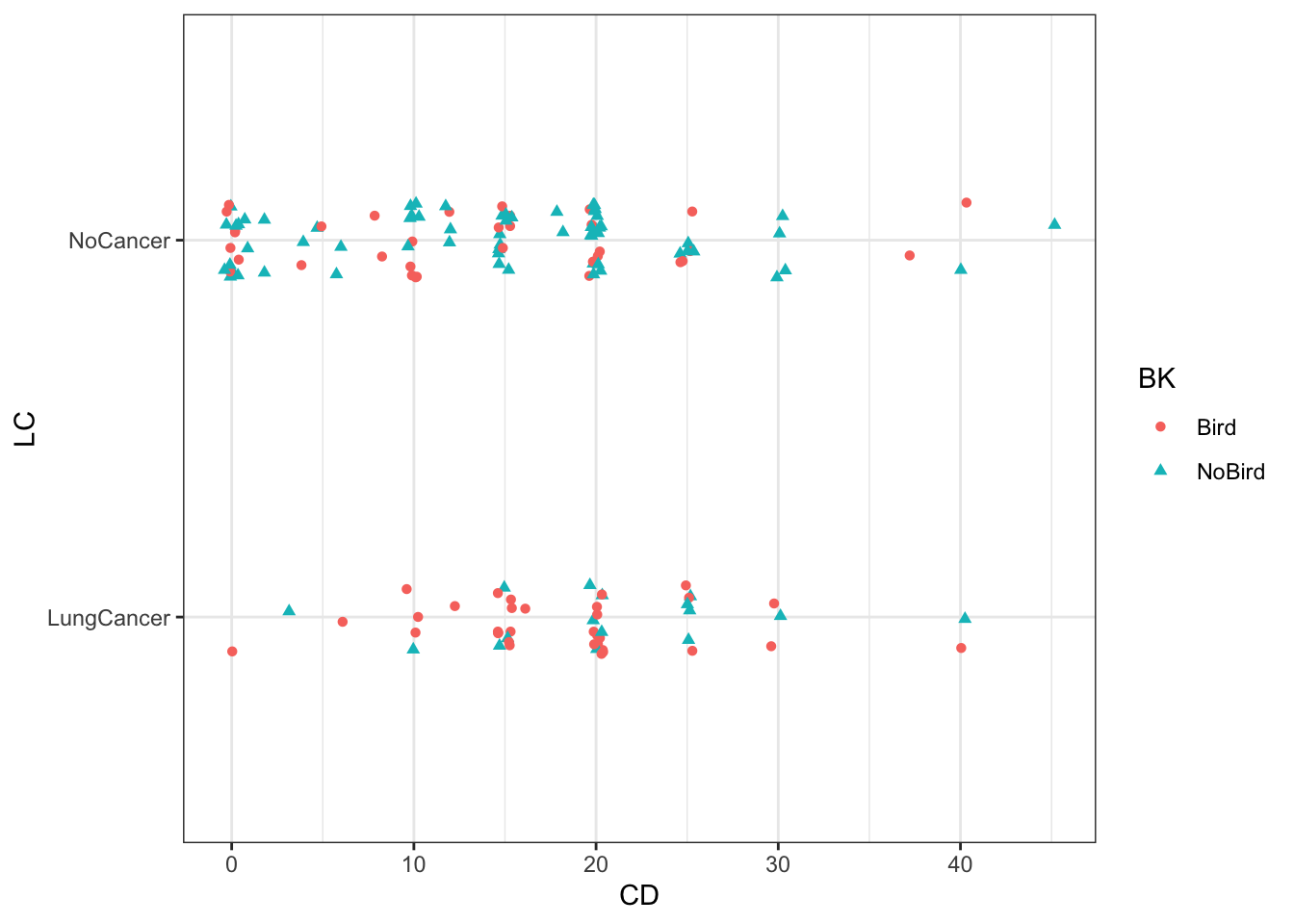
g <-ggplot(d,aes(x = CD,y = LC)) +geom_point(aes(size = n)) g
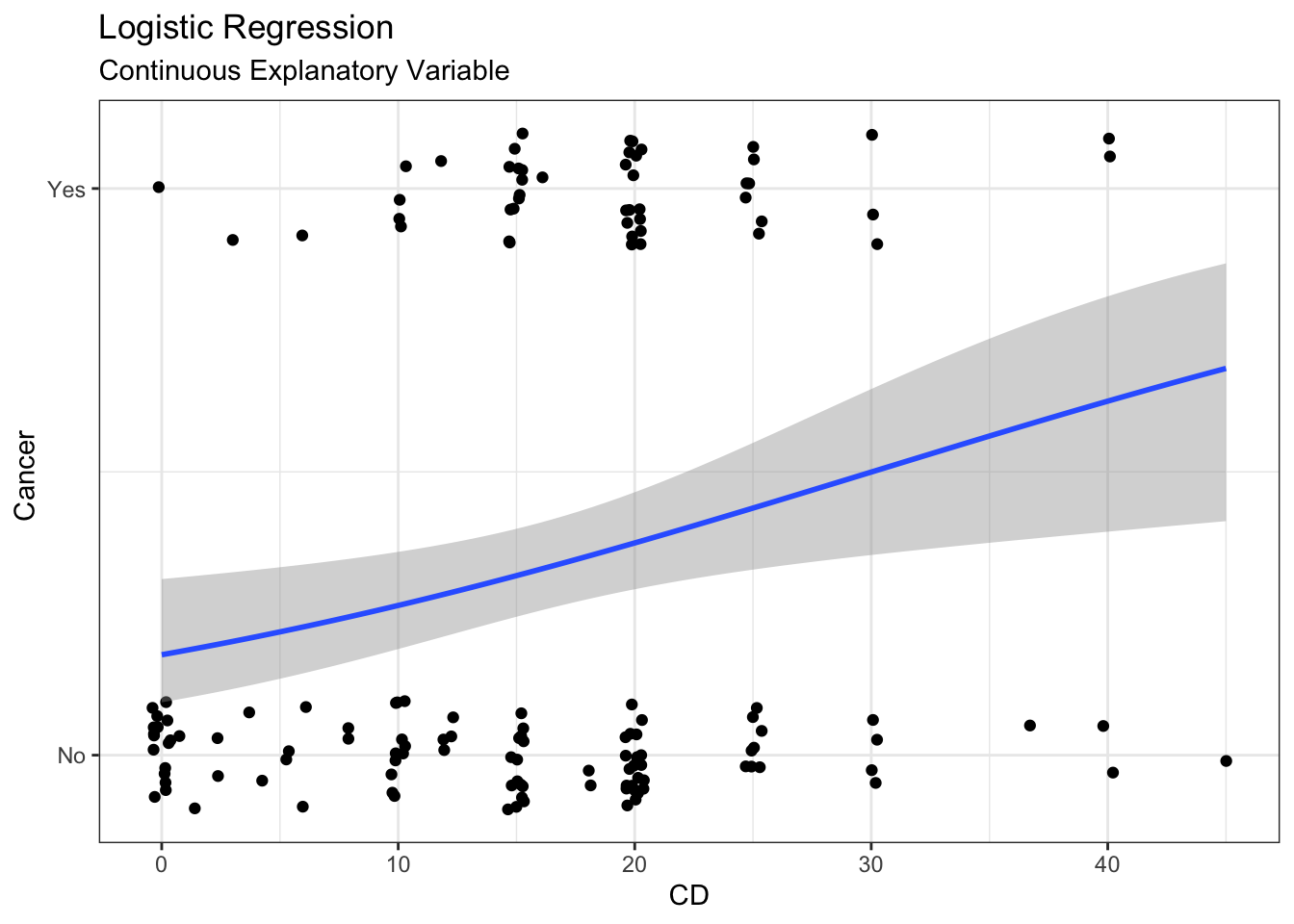
When running a logistic regression, you need to decide what success is. This choice is arbitrary, but important to how you interpret the regression. It is a good practice to be explicit about what is success by a numerical vector where 1 represents success and 0 represents failure. Here we will define having lung cancer as success.
# Fit logistic regression when response is binarym <-glm(as.numeric(LC =="LungCancer") ~ CD, data = case2002,family ="binomial")# Summarysummary(m)
Call:
glm(formula = as.numeric(LC == "LungCancer") ~ CD, family = "binomial",
data = case2002)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.53541 0.37707 -4.072 4.66e-05 ***
CD 0.05113 0.01939 2.637 0.00836 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 187.14 on 146 degrees of freedom
Residual deviance: 179.62 on 145 degrees of freedom
AIC: 183.62
Number of Fisher Scoring iterations: 4
# Coefficients m$coefficients
(Intercept) CD
-1.53541481 0.05112944
# Confidence intervalconfint(m)[2,] # multiplicative effect on log-odds
Waiting for profiling to be done...
2.5 % 97.5 %
0.01427734 0.09090450
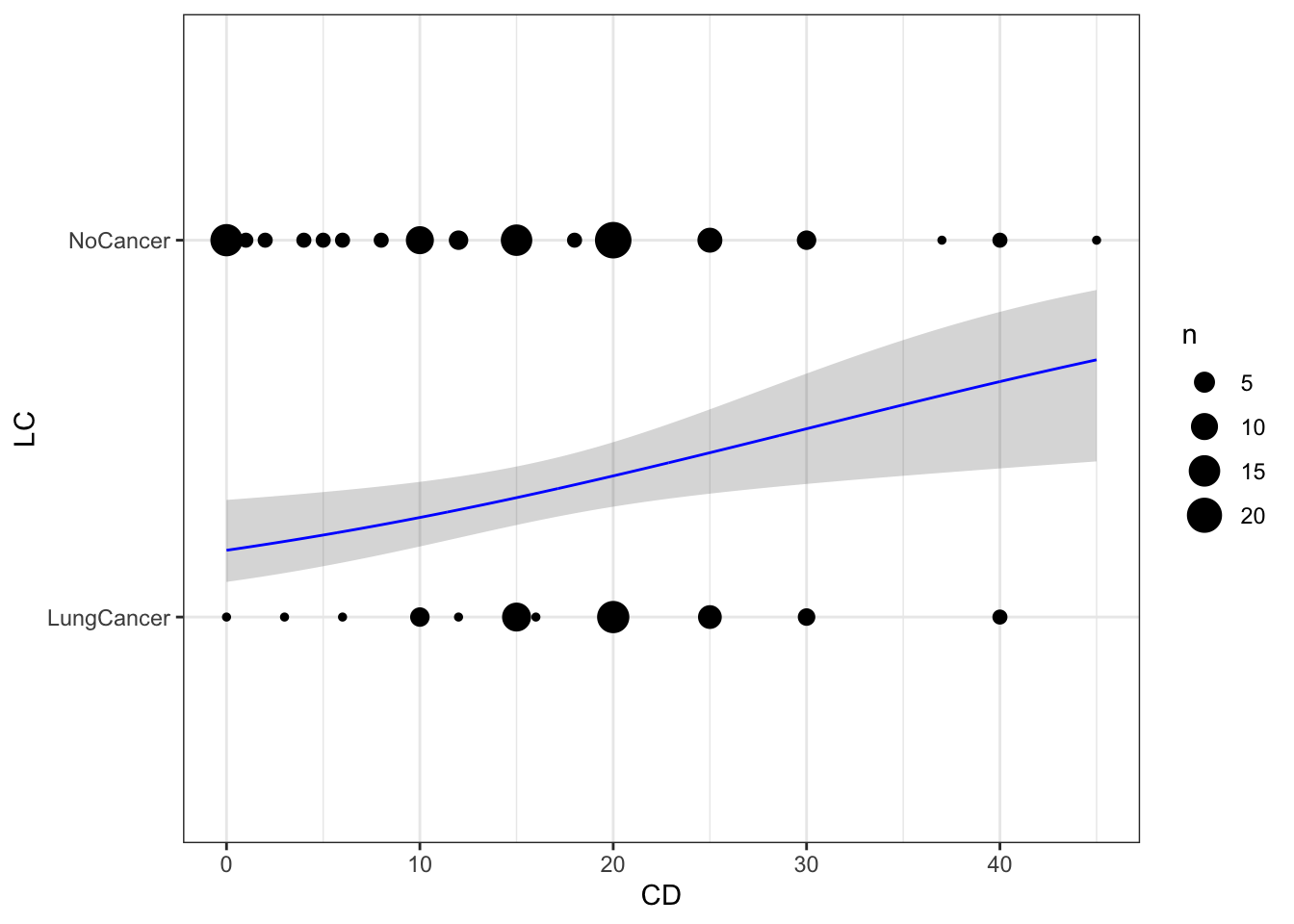
To construct
# Create new datand <-data.frame(CD =seq(from =min(case2002$CD),to =max(case2002$CD),length =1001 ))# Create predictions and combine with datap <-bind_cols( nd, predict(m, newdata = nd, se.fit =TRUE) |>as.data.frame() |># Manually construct confidence intervalsmutate(lwr = fit -qnorm(0.975) * se.fit,upr = fit +qnorm(0.975) * se.fit,# Expit to get to response scale# also + 1 so line is within two levelsLC =expit(fit) +1,lwr =expit(lwr) +1,upr =expit(upr) +1 ) )# Plotpg <- g +geom_ribbon(data = p,mapping =aes(ymin = lwr,ymax = upr ),alpha =0.2 ) +geom_line(data = p,color ="blue" ) pg
37.2.1 Grouped data
# Group datadg <- d |>pivot_wider(id_cols = CD,names_from = LC,values_from = n,values_fill =0) |># make NAs 0arrange(CD)
To fit the logistic regression with grouped data, we need a matrix where the first column is the successes and the second column is the failures.
# Fit logistic regression with grouped datam2 <-glm(cbind(NoCancer, LungCancer) ~ CD,data = dg,family ="binomial")
The two approaches will result in the same answers.
# Coefficients are the samem $coefficients
(Intercept) CD
-1.53541481 0.05112944
m2$coefficients
(Intercept) CD
1.53541481 -0.05112944
# Confindence intervals are the sameconfint(m )
Waiting for profiling to be done...
2.5 % 97.5 %
(Intercept) -2.31672589 -0.8290939
CD 0.01427734 0.0909045
confint(m2)
Waiting for profiling to be done...
2.5 % 97.5 %
(Intercept) 0.8290939 2.31672589
CD -0.0909045 -0.01427734
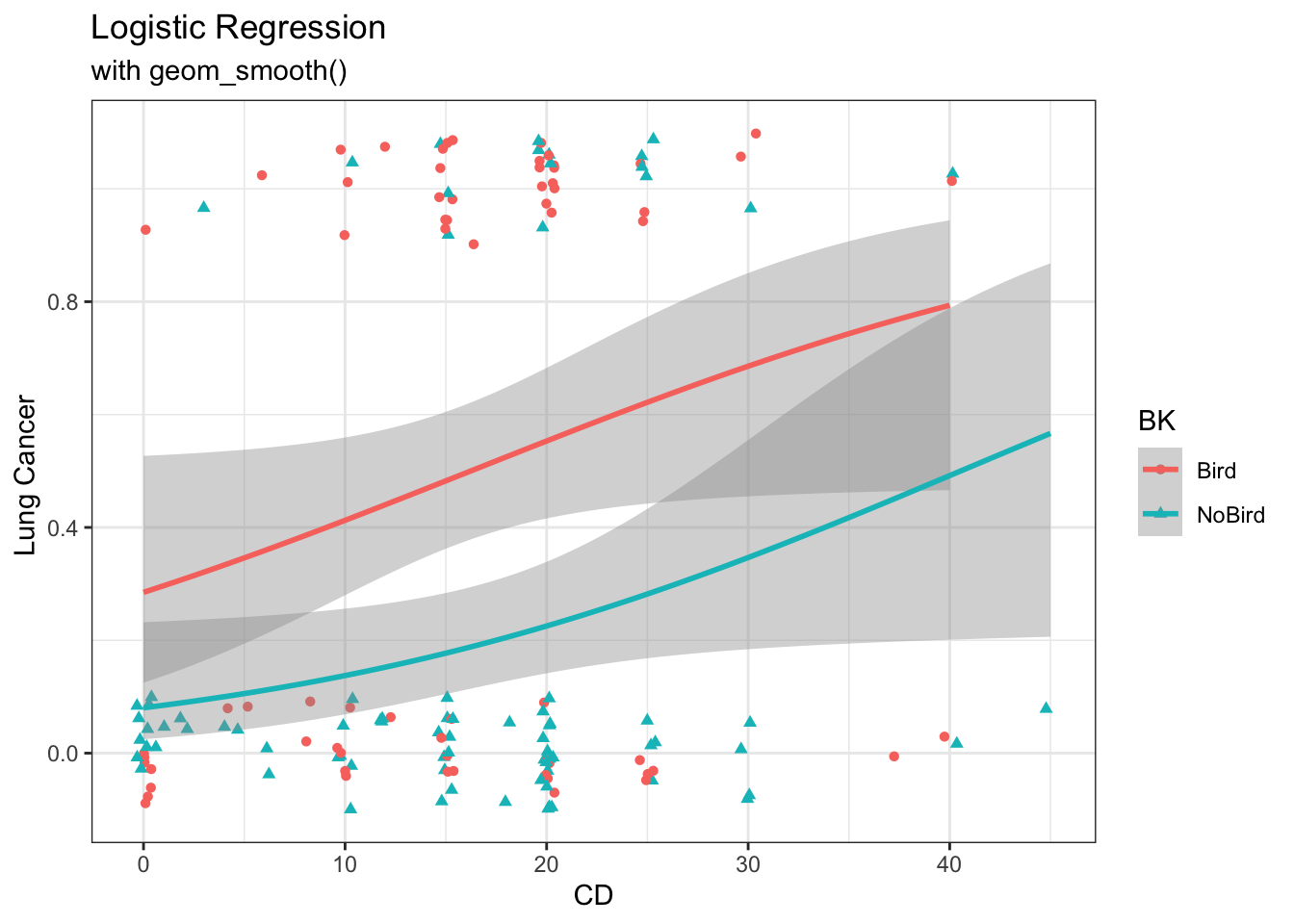
37.2.2 geom_smooth()
To use geom_smooth(), you need to construct a numeric binary variable (0-1).
Logistic regression can be used with categorical variables. Since both the explanatory variable and response variable are discrete, the data are easily represented in a table.
# A tibble: 4 × 4
BK FM n p
<fct> <fct> <int> <dbl>
1 Bird Female 22 0.45
2 Bird Male 45 0.51
3 NoBird Female 14 0.14
4 NoBird Male 66 0.21
t |>select(-n) |>pivot_wider(id_cols = BK,names_from = FM,values_from = p )
# A tibble: 2 × 3
BK Female Male
<fct> <dbl> <dbl>
1 Bird 0.45 0.51
2 NoBird 0.14 0.21
A logistic regression model works linearly on the link scale. Nonetheless, since the difference in these probabilities in either direction is approximately constant, we are not expecting the interaction to be significant.
37.4.1 Main effects
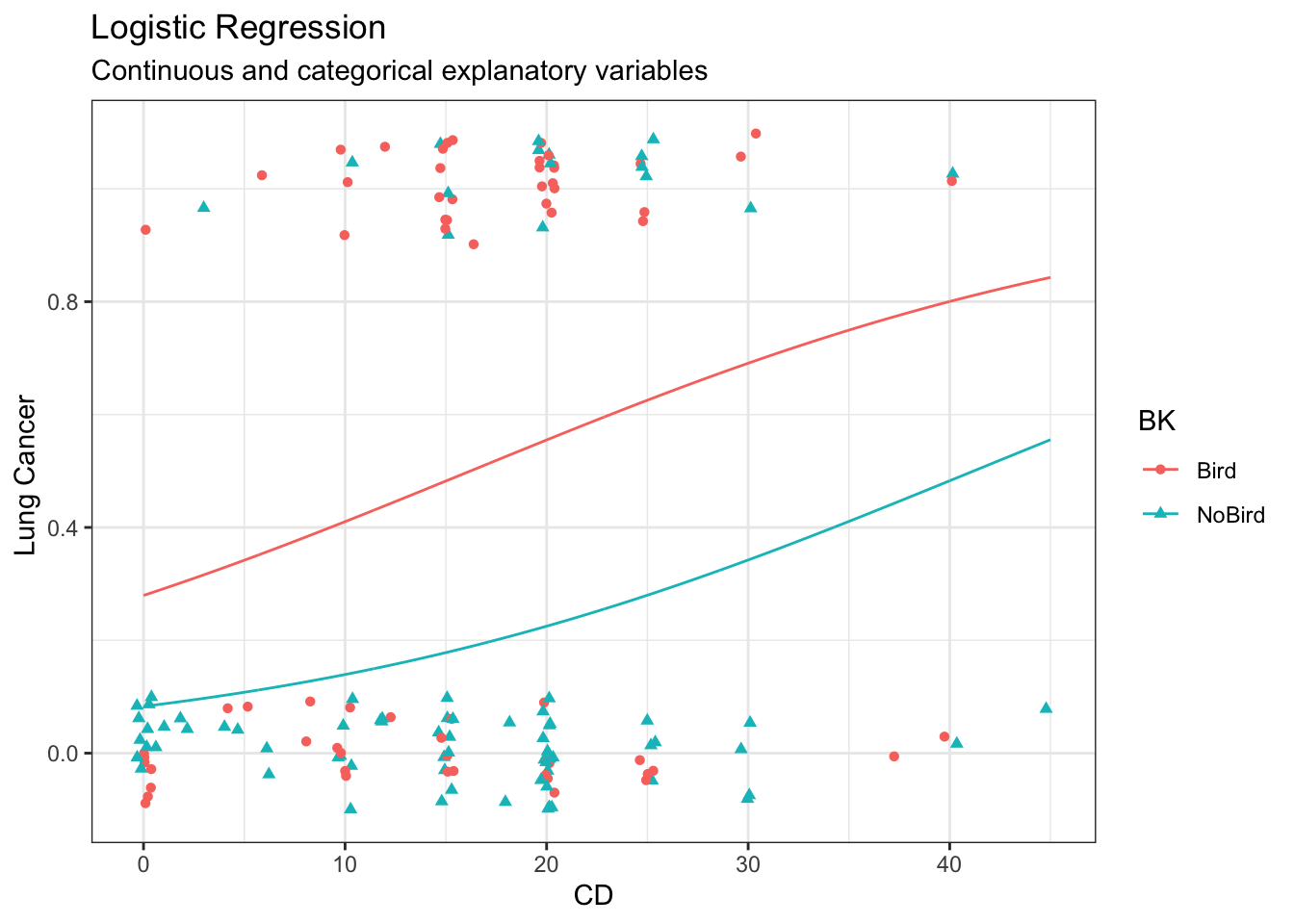
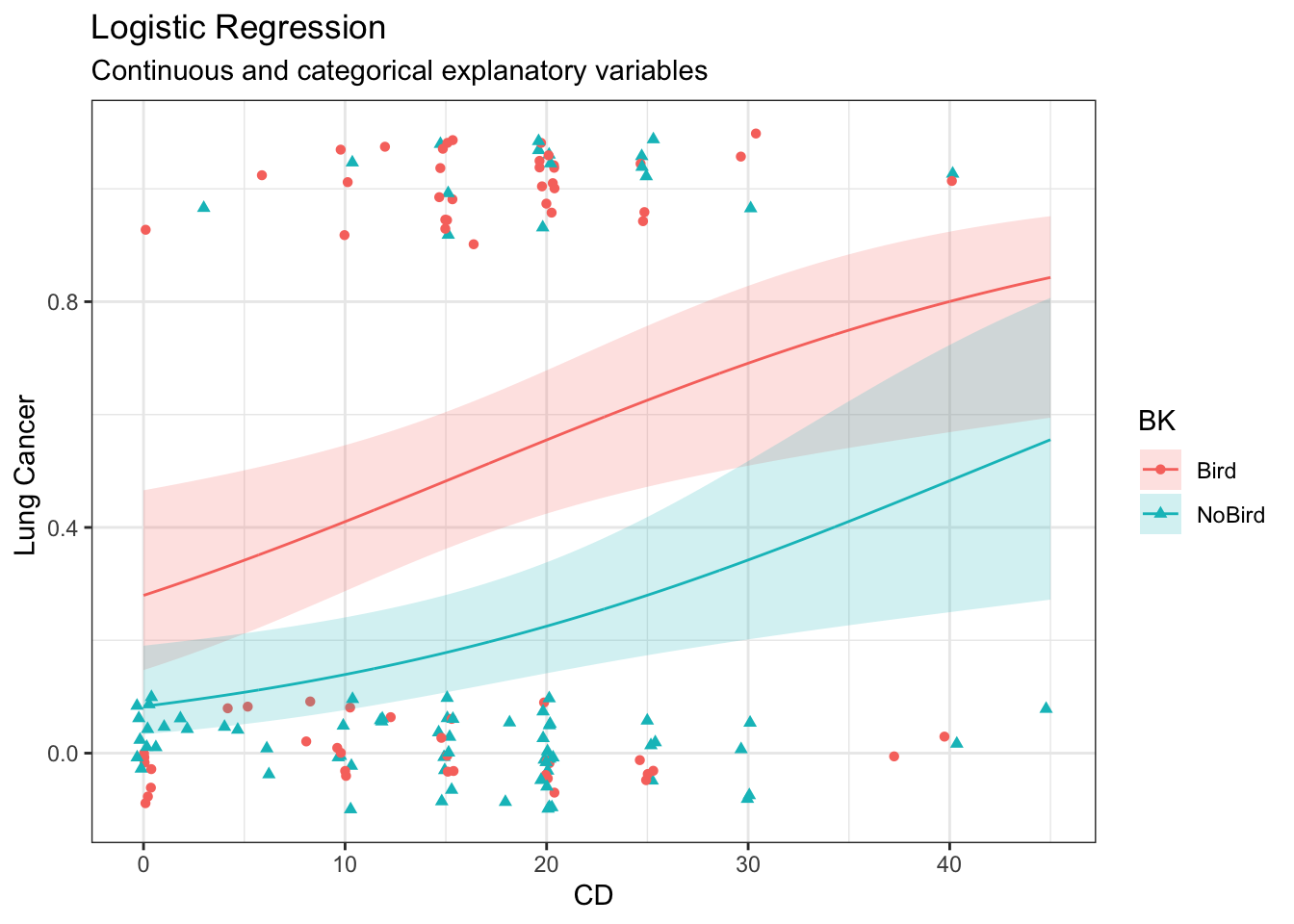
Fit main effects regression model
# Fit main effects Poisson regression modelm <-glm(as.numeric(LC =="LungCancer") ~ FM + BK,data = case2002,family ='binomial')# Model summarysummary(m)
Call:
glm(formula = as.numeric(LC == "LungCancer") ~ FM + BK, family = "binomial",
data = case2002)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.2330 0.3823 -0.610 0.542183
FMMale 0.3020 0.4352 0.694 0.487715
BKNoBird -1.4064 0.3797 -3.704 0.000212 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 187.14 on 146 degrees of freedom
Residual deviance: 172.44 on 144 degrees of freedom
AIC: 178.44
Number of Fisher Scoring iterations: 4
# Confidence intervalsexp(confint(m)[2:3,]) # multiplicative effect on log-odds
# A tibble: 2 × 3
BK Male Female
<fct> <chr> <chr>
1 Bird 0.52 (0.38, 0.65) 0.44 (0.27, 0.63)
2 NoBird 0.21 (0.13, 0.32) 0.16 (0.07, 0.33)
37.4.2 Interaction
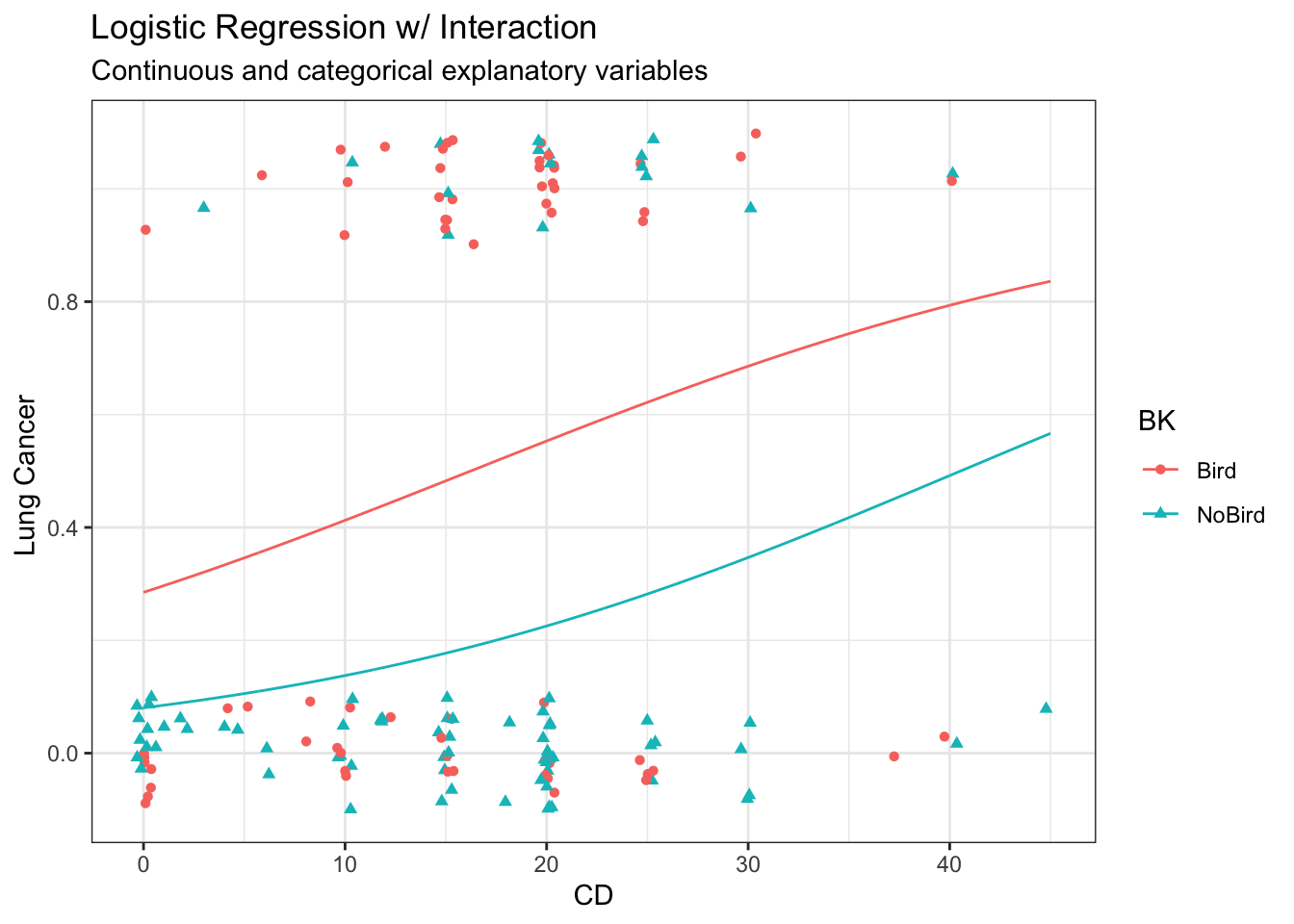
Fit interaction regression model
# Fit main effects Poisson regression modelm <-glm(as.numeric(LC =="LungCancer") ~ FM * BK,data = case2002,family ='binomial')# Model summarysummary(m)
Call:
glm(formula = as.numeric(LC == "LungCancer") ~ FM * BK, family = "binomial",
data = case2002)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.1823 0.4282 -0.426 0.670
FMMale 0.2268 0.5218 0.435 0.664
BKNoBird -1.6094 0.8756 -1.838 0.066 .
FMMale:BKNoBird 0.2528 0.9728 0.260 0.795
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 187.14 on 146 degrees of freedom
Residual deviance: 172.37 on 143 degrees of freedom
AIC: 180.37
Number of Fisher Scoring iterations: 4
Calculate predictions
# Predictp <-bind_cols( nd,predict(m,newdata = nd,se.fit =TRUE)|>as.data.frame() |># Manually construct confidence intervalsmutate(lwr = fit -qnorm(0.975) * se.fit,upr = fit +qnorm(0.975) * se.fit,# Expit to get to response scaleLungCancer =expit(fit),lwr =expit(lwr),upr =expit(upr) ) )p
BK FM fit se.fit residual.scale lwr upr
1 Bird Male 0.04445176 0.2982160 1 0.36817806 0.6522501
3 NoBird Male -1.31218639 0.3010968 1 0.12984553 0.3269422
38 Bird Female -0.18232156 0.4281744 1 0.26472987 0.6585603
48 NoBird Female -1.79175947 0.7637625 1 0.03596066 0.4268261
LungCancer
1 0.5111111
3 0.2121212
38 0.4545455
48 0.1428571
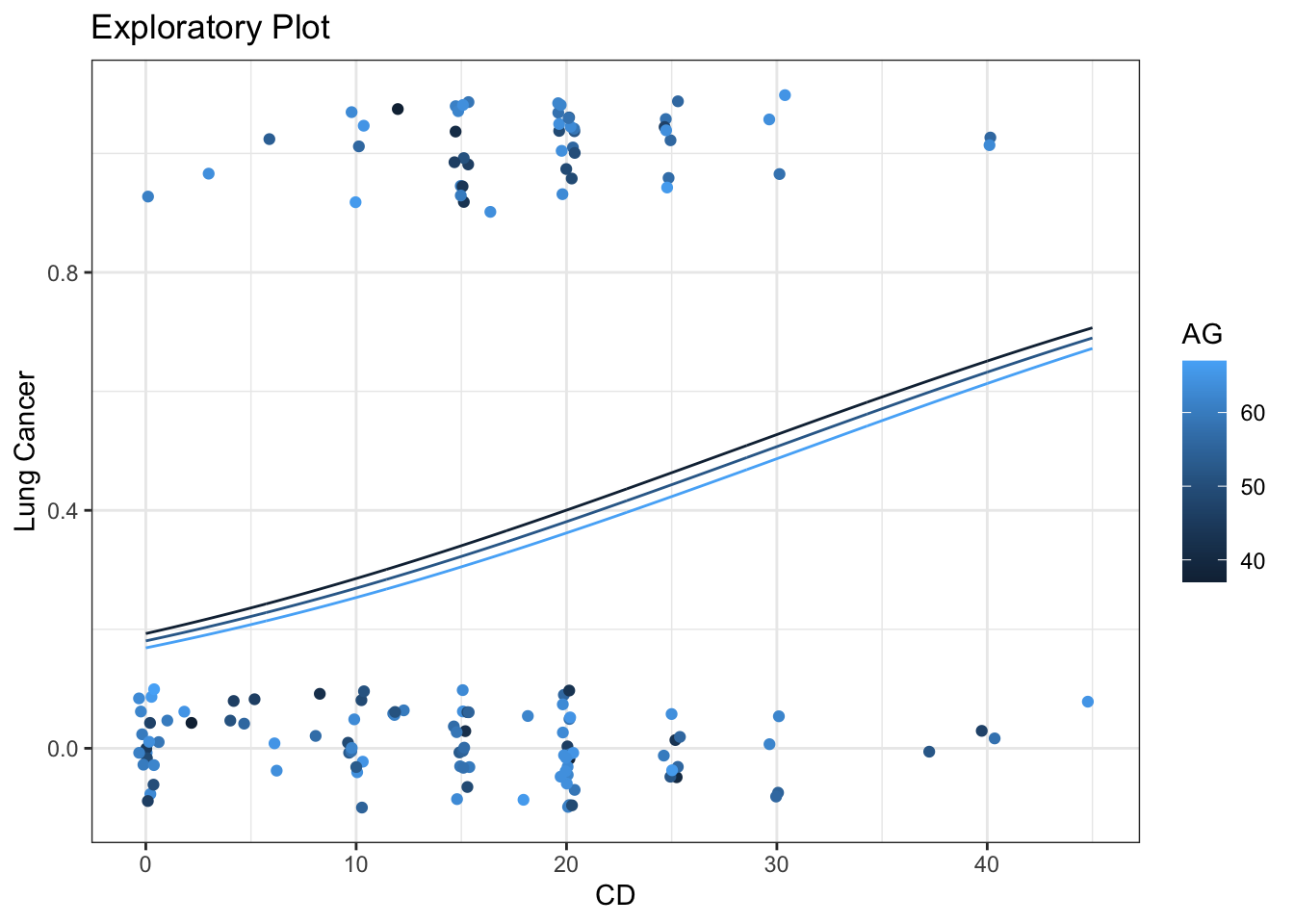
# Main effects modelm <-glm(as.numeric(LC =="LungCancer") ~ AG + CD,data = case2002,family ='binomial')# Summarysummary(m)
Call:
glm(formula = as.numeric(LC == "LungCancer") ~ AG + CD, family = "binomial",
data = case2002)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.231131 1.432219 -0.860 0.39001
AG -0.005417 0.024644 -0.220 0.82602
CD 0.051375 0.019439 2.643 0.00822 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 187.14 on 146 degrees of freedom
Residual deviance: 179.58 on 144 degrees of freedom
AIC: 185.58
Number of Fisher Scoring iterations: 4
# Confidence intervalsexp(confint(m)[2:3,]) # CI for multiplicative effect on log-odds
Waiting for profiling to be done...
2.5 % 97.5 %
AG 0.9479733 1.044842
CD 1.0145456 1.095567
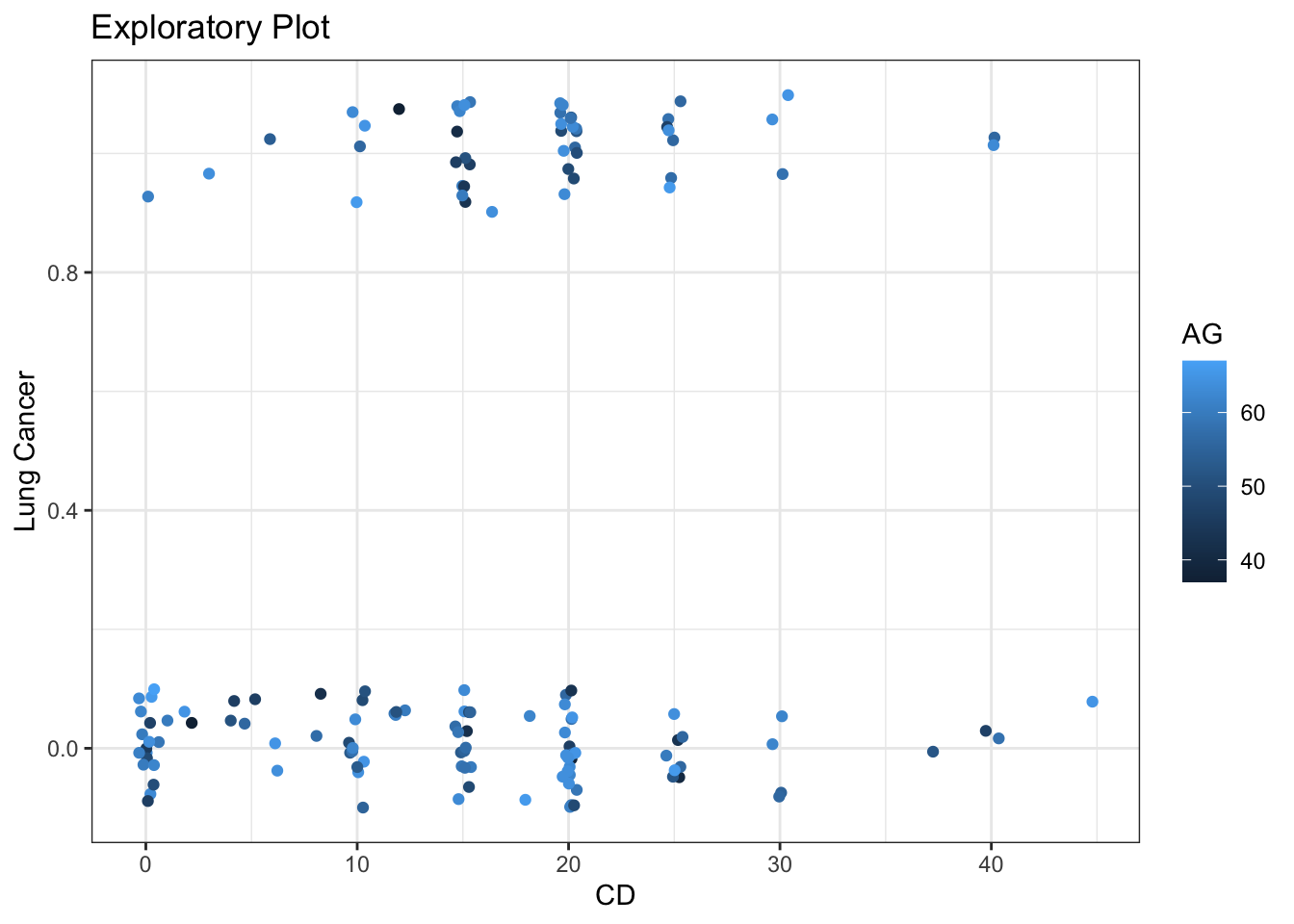
When both explanatory variables are continuous, select certain value of the non-x-axis variable to make lines for.
# Create prediction data framend <-expand.grid(AG =seq(from =min(case2002$AG),to =max(case2002$A),length =3),CD =seq(from =min(case2002$CD),to =max(case2002$CD),length =1001))# Predictionsp <-bind_cols( nd,predict(m,newdata = nd,se.fit =TRUE)|>as.data.frame() |># Manually construct confidence intervalsmutate(lwr = fit -qnorm(0.975) * se.fit,upr = fit +qnorm(0.975) * se.fit,# Exponentiate to get to response scaleLungCancer =expit(fit),lwr =expit(lwr),upr =expit(upr) ) )
Plot model predictions
# Plot predictionspg <- g +geom_line(data = p,mapping =aes(y = LungCancer,group = AG ))pg
37.6.2 Interaction
Fit regression model
# Main effects modelm <-glm(as.numeric(LC =="LungCancer") ~ AG * CD,data = case2002,family ='binomial')# Summarysummary(m)
Call:
glm(formula = as.numeric(LC == "LungCancer") ~ AG * CD, family = "binomial",
data = case2002)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.1089538 2.8645620 -0.387 0.699
AG -0.0075523 0.0498961 -0.151 0.880
CD 0.0436350 0.1585242 0.275 0.783
AG:CD 0.0001347 0.0027396 0.049 0.961
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 187.14 on 146 degrees of freedom
Residual deviance: 179.57 on 143 degrees of freedom
AIC: 187.57
Number of Fisher Scoring iterations: 4