── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
You have a learned a number of formulas for confidence intervals. These intervals are constructed to contain the truth a certain proportion of the time, e.g. a 100(1-\(\alpha\))% interval is constructed to contain the truth parameter 100(1-\(\alpha\))% of the time.
These intervals are either exact or asymptotic. An exact interval, as the name suggests, is constructed so that the claim of “containing the true value of the parameter” is always true. The claim is still probabilistic, i.e. we expect 100(1-\(\alpha\))% of the intervals to contain the truth. Thus, we won’t always see that percentage in any given sample. An asymptotic (sometimes referred to as an approximate) interval, is constructed so the claim is true as the size of the sample goes to infinity.
30.1 Examples
Introductory statistics courses, typically teach the following confidence interval formulas.
30.1.1 Normal
Let \(Y_i\stackrel{ind}{\sim} N(\mu,\sigma^2)\) with \(\sigma\) known. A exact 100(1-\(\alpha\))% confidence interval for \(\mu\) is \[
\overline{y} \pm z_{1-\alpha/2} \sigma / \sqrt{n}
\] where
\(n\) is the sample size,
\(\overline{y}\) is the sample mean, and
\(z_{1-\alpha/2}\) is the z critical value such that \(1-\alpha/2 = P(Z < z_{1-\alpha/2})\) where \(Z\) is a standard normal.
Note: The variance is known here and thus you can use a z critical value.
Let \(Y_i\stackrel{ind}{\sim} N(\mu,\sigma^2)\) with \(\mu\) and \(\sigma^2\) both unknown. A exact 100(1-\(\alpha\))% confidence interval for \(\mu\) is \[
\overline{y} \pm t_{n-1,1-\alpha/2} s / \sqrt{n}
\] where
\(n\) is the sample size,
\(\overline{y}\) is the sample mean,
\(s\) is the sample standard deviation, and
\(t_{n-1,1-\alpha/2}\) is the t critical value such that \(1-\alpha/2 = P(T_{n-1} < t_{n-1,1-\alpha/2})\) where \(T_{n-1}\) is a student \(T\) distribution with \(n-1\) degrees of freedom.
For example,
# Calculate statistics (using data above)s <-sd(y)t <-qt(1-alpha/2, df = n-1)# Construct intervalybar +c(-1,1) * t * s /sqrt(n)
[1] -0.4380182 0.9150336
As \(n\to\infty\), \(t_{n-1,1-\alpha/2} \to z_{1-\alpha/2}\) and \(s^2 \to \sigma^2\). (That is, \(s^2\) is a consistent estimator for \(\sigma^2\).) Thus, for large sample sizes, an asymptotic 100(1-\(\alpha\))% confidence interval for \(\mu\) is \[
\overline{y} \pm z_{1-\alpha/2} s / \sqrt{n}
\] where we have replaced the t critical value with a z critical value.
For example
# Construct asymptotic intervalybar +c(-1,1) * z * s /sqrt(n) # n is only 10
[1] -0.3476437 0.8246591
Note: The t interval is an exact confidence interval while this interval is an asymptotic confidence interval.
30.1.2 Binomial
Let \(X\sim Bin(n,p)\).
30.1.2.1 Wald interval
An approximate 100(1-\(\alpha\))% confidence interval for \(p\) is \[
\hat{p} \pm z_{1-\alpha/2} \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}
\] where \(\hat{p} = x/n\).
This is an approximate confidence interval because it is constructed based on the Central Limit Theorem (CLT) which states that, for large enough sample size, \[
\hat{p} \stackrel{\cdot}{\sim} N\left( p, \frac{\hat{p}(1-\hat{p})}{n} \right).
\]
This interval is based on the Clopper-Pearson interval. This interval finds all the values for theta that do not reject a hypothesis test (when those values are set as the null value) and constructing the interval based on those values. These confidence intervals are exact, but these intervals are often quite wide
30.1.2.3 prop.test()
Here are some alternative approximate confidence intervals in the sense that they more often contain the truth compared to the Wald interval and they are typically shorter than the Clopper-Pearson interval
Our goal here will be to estimate the coverage of these interval estimators. Coverage is the true probability of an interval containing the truth for repeated realizations of the data (when the model is true).
A Monte Carlo study to estimate coverage proceeds by repeating the following
simulate data,
construct an interval, and
determine whether that interval contains the truth.
The proportion of times the interval contains the truth is an estimate of its coverage and we can find the Monte Carlo standard error of that estimate by using the formula we have seen before.
# Function to calculate Monte Carlo proportion with standard errormc_probability <-function(x) { p <-mean(x)return(c(prop = p,se =sqrt(p*(1-p)/length(x))) )}
30.2.1 Normal
For a normal distribution, the intervals for a normal mean are exact and both have coverage equal to the nominal level 100(1-\(\alpha\))%.
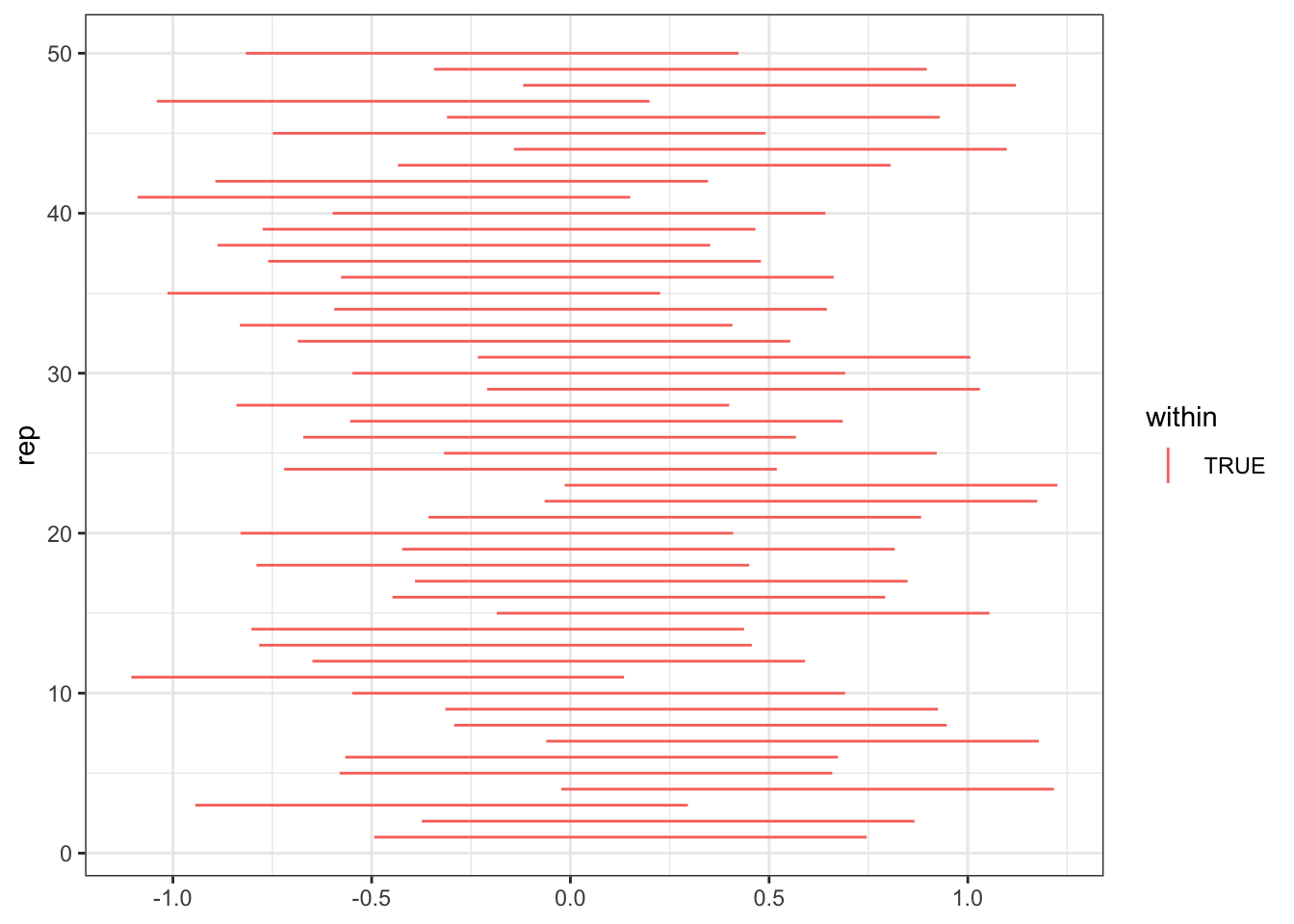
# Pick error ratealpha <-0.05z <-qnorm(1-alpha/2)# Pick normal parametersn <-10# data sample size for each replicatemu <-0sigma <-1# Conduct Monte Carlo studyd <-expand.grid(rep =1:1e3, # number of Monte Carlo replicatesn =1:n) |># For each repgroup_by(rep) |># Simulate datamutate(y =rnorm(n(), mean = mu, sd = sigma) ) |># Construct CIsummarize(n =n(),ybar =mean(y),se = sigma /sqrt(n),lcl = ybar - z * se,ucl = ybar + z * se,.groups ="drop" ) |># Determine if true value is within intervalmutate(within = lcl < mu & mu < ucl ) # Visualize ggplot(d |>filter(rep <=50), aes(x = rep, ymin = lcl, ymax = ucl, color = within)) +geom_linerange() +coord_flip()
This figure visualizes the first 50 confidence intervals constructed in our simulation. We are only visualizing the first 50 because it is hard to visualize 1,000 intervals simultaneously. Some of the intervals will contain the truth (within = TRUE) and some will not (within = FALSE). On overage, intervals constructed using this procedure will contain the truth 100(1-\(\alpha\))% of the time.
Now we can calculate our Monte Carlo estimate of the coverage with its uncertainty.
# MC estimate of coveraged |>pull(within) |>mc_probability()
prop se
0.956000000 0.006485677
The situation is very similar when the variance is unknown. The two main changes are that the interval uses 1) a t critical value and 2) the sample standard deviation.
# Normal unknown variancet <-qt(1-alpha/2, df = n-1)expand.grid(rep =1:1e3,n =1:n) |># Simulate datagroup_by(rep) |>mutate(y =rnorm(n(), mean = mu, sd = sigma) ) |># Construct confidence intervalssummarize(n =n(),ybar =mean(y),se =sd(y) /sqrt(n),lcl = ybar - t * se,ucl = ybar + t * se,.groups ="drop" ) |># Determine if truth is within the intervalmutate(within = lcl < mu & mu < ucl ) |># MC estimate of coveragepull(within) |>mc_probability()
prop se
0.953000000 0.006692608
Recall that if we replace the t critical value in the previous formula with a z critical value, we have an asymptotic interval. The coverage of this interval will depend on the data sample size. As this sample size increases, the coverage will converge to 100(1-\(\alpha\))%.
# Pick erroralpha <-0.05z <--qnorm(alpha/2)# Pick nn <-10# don't make it too big or the results will be boringexpand.grid(rep =1:1e3,n =1:n) |># Simulate datagroup_by(rep) |>mutate(y =rnorm(n(), mean = mu, sd = sigma) ) |># Construct CIssummarize(n =n(),ybar =mean(y),se =sd(y) /sqrt(n), lcl = ybar - z * se, # using z hereucl = ybar + z * se,.groups ="drop" ) |># Determine if true value is within intervalmutate(within = lcl < mu & mu < ucl ) |># MC estimate of coveragepull(within) |>mc_probability()
prop se
0.918000000 0.008676174
30.2.2 Binomial
For the binomial distribution, we have a number of different intervals and we can estimate the coverage of all of these intervals. When comparing different statistical methods, it is best to use the same data.
# Pick thesealpha <-0.05n <-10p <-0.78# z critical valuez <--qnorm(alpha/2)# Simulate datad <-data.frame(x =rbinom(1e3, # Monte Carlo sample sizesize = n, prob = p)) # Construct CIsci <- d |>rowwise() |>mutate(# Wald intervalp_hat = x/n,lcl = p_hat - z *sqrt(p_hat*(1-p_hat)/n),ucl = p_hat + z *sqrt(p_hat*(1-p_hat)/n),Wald = lcl < p & p < ucl,# Clopper-Pearsonlcl =binom.test(x, n)$conf.int[1],ucl =binom.test(x, n)$conf.int[2],`Clopper-Pearson`= lcl < p & p < ucl,# Wilson's score intervallcl =prop.test(x, n, correct =FALSE)$conf.int[1],ucl =prop.test(x, n, correct =FALSE)$conf.int[2],`Wilson score interval`= lcl < p & p < ucl,# Wilson's score interval with continuity correctionlcl =prop.test(x, n, correct =TRUE)$conf.int[1],ucl =prop.test(x, n, correct =TRUE)$conf.int[2],`Wilson score interval (with CC)`= lcl < p & p < ucl, ) |>select(Wald:`Wilson score interval (with CC)`)# MC estimate of coveragemcp <- ci |>pivot_longer(everything(),names_to ="method", values_to ="within") |>group_by(method) |>summarize(coverage =mean(within),se =sqrt(p*(1-p)/n()) )mcp
# A tibble: 4 × 3
method coverage se
<chr> <dbl> <dbl>
1 Clopper-Pearson 0.995 0.0131
2 Wald 0.906 0.0131
3 Wilson score interval 0.949 0.0131
4 Wilson score interval (with CC) 0.949 0.0131