In this chapter, we will discuss the basics of wide versus long dimensions of data and the use of pivot_longer() and pivot_wider() to move between these two different dimensions.
library("tidyverse")
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
theme_set(theme_bw())
21.1 Wide vs Long
Multiple ways exist to store the same data. We use the terms wide and long to compare the the number of rows and columns in the data. Wide data will have more columns and fewer rows than a long version of the same data.
Generally, we store data in a wide format because it is efficient in terms of how much space it will take up. For constructing graphics or performing statistical analysis, we need the data in a long format.
Thus, it is helpful to be able to convert back and forth from wide to long format.
21.1.1 Wide
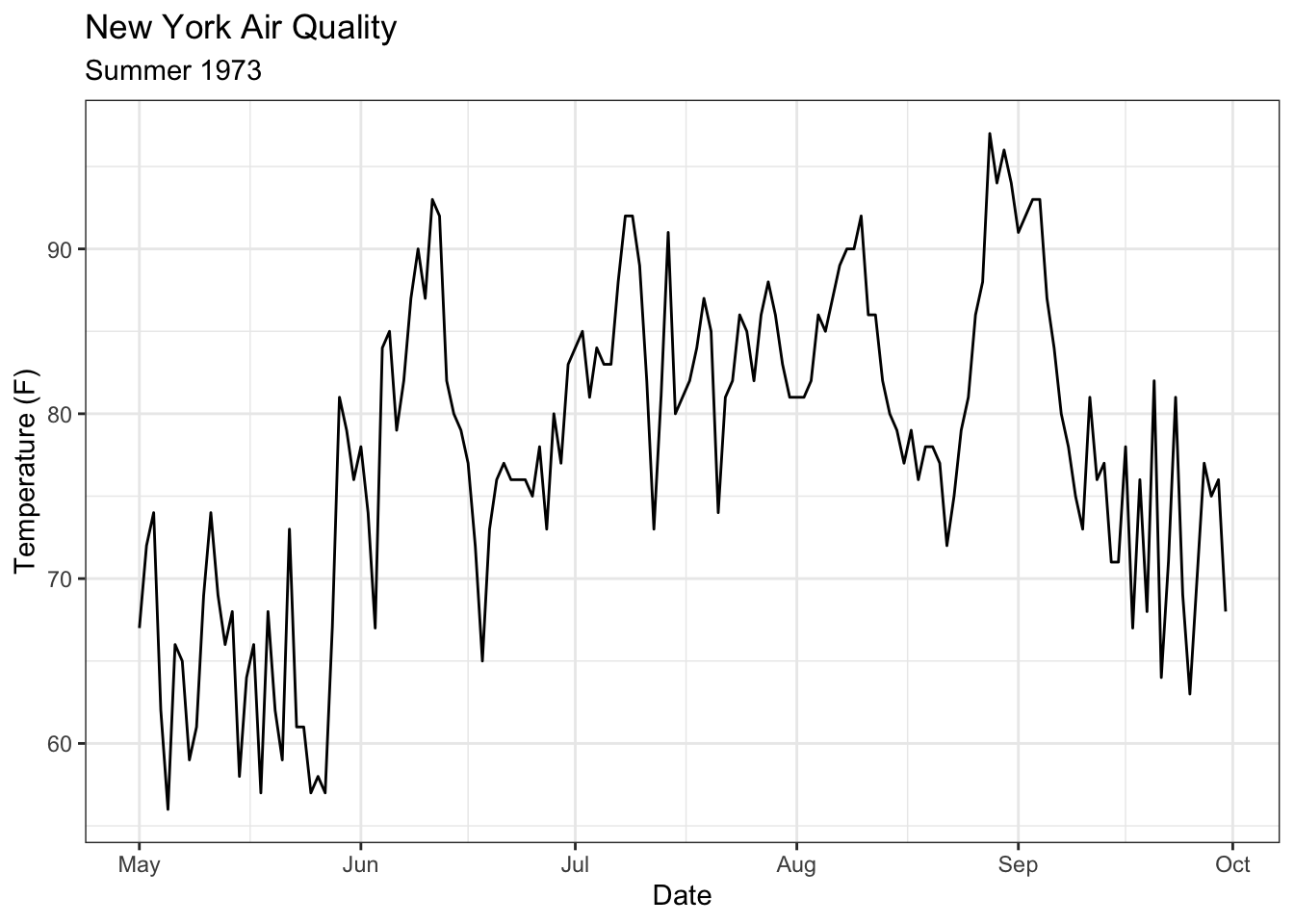
The airquality data set is stored in R as a wide data frame with rows and columns. Each row represents a single day and that row contains the measurements for ozone, solar radiation, wind, and temperature.
This organization is convenient if we want to plot a single variable.
# Create date variable d <- airquality |>mutate(Date =as.Date(paste("1973", Month, Day,sep ="-")) ) |>select(-Month, -Day) # remove Month and Day variablesggplot(d, aes(x = Date,y = Temp)) +geom_line() +labs(title ="New York Air Quality",subtitle ="Summer 1973",y ="Temperature (F)" )
If we wanted to construct a plot with each of the variables on it, we would need to have 4 separate geom_line() lines. An alternative is to convert the data into a long format.
21.1.2 Long
A long format contains more rows and fewer columns than the equivalent data in a wide format.
# Create a long version of the airquality data (with Date)d_long <- d |># we'll discuss this function laterpivot_longer(Ozone:Temp,names_to ="Measurement",values_to ="value") dim(d_long)
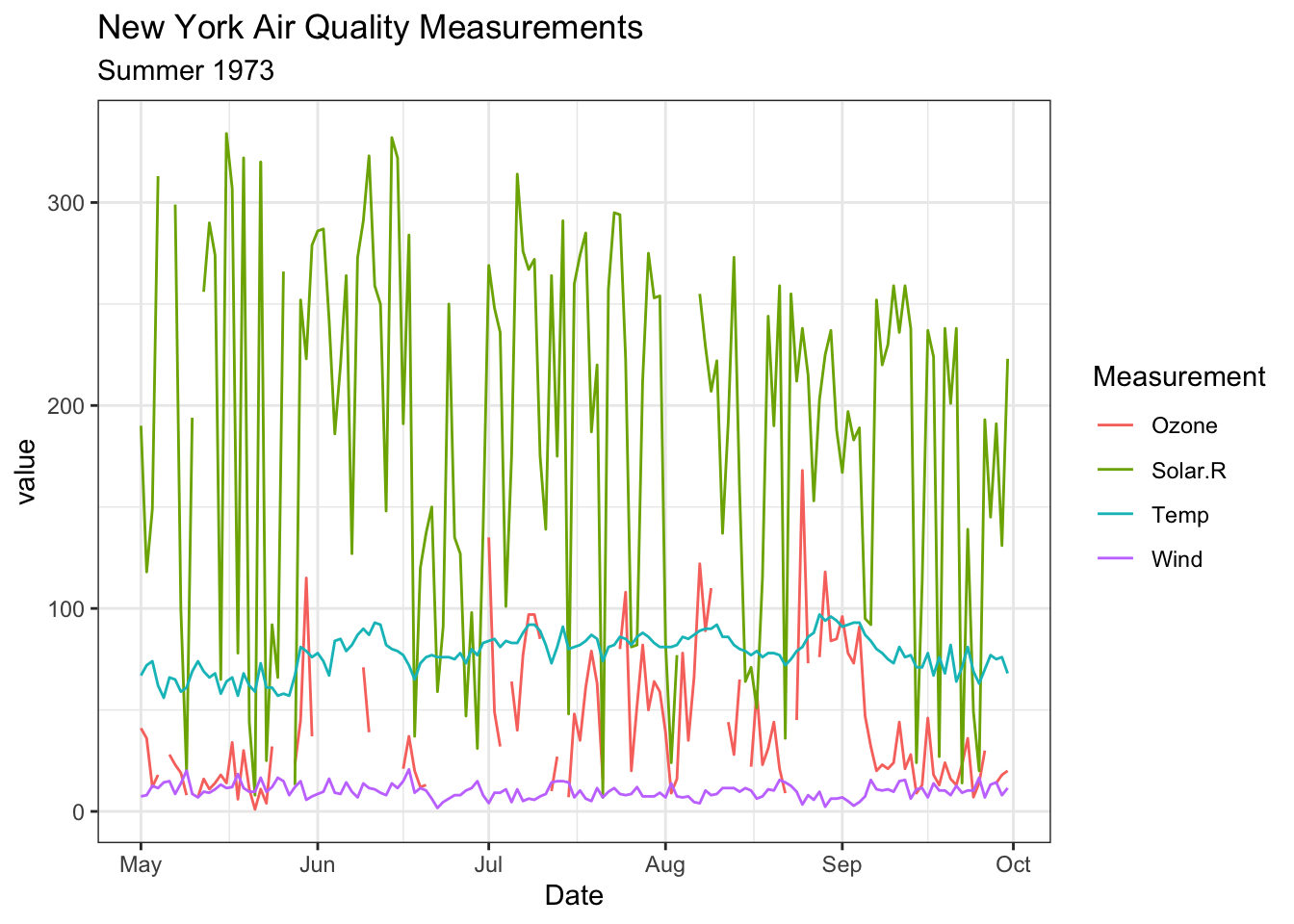
Now we can use this long (and tidy) data for constructing graphics.
# Multiple geom_long()ggplot(d_long,aes(x = Date,y = value,color = Measurement )) +geom_line() +labs(title ="New York Air Quality Measurements",subtitle ="Summer 1973" )
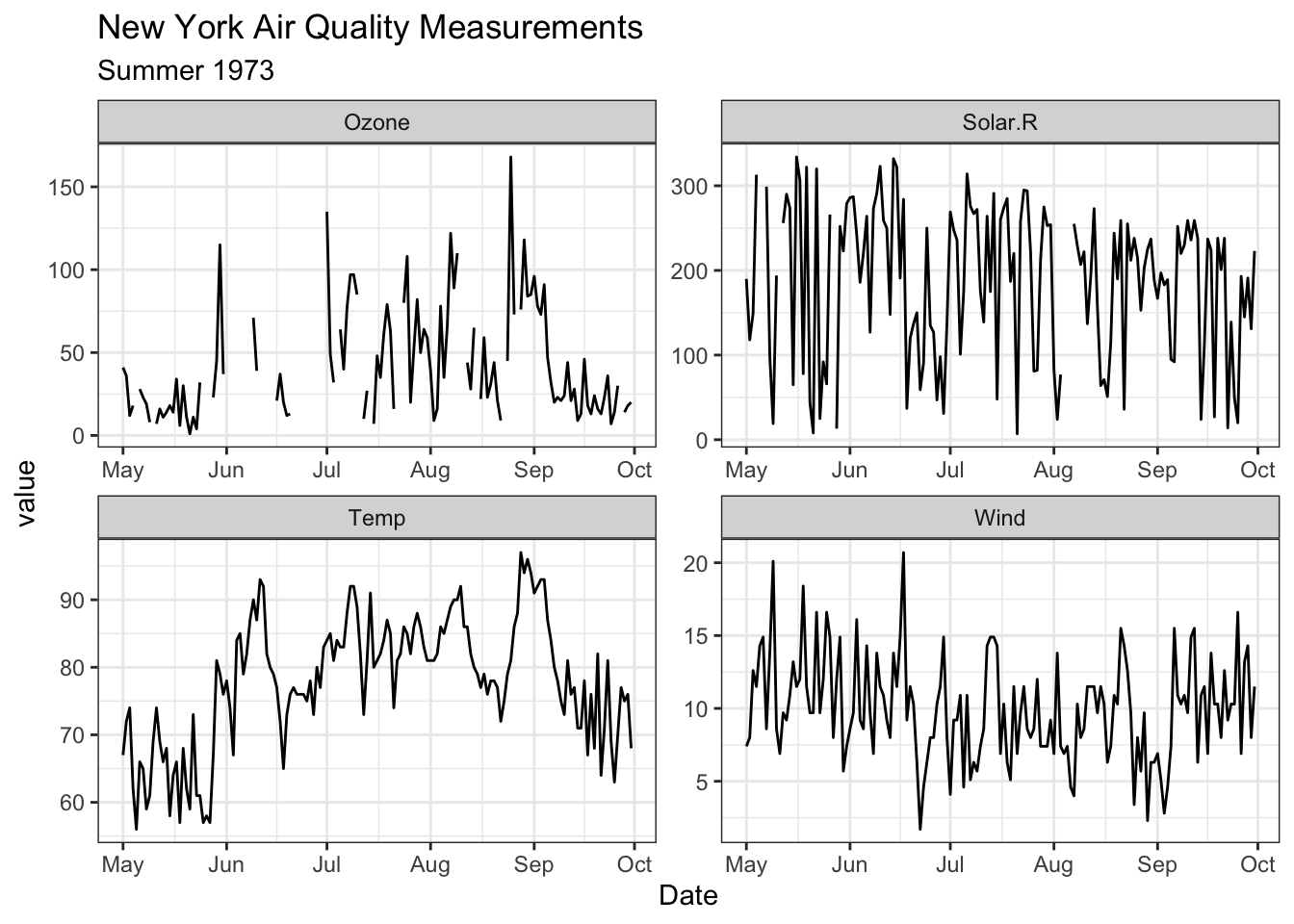
# Using facetsggplot(d_long,aes(x = Date,y = value )) +geom_line() +facet_wrap(~ Measurement, scales ="free") +labs(title ="New York Air Quality Measurements",subtitle ="Summer 1973" )
21.2 Pivot longer
When converting from a wide to a long data frame, we will use the pivot_longer() function. To pivot longer, we will need to tell the function what columns we want to pivot, what the variable name will be called that contains the former variable names, and what the variable name will be that contains the former values.
# Create a long version of the airquality data (with Date)d_long <- d |>pivot_longer( Ozone:Temp, # choose columns to pivot (same syntax as select)names_to ="Measurement", # former variable names are in this new variablevalues_to ="value") # former values are in this new variablehead(d_long)
To determine what variables will be pivoted, we can use the same syntax we use when selecting columns.
# Create a long version of the airquality data (with Date)d |>pivot_longer(-Date, # pivot all variables except Datenames_to ="Measurement", # former variable names are in this new variablevalues_to ="value") |># former values are in this new variablehead()
If your data are in a long format, but you need it in a wide format (perhaps for saving the data to a file) you can use the pivot_wider() function. Now, you will need to tell the function what variable you want to be the new columns names and what variable you want to be the new values. You also need to tell the function what columns you want to be pivoted.
Many times the way data are stored is not the way we need them to be organized to construct graphics, perform analyses, or joining the data sets to other data sets.