── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library("Sleuth3")library("ggResidpanel")
Poisson regression can be used when your response variable is a count with no clear maximum. Similar to regression, explanatory variables can be continuous, categorical, or both. Here we will consider models up to two explanatory variables.
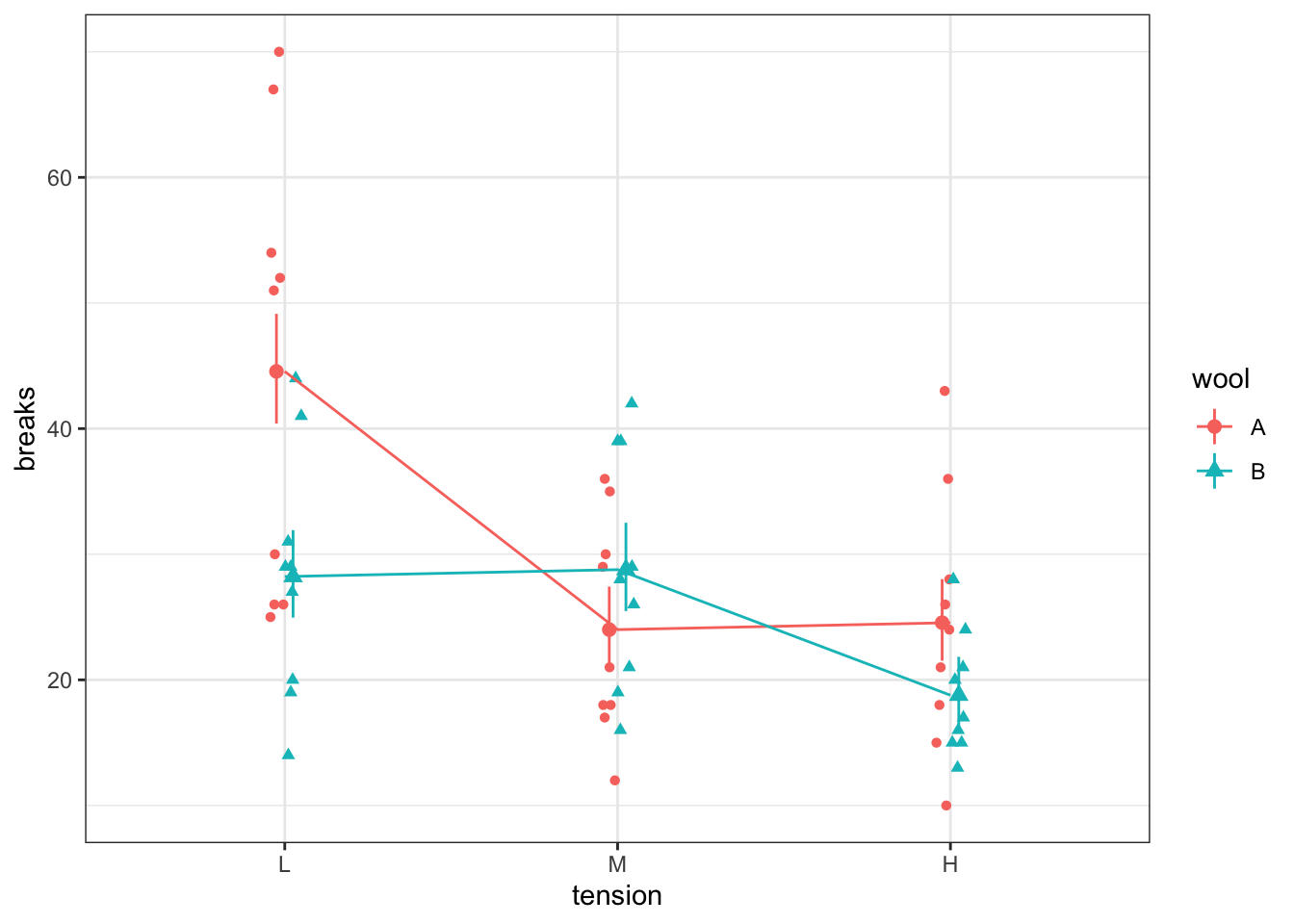
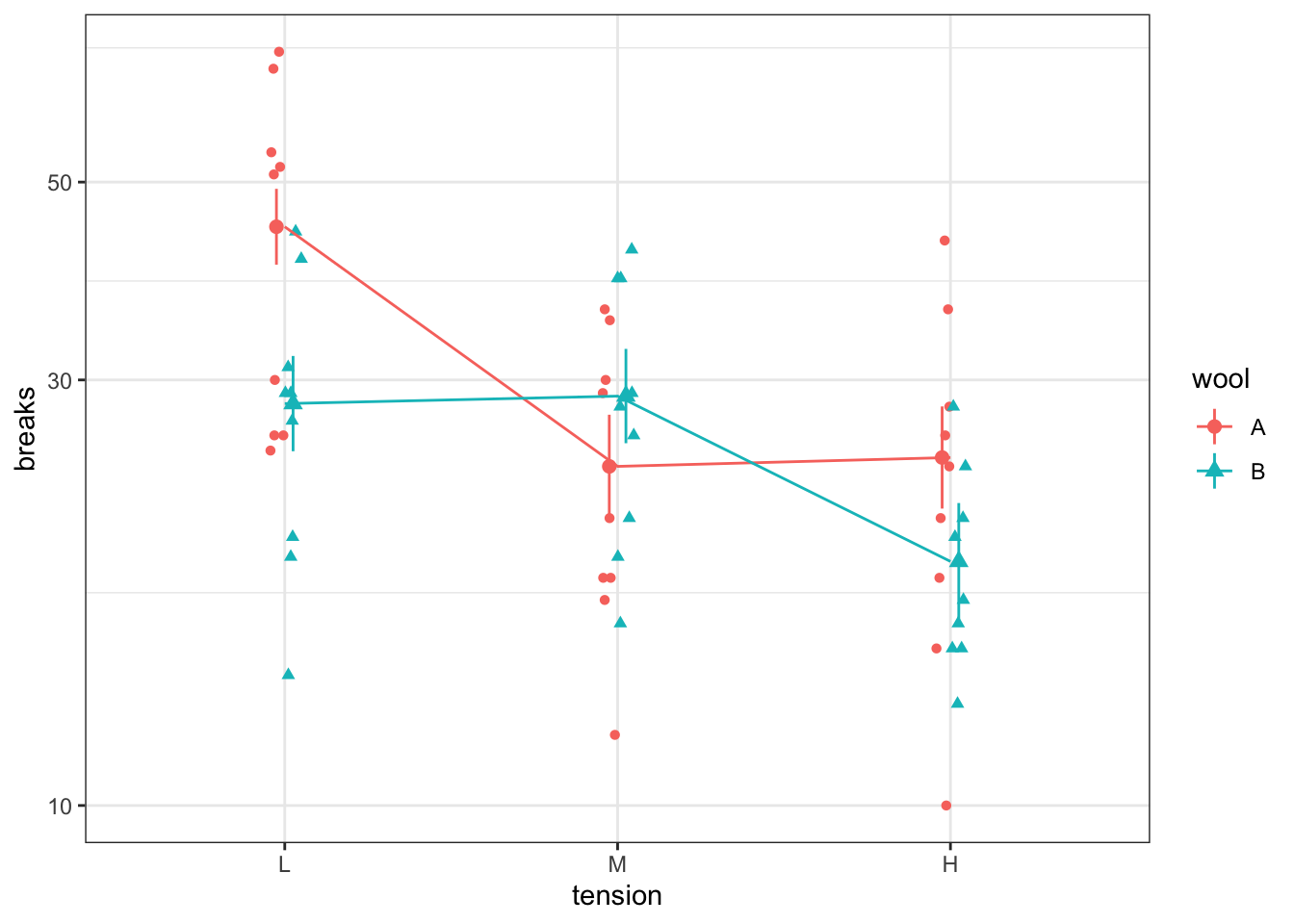
When there are two (or more) explanatory variables, we can consider a main effects model or models with interactions. The main effects model will result in parallel lines or line segments while the interaction model will result in more flexible lines or line segments. These lines will be straight when plotting the response variable on a logarithmic axis.
When counts are zero, the logarithm is undefined. Thus it is common to add 1 to all counts when plotting on a logarithmic axis.
36.1 Model
Let \(Y_i\) be the count of some phenomenon over some amount of time and/or space. The Poisson regression model assumes Assume \[
Y_i \stackrel{ind}{\sim} Po(\lambda_i), \quad
\eta_i = \log\left(\lambda_i \right) =
\beta_0 + \beta_1X_{i,1} + \cdots + \beta_{p} X_{i,p}
\] where \(Po\) designates a Poisson random variable.
If we invert, then \[
E[Y_i] = Var[Y_i]
= \lambda_i
= e^{\beta_0 + \beta_1X_{i,1} + \cdots + \beta_{p} X_{i,p}}
= e^{\beta_0}e^{\beta_1X_{i,1}}\cdots e^{\beta_p X_{i,p}}.
\] Thus, there is an exponential relationship between the explanatory variables and the expected response.
36.1.1 Assumptions
The assumptions in a Poisson regression are
observations are independent
observations have a Poisson distribution (each with its own mean)
and
the relationship between the expected response is given in the exponential expression above.
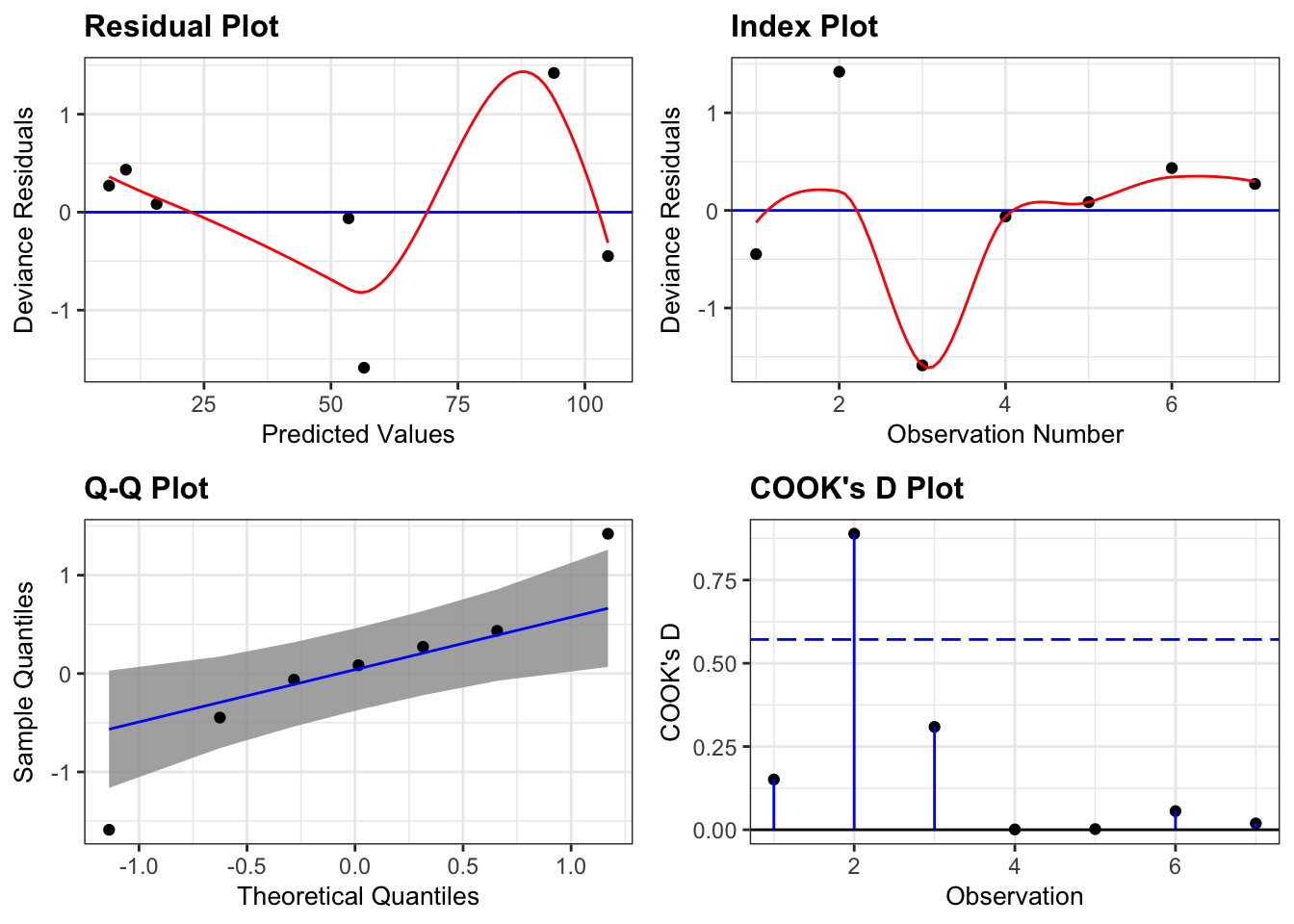
36.1.2 Diagnostics
Note that there are no errors like there were in regression. Nonetheless we do have a notion of residuals, i.e. \[
r_i
= y_i - \widehat{y}_i
= y_i - e^{\widehat\beta_0 + \widehat\beta_1X_{i,1} + \cdots + \widehat\beta_{p} X_{i,p}}
\] because each observation has a different variance (due to the mean-variance relationship) we often standardize a residual by dividing by its standard deviation, i.e. \[
r^{standardized}_i
= \frac{r_i}{\sqrt{\widehat{y}_i }}.
\] Diagnostic plots are generally produced using these residuals.
When no interactions are in the model, an exponentiated regression coefficient is the multiplicative effect on the mean of the response for a 1 unit change in the explanatory variable when all other explanatory variables are help constant. Mathematically, we can see this through \[
E[Y_i|X_{i,p}=x+1] = e^{\beta_p} \times E[Y_i|X_{i,p}=x].
\] If \(\beta_p\) is positive, then \(e^{\beta_p} > 1\) and the mean goes up. If \(\beta_p\) is negative, then \(e^{\beta_p} < 0\) and the mean goes down.
If the explanatory variable is continuous, then this creates a line with an exponential relationship. If the explanatory variable is categorical, then \(X\) is a dummy variable and this is then the multiplicative effect when going from the reference level to the new level of the categorical variable.
36.1.4 Inference
Individual regression coefficients are evaluated using \(z\)-statistics derived from the Central Limit Theorem and data asymptotics. This approach is known as a Wald test. Similarly confidence intervals and prediction intervals are constructed using the same assumptions and are thus refered to as Wald intervals.
Collections of regression coefficients are evaluated with drop-in-deviance where the residual deviances from the model with and without these terms in the model are compared with a \(\chi^2\)-test.
36.2 Continuous variable
First we will consider simple Poisson regression where there is a single continuous explanatory variable.
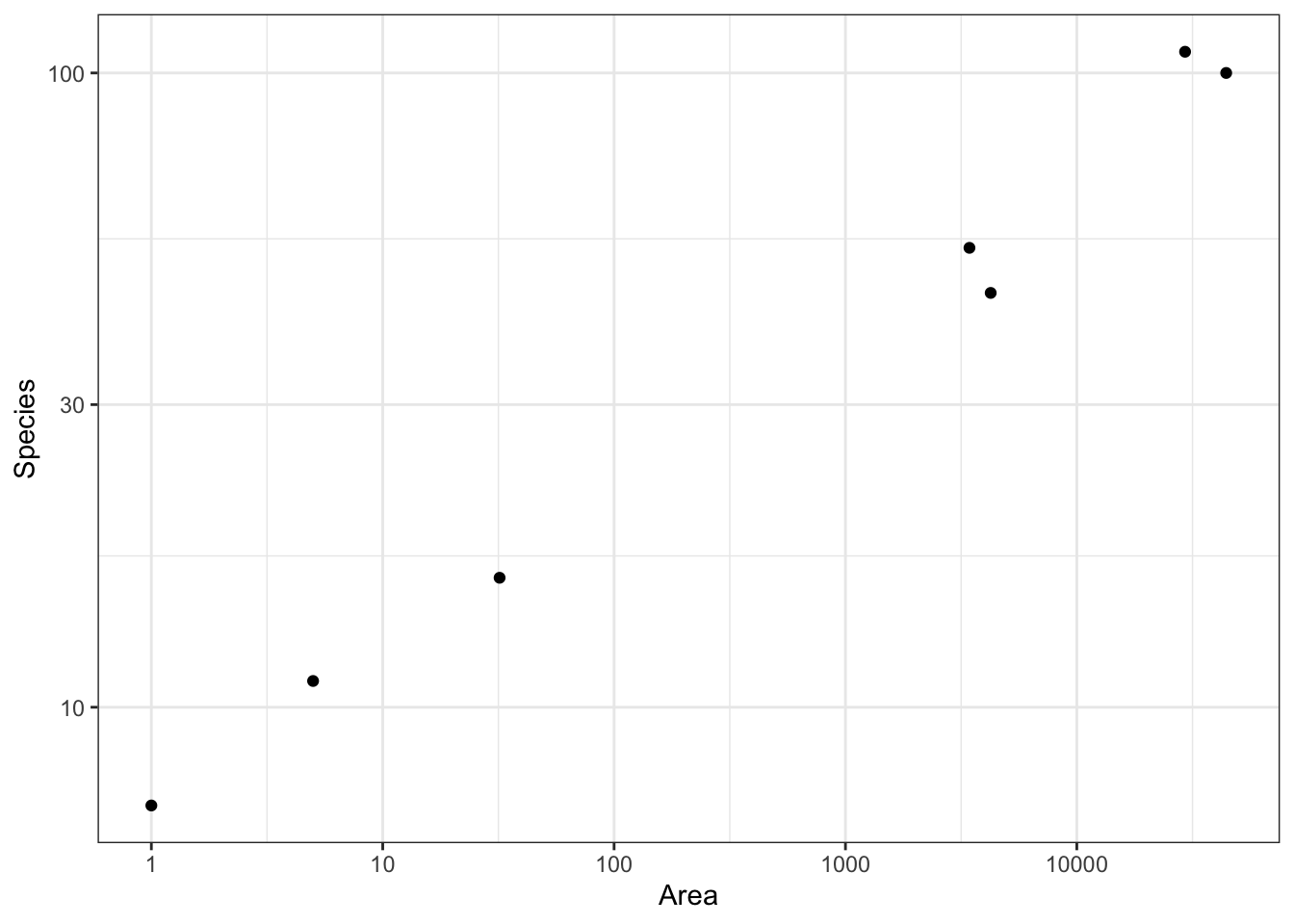
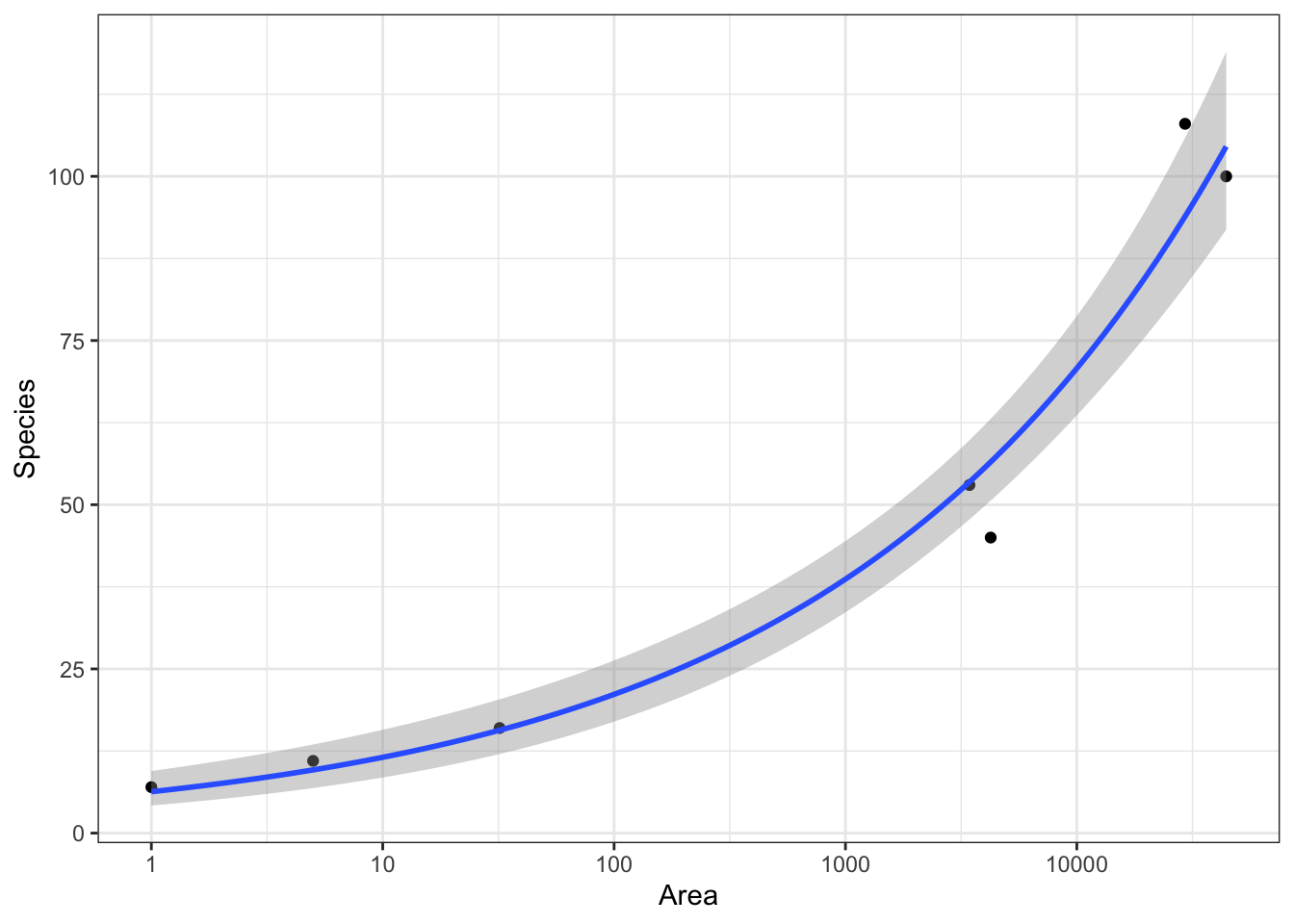
# case0801g <-ggplot(case0801,aes(x = Area,y = Species)) +geom_point() +scale_x_log10() # Through trial and error plotting # x and y on logarithmic axis looks the most linearg +scale_y_log10()
Call:
glm(formula = Species ~ log(Area), family = "poisson", data = case0801)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.84158 0.20679 8.906 <2e-16 ***
log(Area) 0.26251 0.02216 11.845 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 224.0801 on 6 degrees of freedom
Residual deviance: 5.0141 on 5 degrees of freedom
AIC: 46.119
Number of Fisher Scoring iterations: 4
# Coefficientm$coef[2]
log(Area)
0.262509
exp(m$coef[2]) # multiplicative effect of a 1 unit increase in log(Area)
# Predictionsp <-bind_cols( nd,predict(m,newdata = nd,se.fit =TRUE)|>as.data.frame() |># Manually construct confidence intervalsmutate(lwr = fit -qnorm(0.975) * se.fit,upr = fit +qnorm(0.975) * se.fit,# Exponentiate to get to response scaleFailures =exp(fit),lwr =exp(lwr),upr =exp(upr) ) )
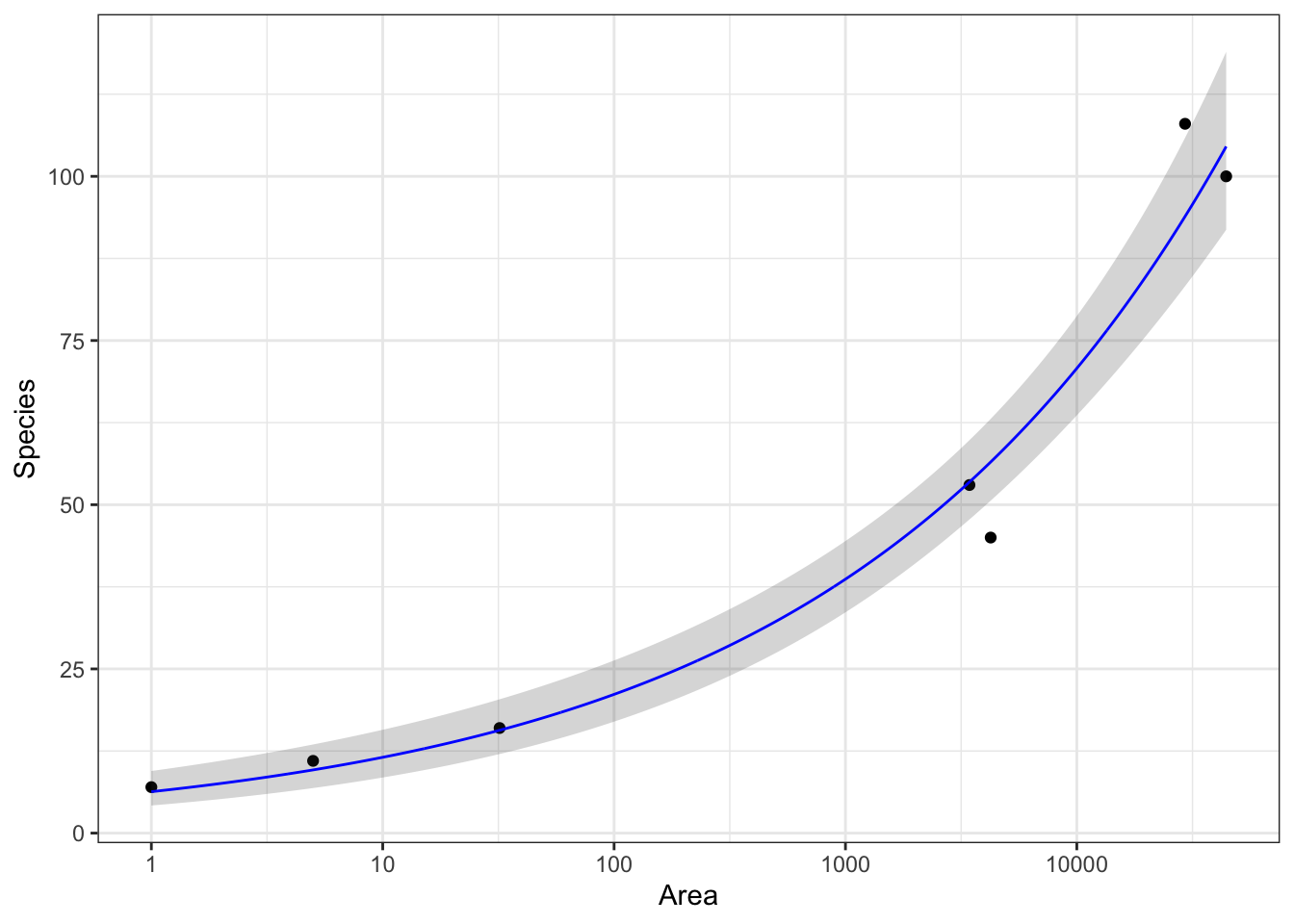
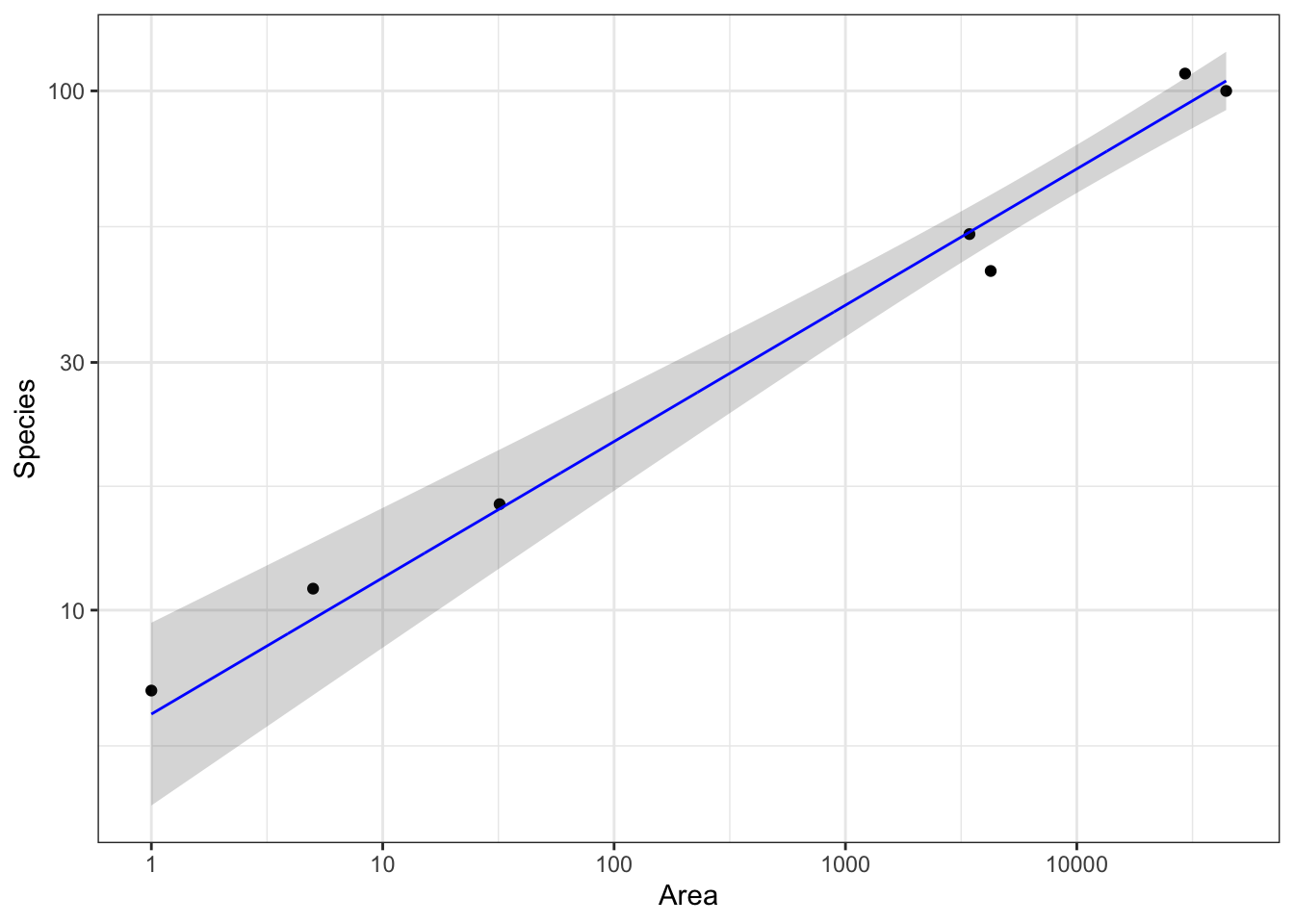
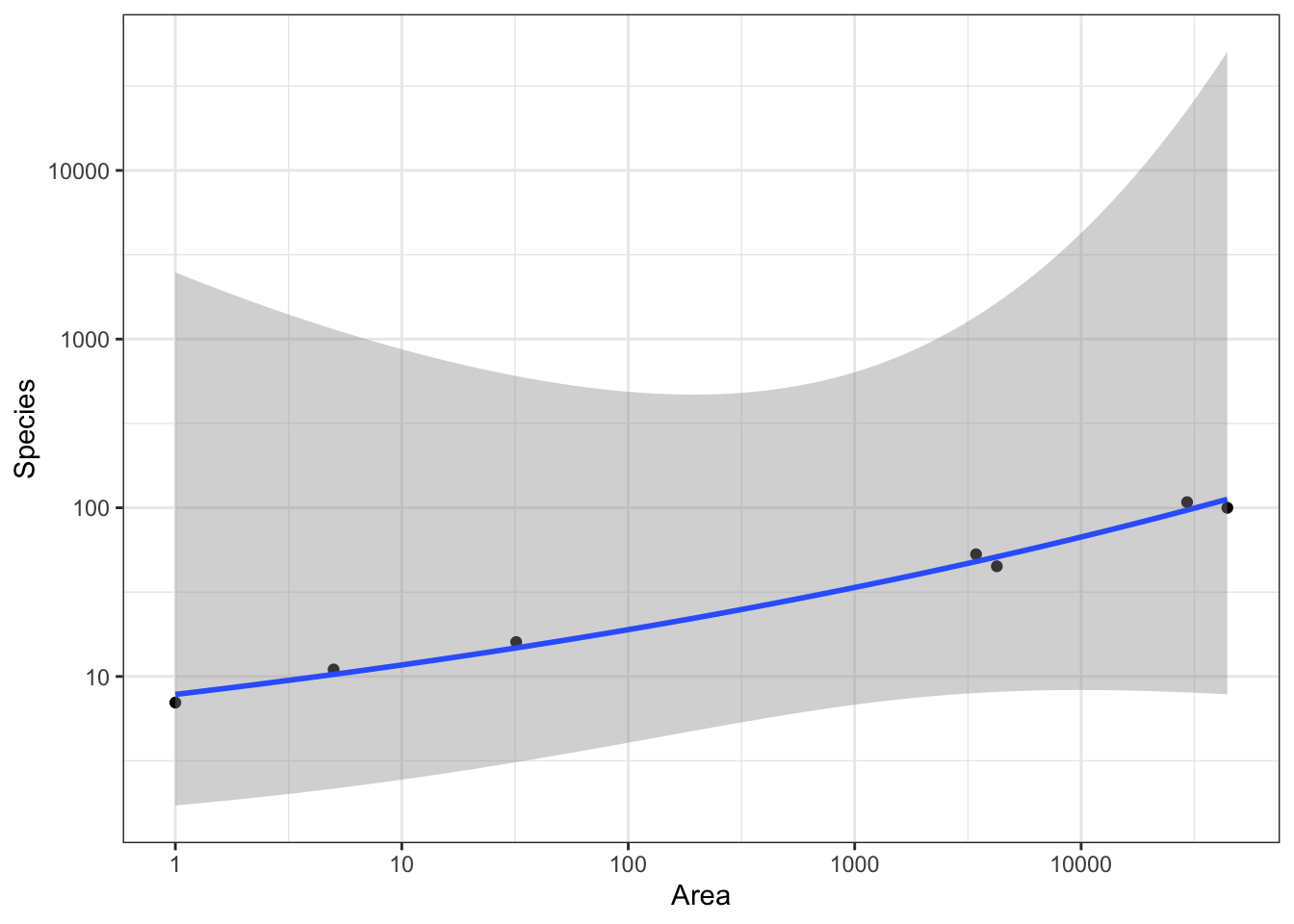
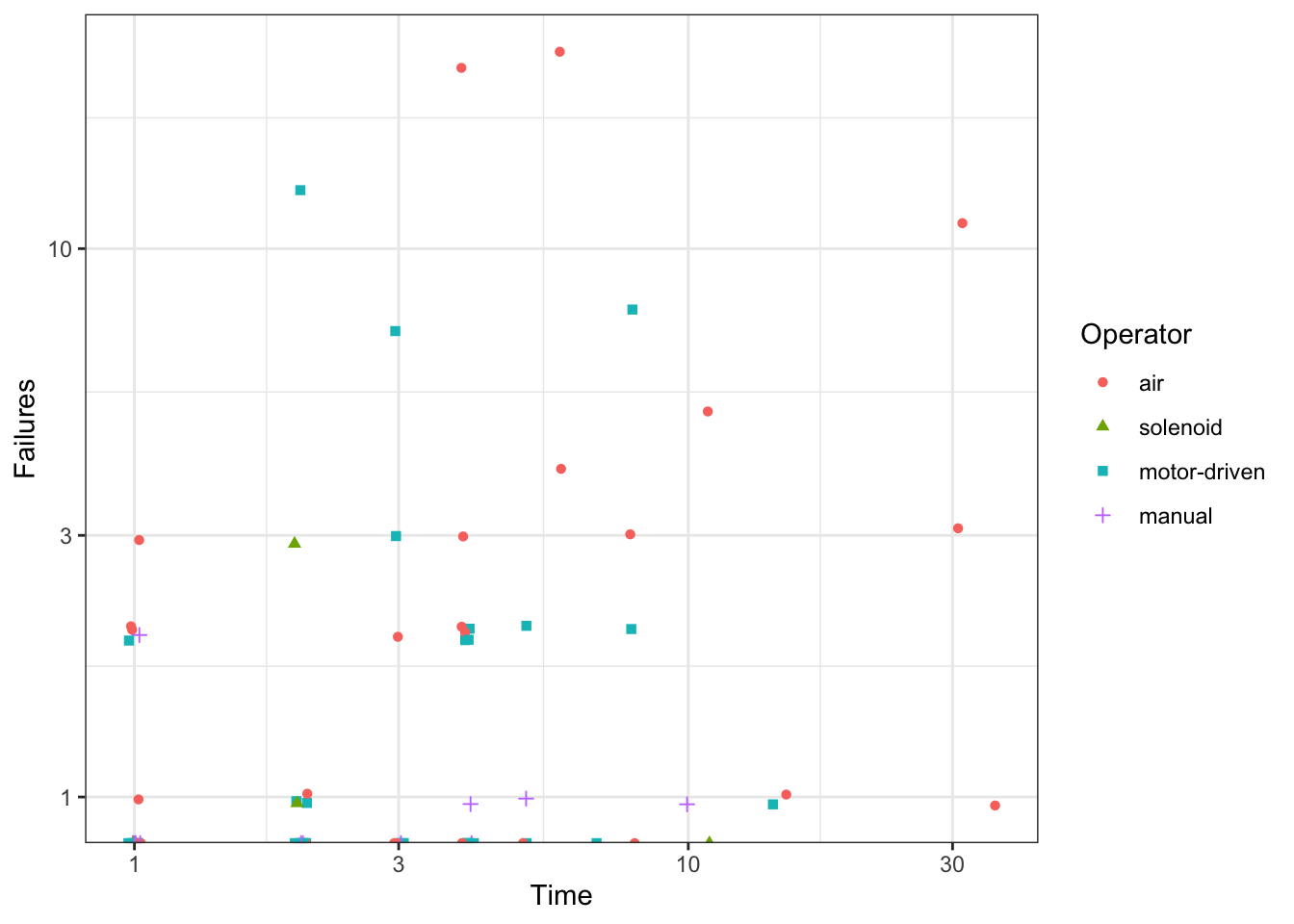
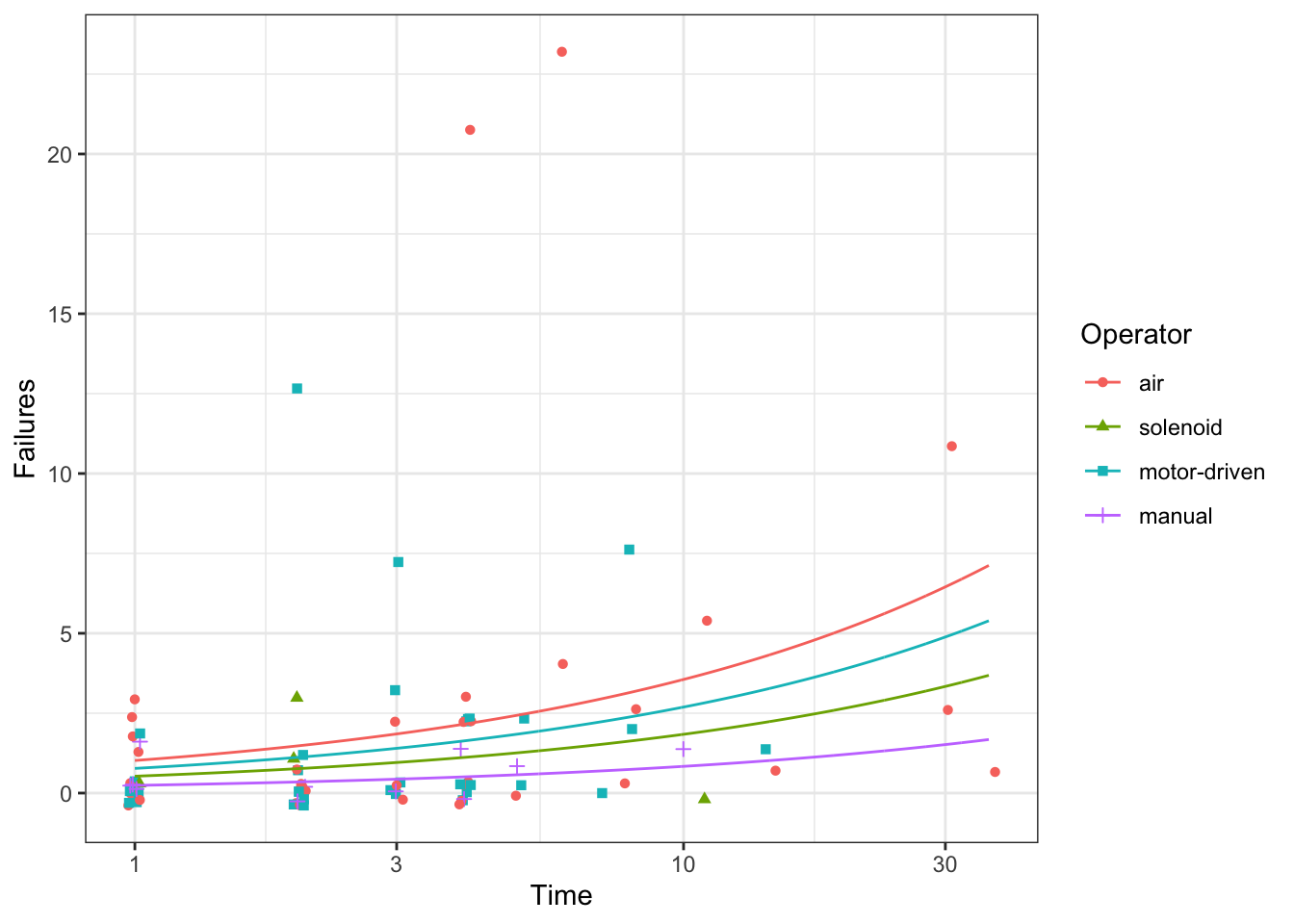
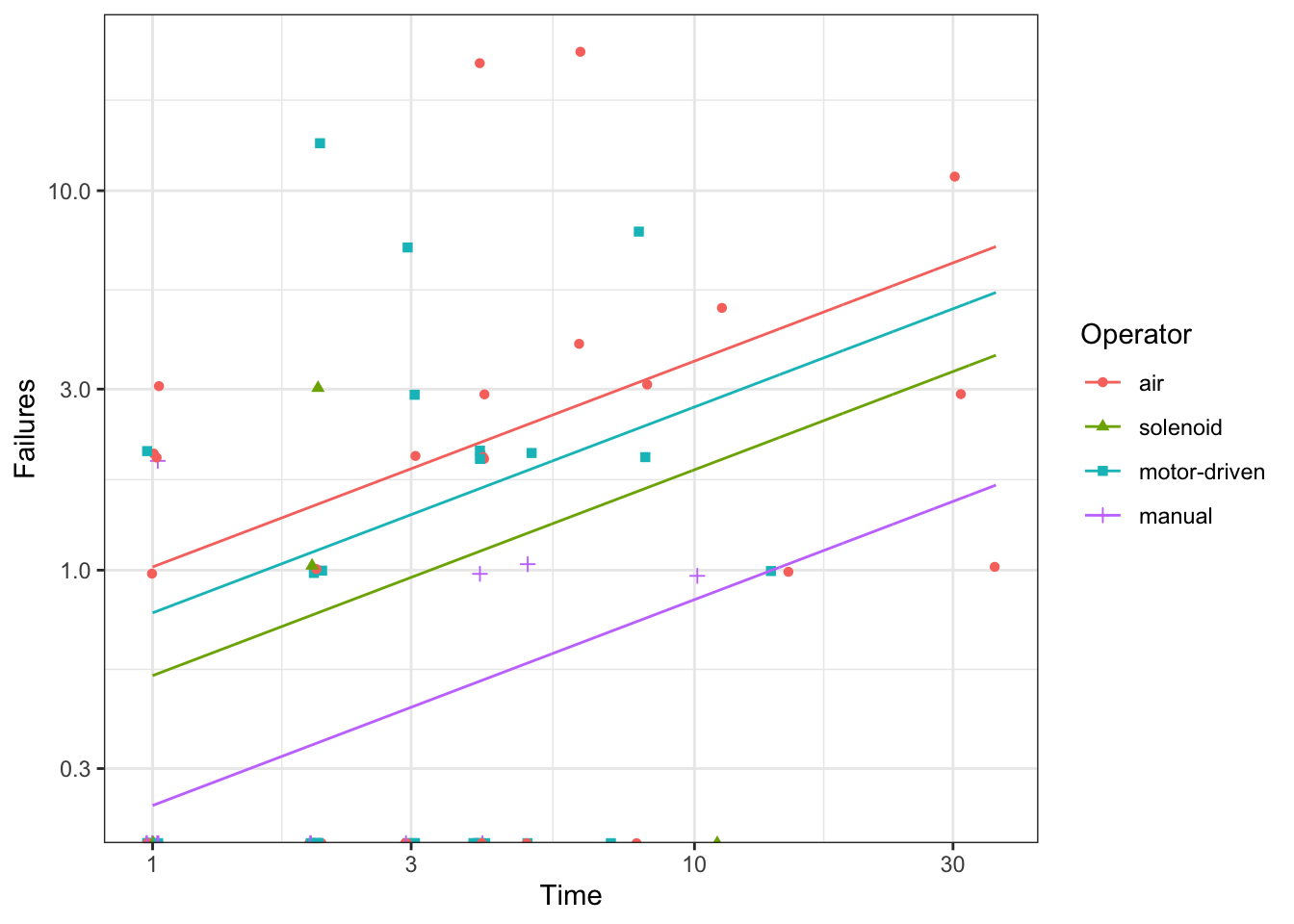
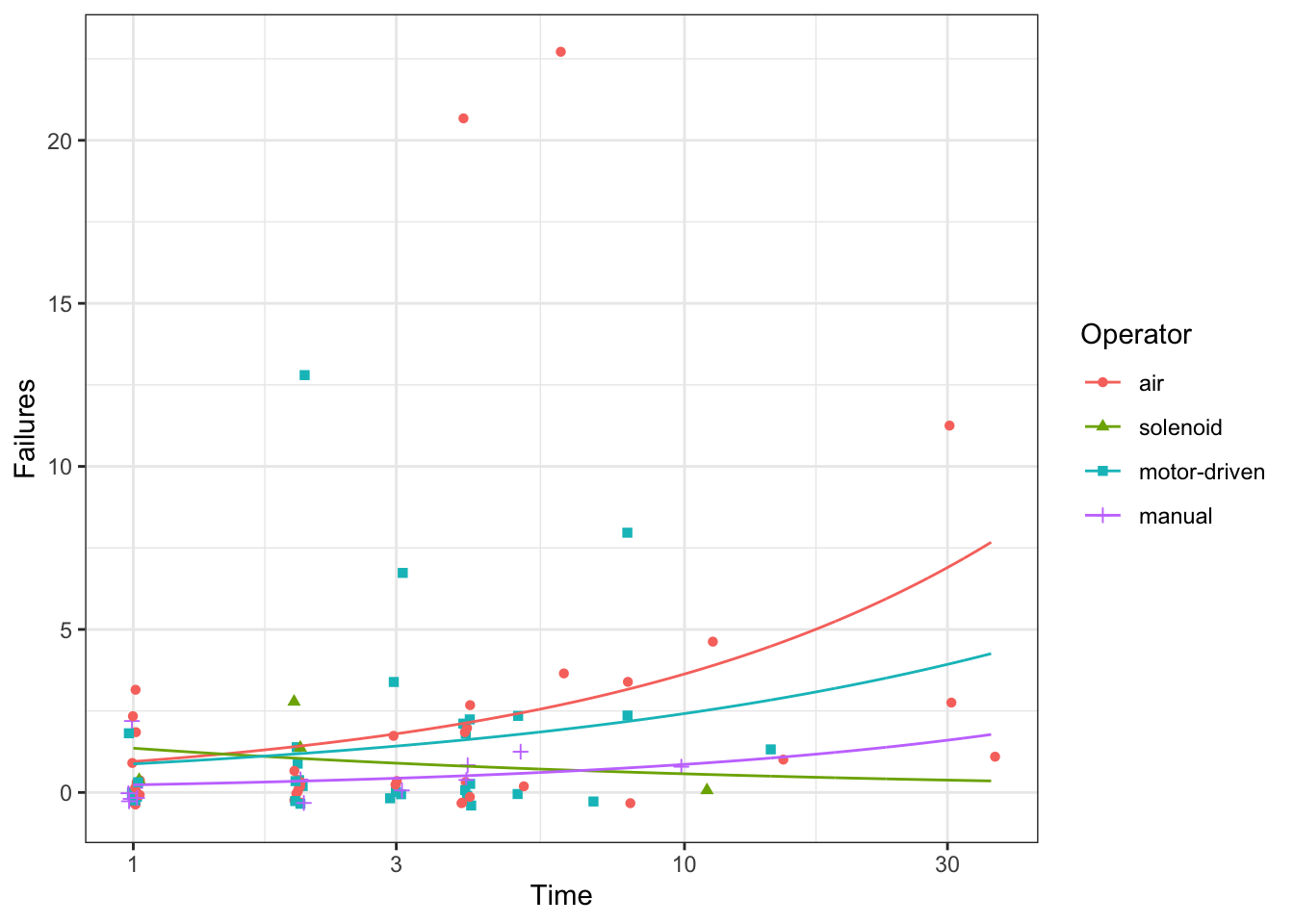
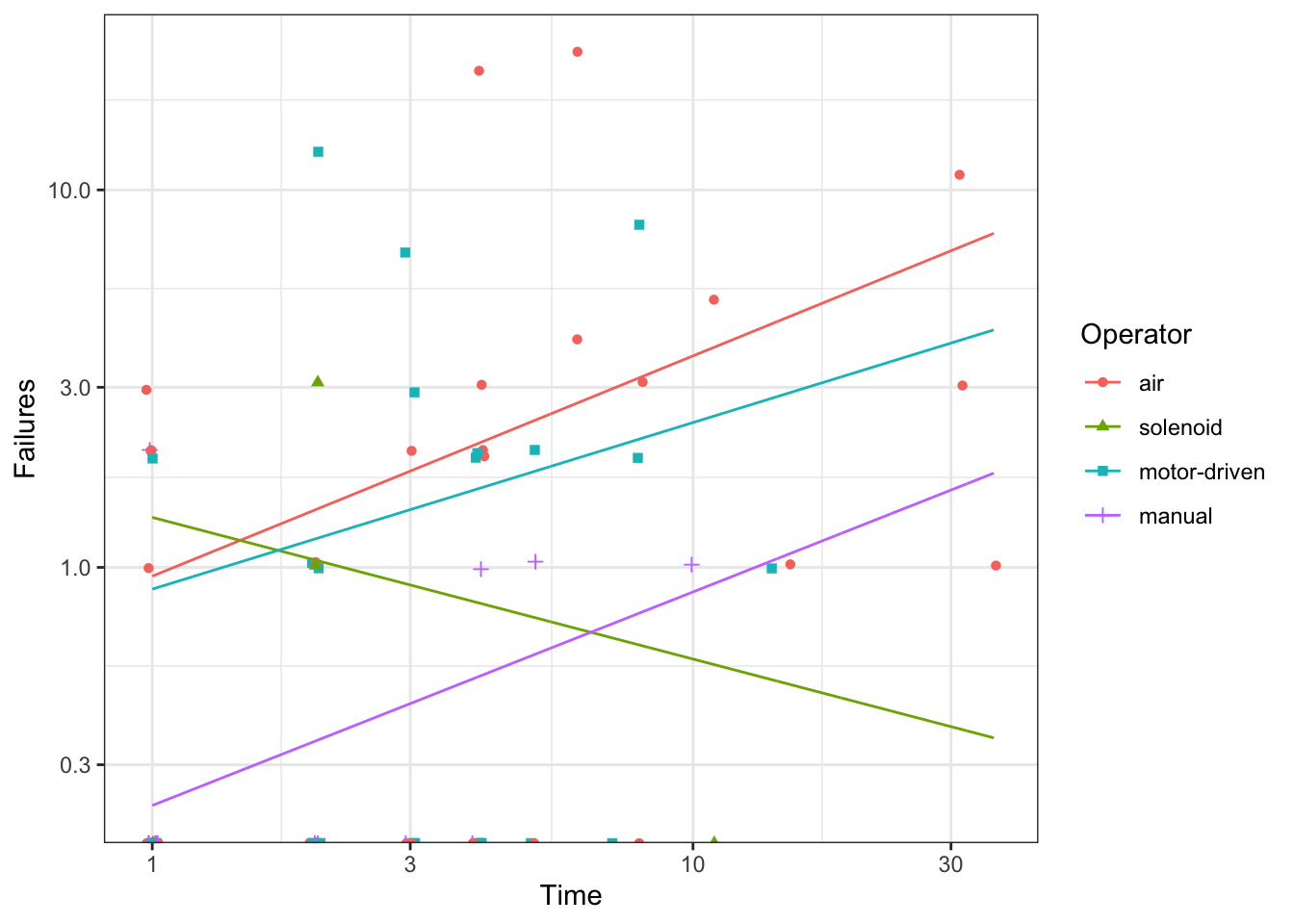
Plot model predictions
pg <- g +geom_line(data = p,mapping =aes(group = Operator ))pg
pg +scale_y_log10()
Warning in scale_y_log10(): log-10 transformation introduced infinite values.
36.6 Two continuous variables
dim(case2202)
[1] 47 4
summary(case2202)
Site Salamanders PctCover ForestAge
Min. : 1.0 Min. : 0.000 Min. : 0.00 Min. : 0.0
1st Qu.:12.5 1st Qu.: 0.000 1st Qu.:18.00 1st Qu.: 29.5
Median :24.0 Median : 1.000 Median :83.00 Median : 64.0
Mean :24.0 Mean : 2.468 Mean :58.98 Mean :168.8
3rd Qu.:35.5 3rd Qu.: 3.000 3rd Qu.:88.00 3rd Qu.:266.5
Max. :47.0 Max. :13.000 Max. :93.00 Max. :675.0
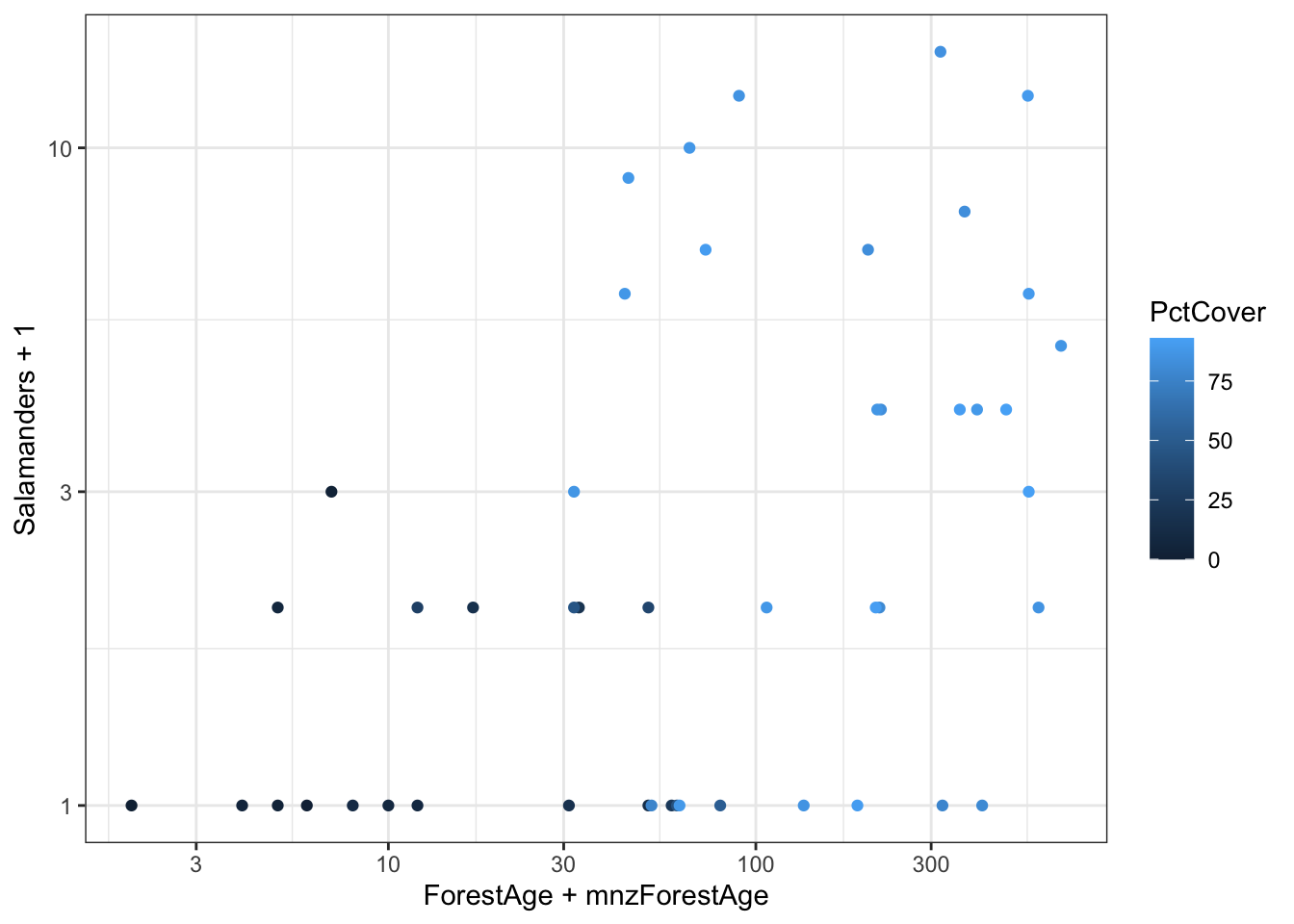
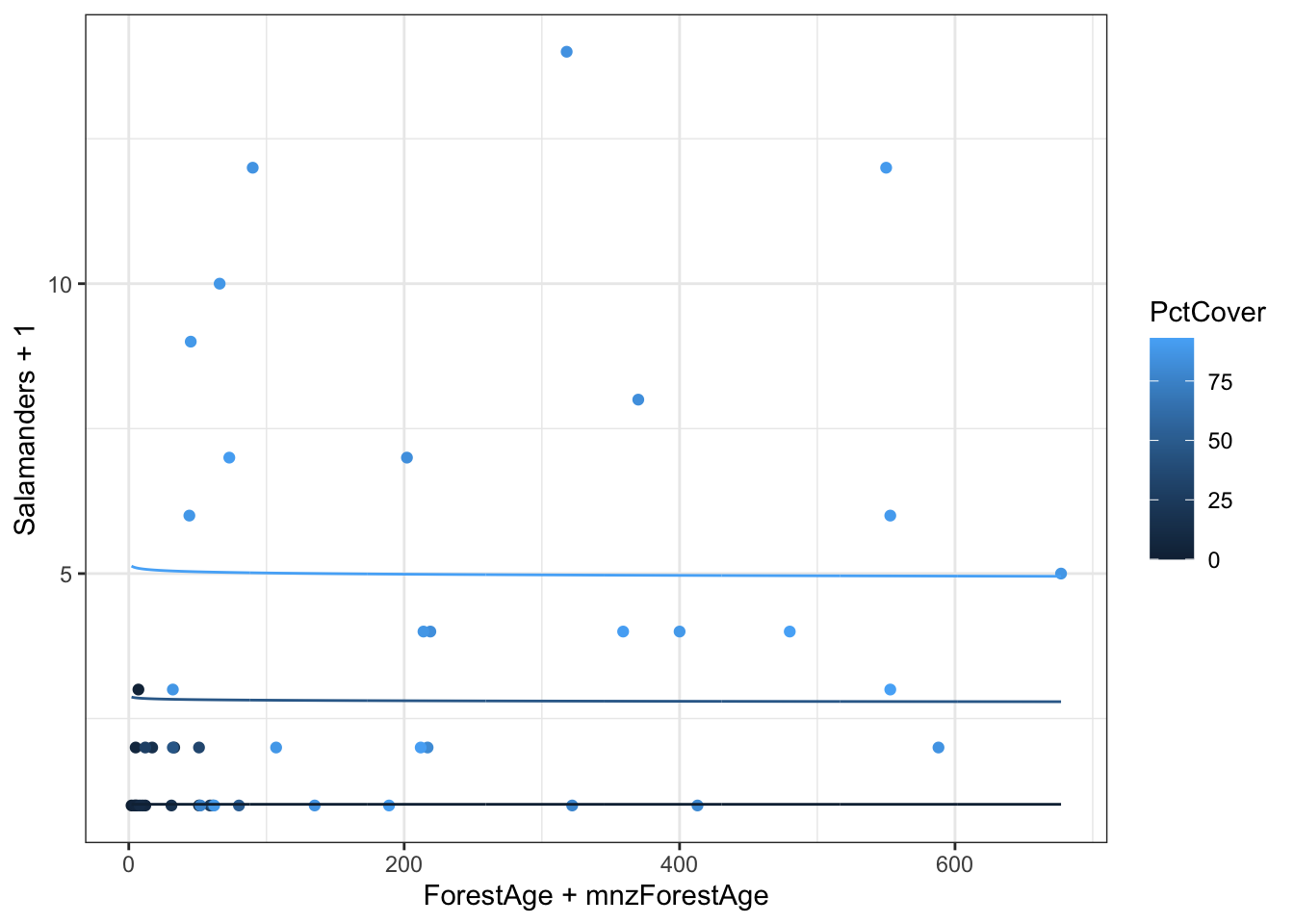
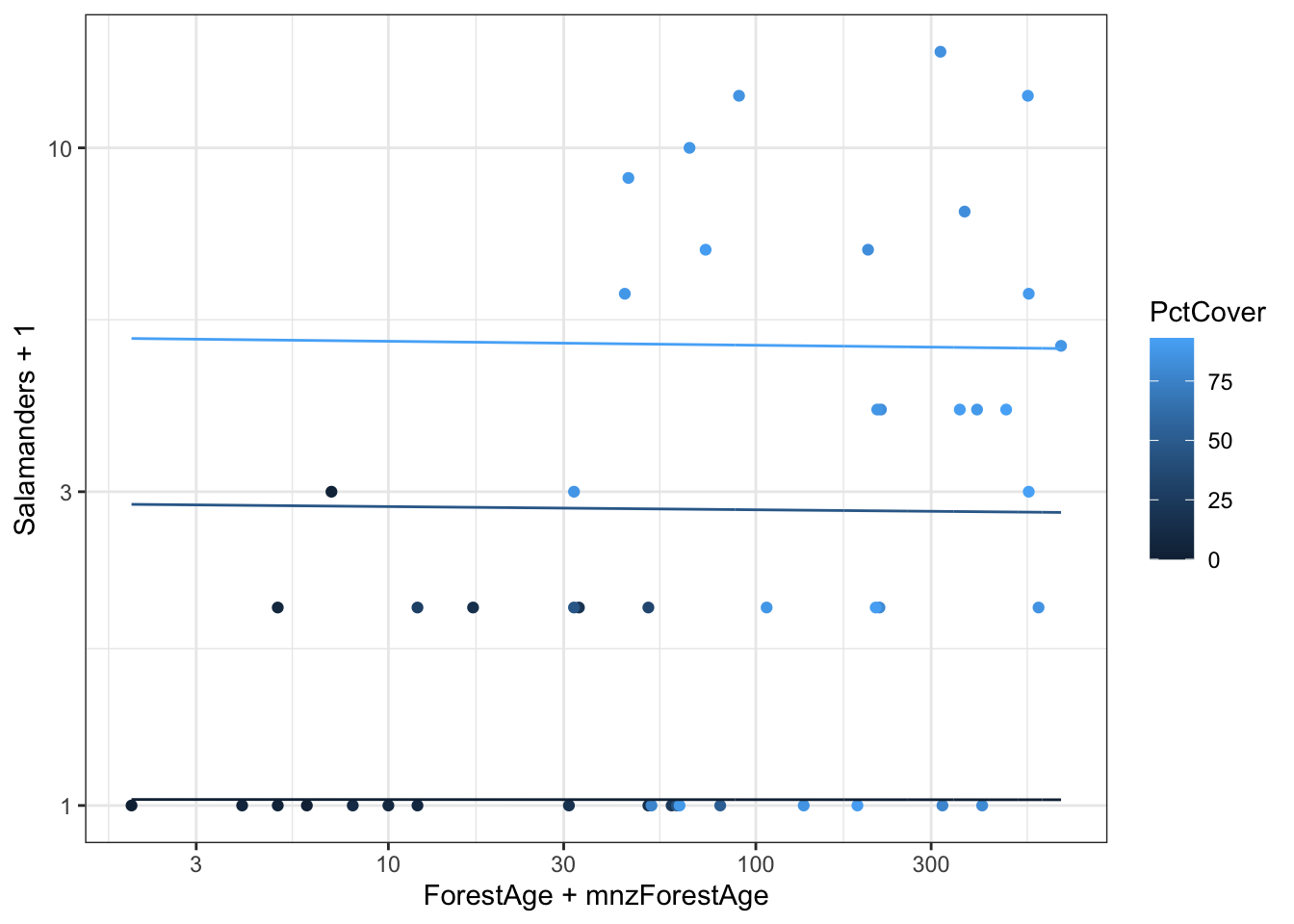
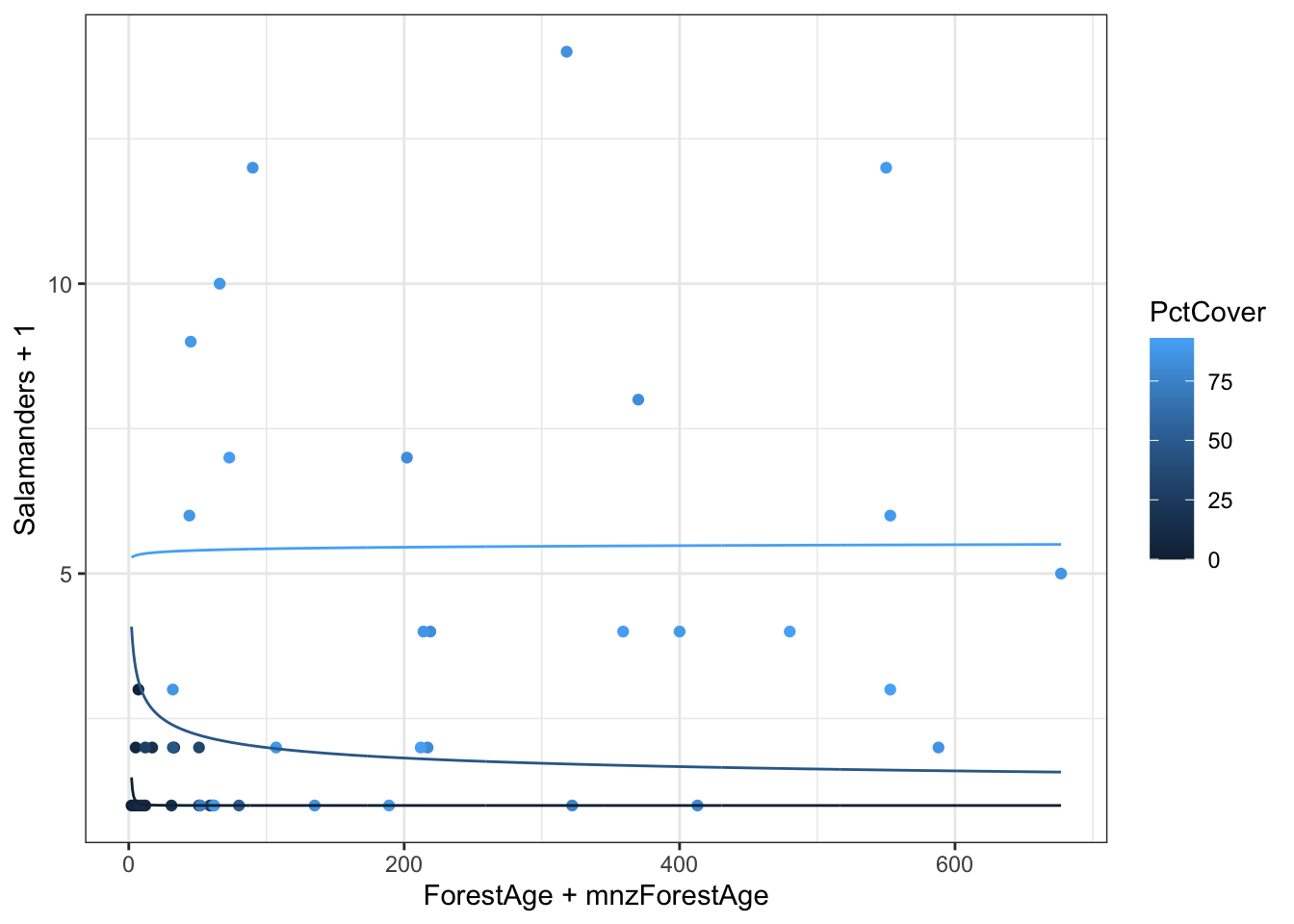
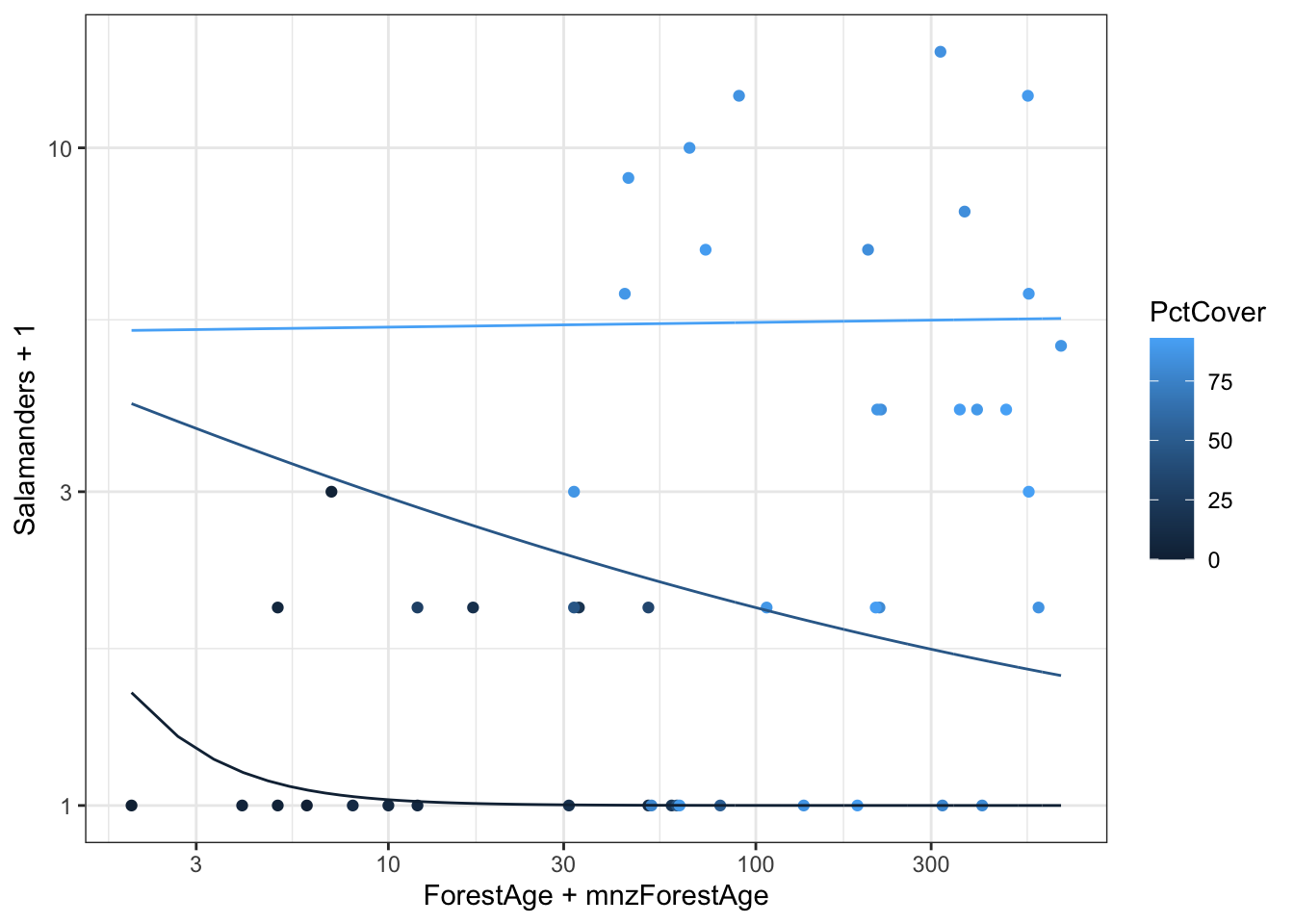
The minimum values include zero. The logarithm of zero is undefined which will create difficulties in plotting on logarithmic axes. One way to get around this is to add a small value before taking the logarithm. A common choice is to add the smallest non-zero value for that variable.
# Function to extract minimum non-zero valuemin_nonzero <-function(x) { min(x[x>0]) }# Find minimum nonzeromnzForestAge <-min_nonzero(case2202$ForestAge)mnzPctCover <-min_nonzero(case2202$PctCover)g <-ggplot(case2202,aes(x = ForestAge + mnzForestAge,y = Salamanders +1,color = PctCover)) +geom_point() g +scale_x_log10() +scale_y_log10()